
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~





OpenAI在发布了多模态的GPT-4V(GPT-4 with Vision)的接口,可以实现图像理解的功能(`Image-to-Text`)。这是OpenAI的第一个多模态接口,在以前的接口中,OpenAI都是文本大模型,相关的费用计算都是按照输入输出的tokens计算,虽然与一个单词多少钱有一点差异,但是也算直观。而GPT-4V是一个图像理解的接口,这里的费用计算不像文本的tokens那么直观,那么这个接口的费用计算逻辑是什么?这个计算逻辑透露了什么样的模型架构信息?本文将介绍这个问题。
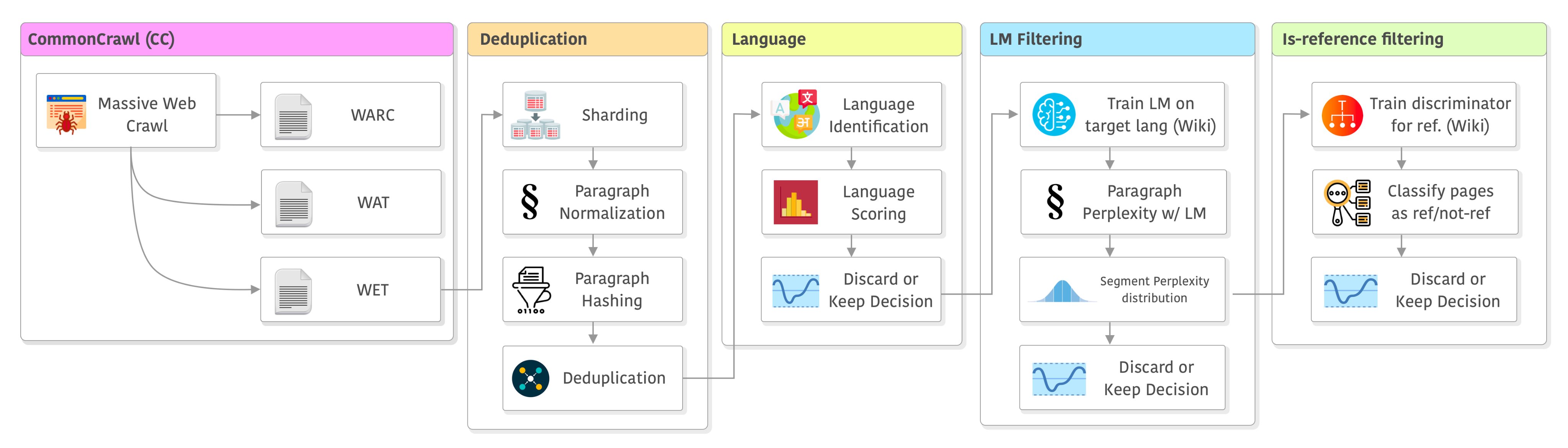
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。

LLaMA是由Meta开源的一个大语言模型,是最近几个月一系列开源模型的基础模型。包括著名的vicuna系列、LongChat系列等都是基于该模型微调得到。可以说,LLaMA的开源促进了大模型在开源界繁荣发展。而刚刚,微软官方宣布Azure上架LLaMA2模型!这意味着LLaMA2正式发布!
