MMLU Pro大模型评测基准介绍:MMLU的进化版本,可以更好区分大模型普遍知识和推理能力的通用评测标准
MMLU Pro的最新排行参考DataLearnerAI收集的MMLU Pro大模型排行榜信息:https://www.datalearner.com/ai-models/llm-benchmark-tests/16
大模型已经对很多行业产生了巨大的影响,如何准确评测大模型的能力和效果,已经成为业界亟待解决的关键问题。生成式AI模型,如大型语言模型(LLMs),能够生成高质量的文本、代码、图像等内容,但其评测却相对很困难。而此前很多较早的评测也很难区分当前最优模型的能力。
以MMLU评测为例,2023年3月份,GPT-4在MMLU获得了86.4分之后,将近2年后的2024年年底,业界最好的大模型在MMLU上得分也就90.5,提升十分有限。
为此,滑铁卢大学、多伦多大学和卡耐基梅隆大学的研究人员一起提出了MMLU Pro版本评测基准。该评测基准采用了更高难度、更广泛的知识内容、更好区分性问题来对当前大模型进行通用能力评测。
MMLU评测的问题
在当前的大模型评测系统中,MMLU是被最广泛采用的评测基准。MMLU(Massive Multitask Language Understanding)评测基准旨在全面衡量模型在多个不同领域中的语言理解和推理能力。该基准由华盛顿大学和斯坦福大学的研究人员提出,主要用于评估语言模型在多任务、多领域的知识推理和理解能力。MMLU包括了57个不同的任务,涵盖了多个学科和领域,任务种类繁多,涉及从基础常识推理到复杂的学术性问题。
但是MMLU评测存在很多问题,例如:
-
MMLU中的问题只有三个干扰选项。大型语言模型(LLMs)可能会利用捷径来推导出答案,而没有真正理解背后的逻辑。这可能会导致对LLMs真实性能的高估,也会导致一定程度的不稳定性。
-
MMLU中的问题大多是知识驱动的,不需要太多的推理,特别是在STEM(科学、技术、工程和数学)科目中,这降低了它的难度。实际上,大多数模型在没有“思维链”的情况下,通过“直接”答案预测实现了更好的性能[41]。
-
有一部分问题是不可回答的或者标注错误的。这种数据集噪声导致了较低的上限,目前很多前沿模型达到了这个上限。
为了解决这些问题,MMLU Pro被提出来。
MMLU Pro简介
MMLU Pro(Massive Multitask Language Understanding Pro)是一个基准测试,旨在评估大语言模型(LLMs)在各种多样化任务上的表现,类似于原始的 MMLU(Massive Multitask Language Understanding)基准测试,但在 Pro 版本中引入了一些高级特性或增强功能。
MMLU-Pro 涵盖了数学、物理、化学、法律、工程学、心理学和健康等 14 个领域,共包括超过 12,000 道问题,充分满足了广度要求。与 MMLU 基准相比,MMLU-Pro 主要在以下几个方面有所不同:
-
更多选项和干扰项:MMLU-Pro 每道题目提供 10 个选项,包含比 MMLU 多出 3 倍的干扰项。通过增加干扰项数量,降低了通过偶然猜测得到正确答案的概率,从而显著提高了基准的难度和可靠性。
-
增加大学级别难题的比例:MMLU-Pro 增加了更多挑战性的大学水平考试题目,这些问题要求大语言模型在不同领域进行深思熟虑的推理,才能得出正确答案。
-
两轮专家审查:为了减少数据集中的噪音,研究人员进行了两轮专家审查。第一轮通过专家验证,第二轮则利用最先进的大语言模型(SoTA LLMs)识别潜在的错误,并由人工注释员进行更有针对性的验证。
MMLU Pro的实测表现
研究人员一开始就对MMLU Pro做了测试,他们评估了50多个大语言模型,包括开源和闭源模型,如GPT-4o、Claude-3-Opus、Gemini、LLaMA-3和Phi-3。
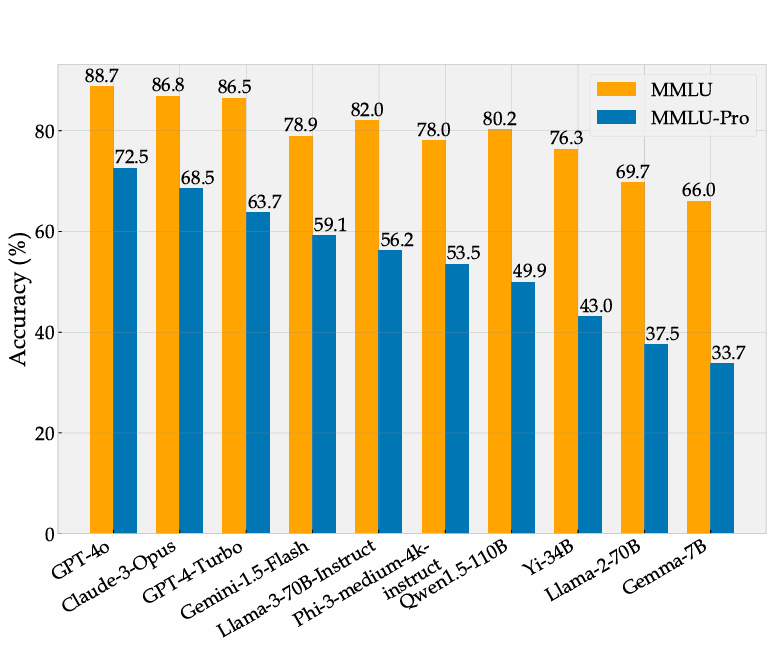
结果总结如下:
-
MMLU-Pro对最强的模型也提出了显著的挑战:即使对于最领先的模型GPT-4o,也仅仅达到72.6%的准确率,而GPT-4-Turbo的准确率为 63.7%,表明还有很大的改进空间。
-
MMLU-Pro在区分模型之间的细微差异方面比MMLU更具辨别力。例如,GPT-4o和GPT-4-Turbo在MMLU上的差距为 1%,但在MMLU-Pro上达到了 9%。这种辨别性使得 MMLU-Pro成为更合适的基准测试。
-
先进的开源模型表现尚可:如Llama-3-70B-Instruct和DeepSeek-V2-Chat,虽然尚未达到 GPT-4o 和 Claude-3-Opus 等领先闭源模型的水平,但其表现已经接近 Claude-3-Sonnet。
-
MMLU-Pro 需要链式推理(CoT)才能取得良好的结果:例如,CoT可以使GPT-4o的表现提升19%。相比之下,在MMLU上,CoT实际上会降低模型的表现。这反映了在MMLU-Pro上进行深思熟虑的推理是必要的,而在基于知识驱动的MMLU问题中并不需要如此。
-
对120个GPT-4o错误案例的分析:这些案例分析揭示了大模型错误的主要原因:39% 的错误源自推理过程中的缺陷,35% 来自缺乏特定领域的专业知识,另外 12% 来自计算错误。这些结果突显了 MMLU-Pro 基准测试的难度,并表明了进一步研究和模型改进的方向。
