逻辑回归详解(Logistic Regression)【含Java/Python代码】
逻辑回归(Logistic Regression)是一种应用非常广泛的回归方法,它使用逻辑函数为二元依赖变量的数据建模,即标签或者依赖变量只有0和1两种情况,因此可以作为二分类的模型使用。同时,逻辑回归也可以看做是没有隐藏层且激活函数为Sigmoid函数的神经网络。它是很多模型的基础。
我们以iris数据集为例,总共有5列,前四列是花的属性,分别是 Sepal.Length(花萼长度); Sepal.Width(花萼宽度); Petal.Length(花瓣长度); Petal.Width(花瓣宽度);
最后一列是花的种类,分别是 Iris Setosa(山鸢尾) - 0; Iris Versicolour(杂色鸢尾) - 1; Iris Virginica(维吉尼亚鸢尾) - 2;
样例如下(我们已经最后一列转换成了0和1形式,为了便于分析逻辑回归,我们去掉了2这一种):
5.1,3.5,1.4,0.2,0.0
4.9,3.0,1.4,0.2,0.0
4.7,3.2,1.3,0.2,0.0
4.6,3.1,1.5,0.2,0.0
5.0,3.3,1.4,0.2,0.0
7.0,3.2,4.7,1.4,1.0
6.4,3.2,4.5,1.5,1.0
6.9,3.1,4.9,1.5,1.0
5.5,2.3,4.0,1.3,1.0
6.5,2.8,4.6,1.5,1.0
为了根据花的形状来预测花的种类,我们可以使用逻辑回归来判断。
以二维数据为例,逻辑回归的目的就是找出一条直线,将二维平面上的点分成两部分:
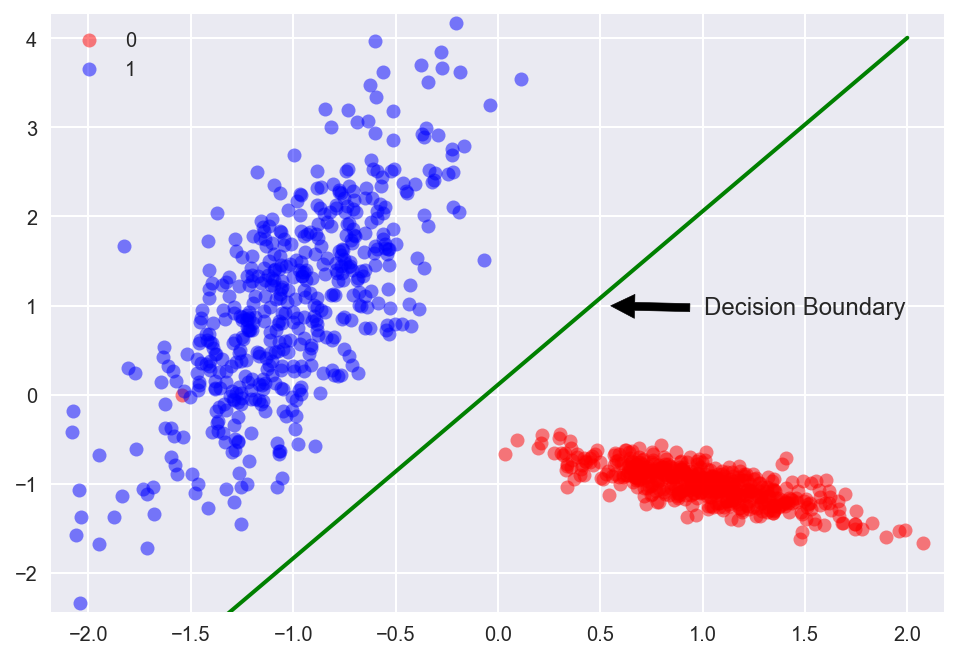
直线的形式就是:
y = wx + b
扩展到多维数据之后,假设我们有一组数据$\bold{X}=\{\bold{x_1},\cdots,\bold{x_m}\}$,它总共有$m$个,每一个数据包含了$n$个维度,即$\bold{x_i}=\{x_{i1},\cdots,x_{in}\}$,每一个数据都对应一个标签,所有的标签集合为$\bold{Y}=\{y_1,\cdots, y_m\}$。也就是说,上述数据形式可以表示如下:
[\bold{X,Y}] = \begin{bmatrix}
\bold{x_{1}},y_1 \\
\cdots,\cdots \\
\bold{x_{i}},y_i \\
\cdots,\cdots \\
\bold{x_{m}},y_m
\end{bmatrix}
=
\begin{bmatrix}
x_{11},\cdots,x_{1n},y_1 \\
\cdots,\cdots,\cdots,\cdots \\
x_{i1},\cdots,x_{in},y_i \\
\cdots,\cdots,\cdots,\cdots \\
x_{m1},\cdots,x_{mn},y_m
\end{bmatrix}
那么,逻辑回归的形式如下:
\hat{\bold{Y}} = \bold{w}^T\bold{X}+\bold{b}
这里的符号都加粗了,因此都是向量的形式。其中$\hat{\bold{Y}}$表示预测结果,维度是$(1,m)$,$\bold{X}$表示所有数据,其维度是$(n,m)$,$\bold{w}$是回归系数(regression coefficient),其维度是$(n,1)$,$\bold{w}^T$是$\bold{w}$的转置,因此,$\bold{w}^T\bold{X}$的结果的维度就是$(1,m)$,$\bold{b}$表示偏差,其维度也是$(1,m)$。
逻辑回归的训练就是利用已有的有标签的数据,求出$\bold{w}$和$\bold{b}$,并最好地拟合已有的数据,即:
\hat{y} = \bold{w^Tx} + \bold{b}
这里就是针对一个数据的逻辑回归运算结果。由于逻辑回归的预测结果一般都要转换成0和1,因此,上述概率的形式可以增加一个Sigmoid函数得到:
\hat{y} = \delta(\bold{w^Tx} + \bold{b}) = \frac{1}{1 + e^{\bold{-(w^Tx} + \bold{b})}}
这样最终的预测结果就能转换成0-1两种值了。
逻辑回归的求解通常都是使用随机梯度下降的方法(Stochastic Gradient Descent, SGD)。