tf.nn.softmax_cross_entropy_with_logits函数

M3系列芯片是苹果最新发布的芯片。也是当前苹果性能最好的芯片。由于苹果的统一内存架构以及它的超大内存,此前很多人发现可以使用苹果的电脑来运行大语言模型。尽管它的运行速度不如英伟达最先进的显卡,但是由于超大的内存(显存),它可以载入非常大规模的模型。而此次的M3芯片效果如何,本文做一个简单的分析。
广告分配问题属于运筹中的优化问题。一般情况下,我们期望有个最大化收益,但同时需要保证合约的完成。因此,这是一个带不等式约束的最优化问题。由于广告数量和用户数量很多,因此,求解的难度很高。在这篇文章中,作者推导了原问题的拉格朗日函数的系数之间的关系,大大降低了求解的难度。这里将简要介绍原理和推导过程。
本文是Steffen Rendle的Pairwise Interaction Tensor Factorization for Personalized Tag Recommendation的译文。
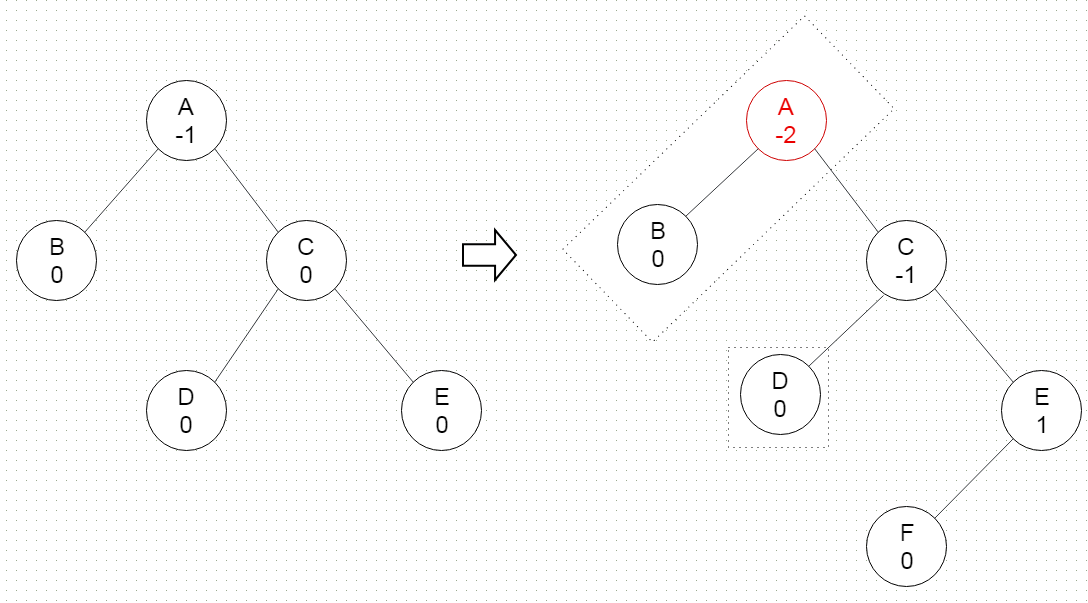
在前面的内容中,我们已经介绍了平衡二叉树。其中提到了AVL树,这是一种非常著名的平衡二叉树。这是第一个发明类似自平衡机制的二叉树数据结构。在AVL树中,任何节点的两个子树的高度最多相差一个。如果在任何时候它们相差多于一个,则重新平衡以恢复此属性。
Android是基于Linux的修改版本的移动操作系统。 大多数Android代码是在开源Apache许可证下发布的。本文将简单介绍Android开发入门知识。
