
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




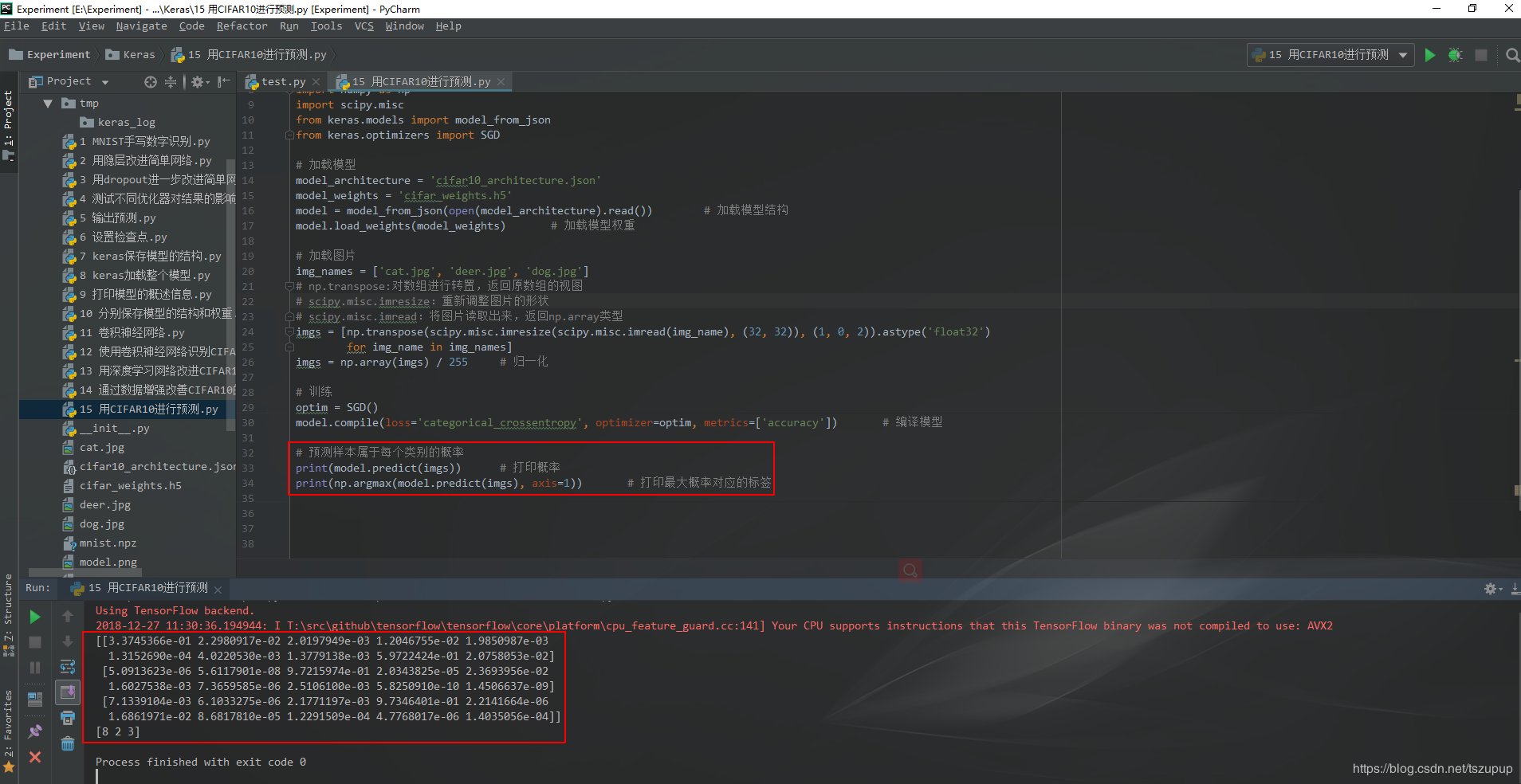
Keras中predict()方法和predict_classes()方法的区别
tf.nn.softmax_cross_entropy_with_logits函数
Microsoft Visual C++ 14.0 is required
本篇博客主要讲解如何从给定参数的的正态分布/均匀分布中生成随机数以及如何以给定概率从数字列表抽取某数字或从区间列表的某一区间内生成随机数,按照内容将博客分为3部分,并附上代码。
