百度在周末发布了2个新一代文心一言大模型,分别是没有推理能力的ERNIE 4.5以及有推理能力的ERNIE X1,即日起可以免费使用
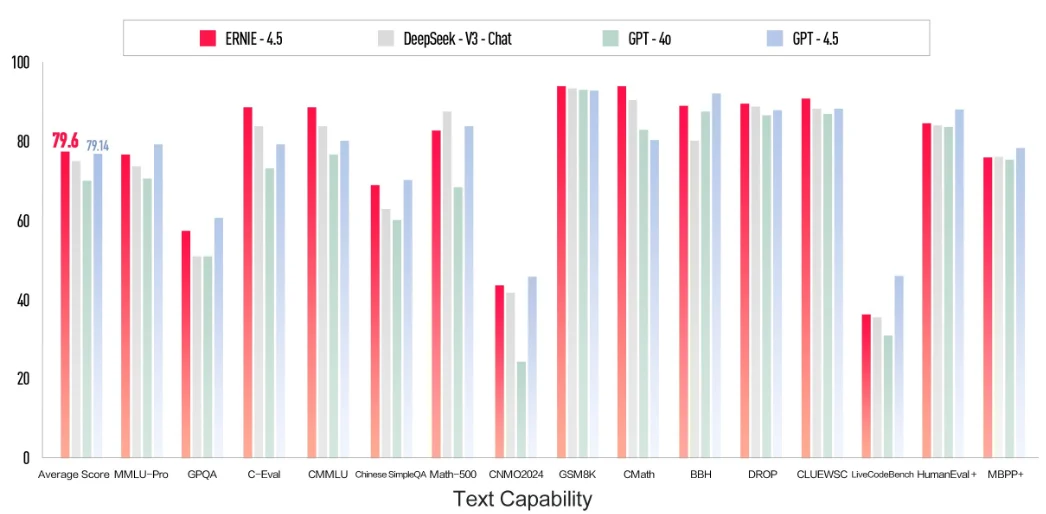
3月16日,百度宣布推出两款新一代文心大模型——ERNIE 4.5与ERNIE X1,并提前向公众免费开放其智能对话平台“文心一言”(ERNIE Bot)。官方宣称,这两款模型的能力均超过了GPT-4o,但是价格只有GPT-4o的1%,且是DeepSeek的一半。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
3月16日,百度宣布推出两款新一代文心大模型——ERNIE 4.5与ERNIE X1,并提前向公众免费开放其智能对话平台“文心一言”(ERNIE Bot)。官方宣称,这两款模型的能力均超过了GPT-4o,但是价格只有GPT-4o的1%,且是DeepSeek的一半。

今天下午,百度发布了文心一言大模型。这是一次对百度来说十分重要的发布会,也几乎是国内当前唯一一家将大模型作为一种大规模的服务推向市场的公司。本文主要介绍刚刚发布的文心一眼相关的能力。