字节对编码(Byte Pair Encoder,BPE),又叫digram coding,是一种在自然语言处理领域经常使用的数据压缩算法。在GPT系列模型中都有用到。主要是将数据中最常连续出现的字节(bytes)替换成数据中没有出现的字节的方法。该算法首先由Philip Gage在1994年提出。在这篇博客中我们将简单介绍一下这个方法。
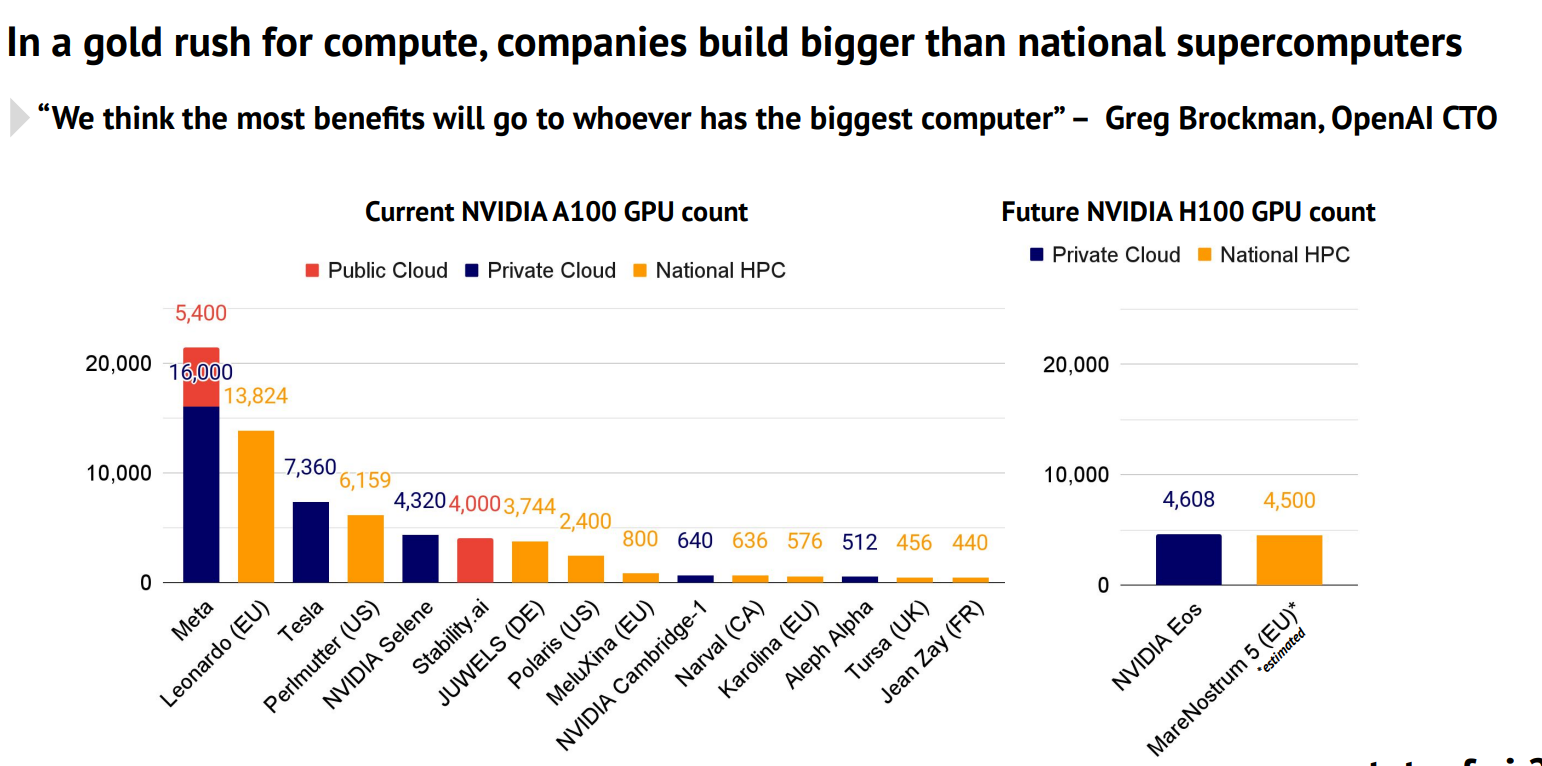
Stateof.AI上周发布了最新的AI的报告中报告了当前各大企业和机构拥有的NVIDIA A100的GPU数量。A100是目前商用的最强大的GPU,对于超级计算机、大规模AI模型的训练和推理来说都十分重要。这里透露的各大企业的GPU数量也让我们可以看到各家的竞争情况。
今日推荐
微软开源140亿参数规模的Phi-4推理版本大模型:多项评测结果超过OpenAI o1-mini,单张4090可运行,完全免费开源
Text-to-Video来临!——Meta AI发布最新的视频生成预训练模型
最新发布!基于推文(tweet)训练的NLP的Python库TweetNLP发布了!
Pika和HeyGen的开源替代品:上海人工智能实验室开源可以生成高质量最长61秒视频的LaVie文本生成视频大模型
生成对抗网络简介(包含TensorFlow代码示例)【翻译】
流浪地球2的数字生命计划可能快实现了!HeyGen即将发布下一代AI真人视频生成技术,效果逼真到无法几乎分辨!
开源王者!全球最强的开源大模型Llama3发布!15万亿数据集训练,最高4000亿参数,数学评测超过GPT-4,全球第二!
Llama3相比较前两代的模型(Llama1和Llama2)有哪些升级?几张图简单总结Llama3的训练成本、训练时间、模型架构升级等情况