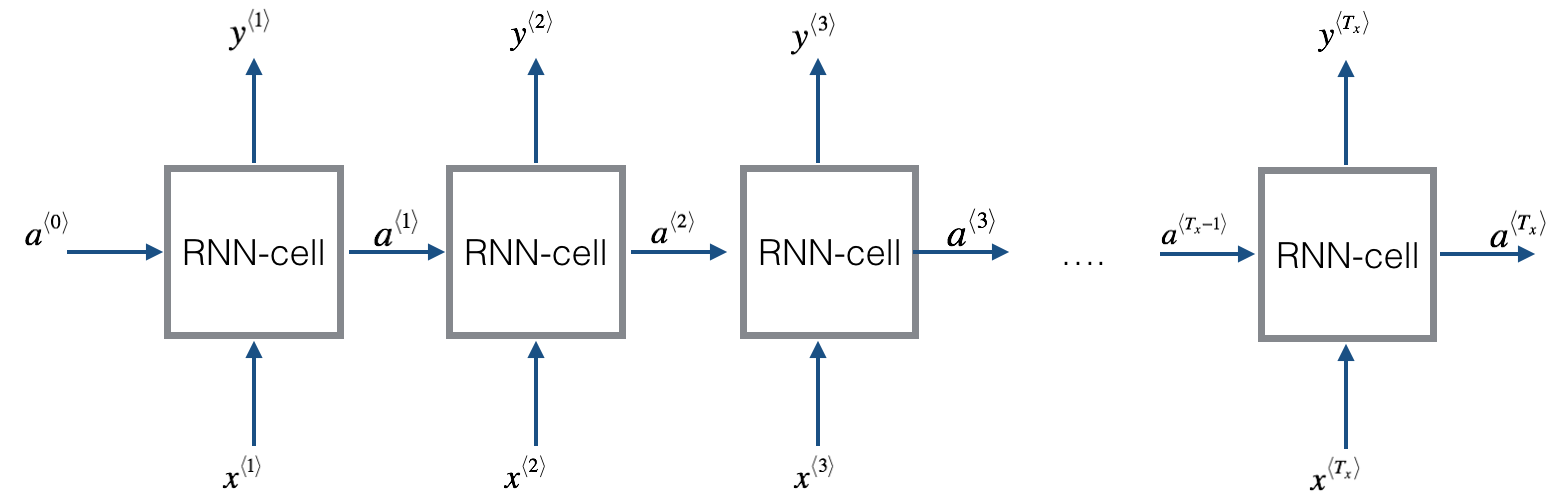
之前面的博客中,我们已经描述了基本的RNN模型。但是基本的RNN模型有一些缺点难以克服。其中梯度消失问题(Vanishing Gradients)最难以解决。为了解决这个问题,GRU(Gated Recurrent Unit)神经网络应运而生。本篇博客将描述GRU神经网络的工作原理。GRU主要思想来自下面两篇论文:
在前面的博客中,我们已经介绍了基本的RNN模型和GRU深度学习网络,在这篇博客中,我们将介绍LSTM模型,LSTM全称是Long Short-Time Memory,也是RNN模型的一种。

使用预训练模型处理NLP任务是目前深度学习中一个非常火热的领域。本文总结了8个顶级的预训练模型,并提供了每个模型相关的资源(包括官方文档、Github代码和别人已经基于这些模型预训练好的模型等)。
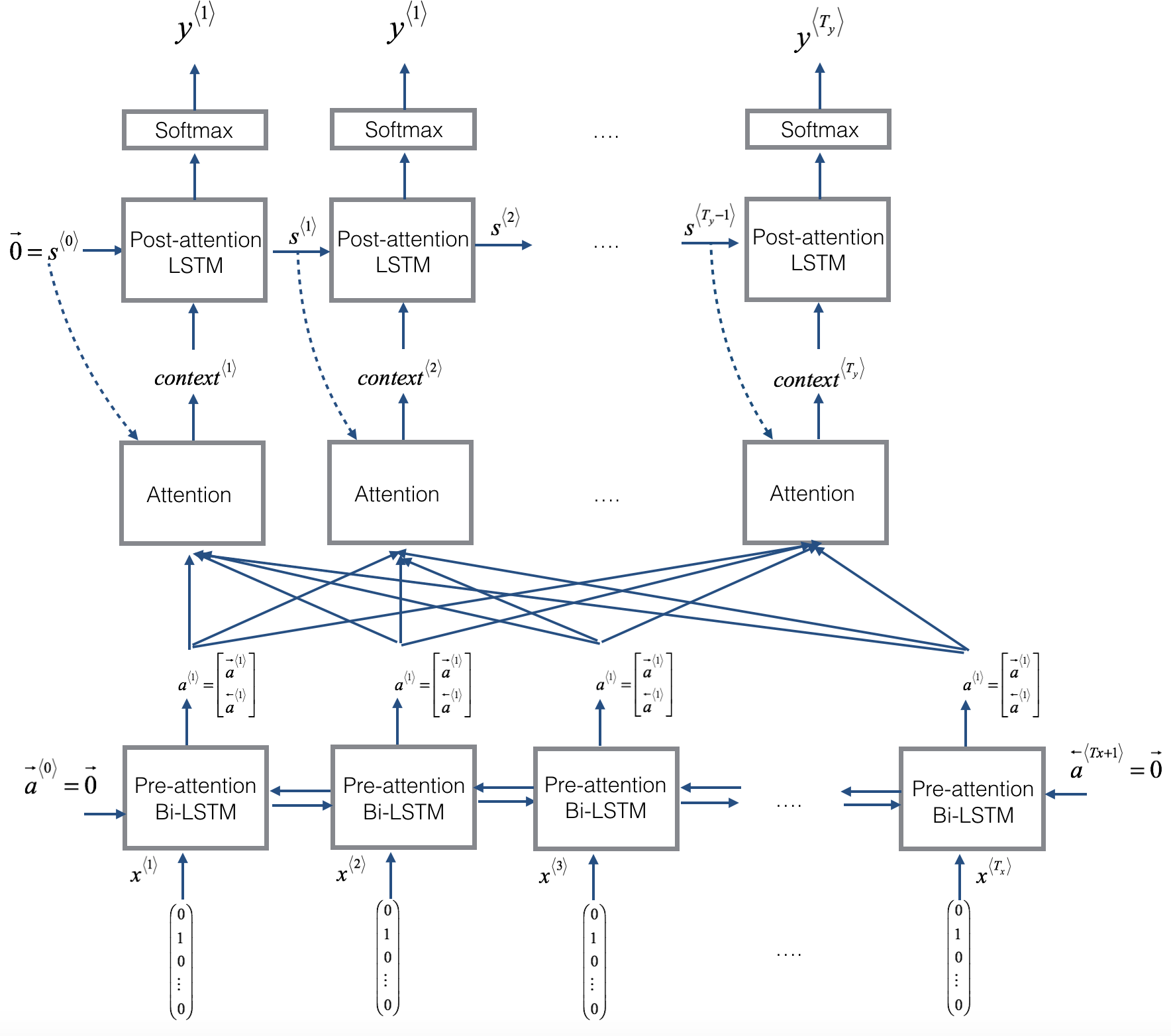
Encoder-Decoder的深度学习架构是目前非常流行的神经网络架构,在许多的任务上都取得了很好的成绩。在之前的博客中,我们也详细介绍了该架构(参见深度学习之Encoder-Decoder架构)。本篇博客将详细讲述Attention机制。

深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。