
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



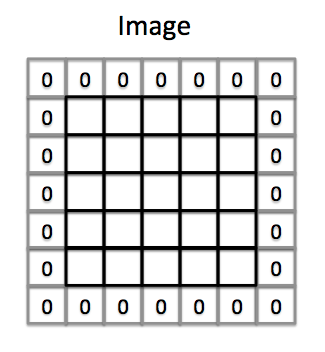
卷积神经网络是深度学习中处理图像的利器。在卷积神经网络中,Padding是一种非常常见的操作。本片博客将简要介绍Padding的原理。
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
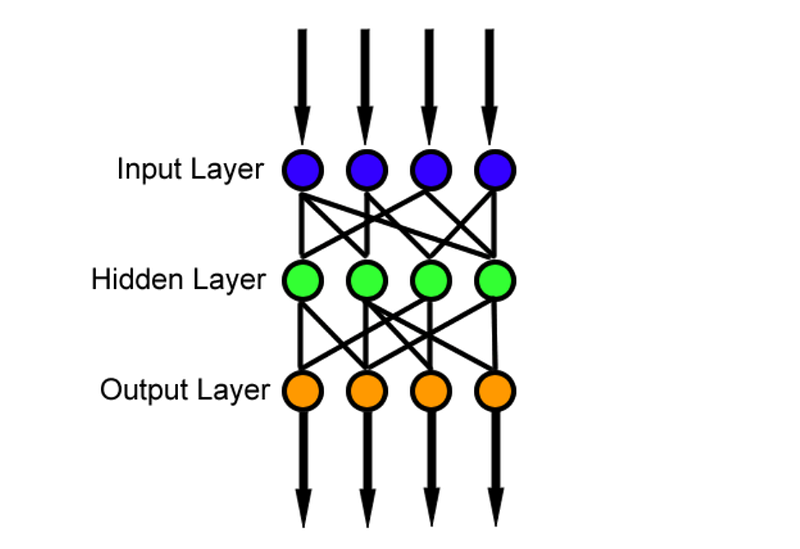
深度学习是计算机领域中目前非常火的话题,不仅在学术界有很多论文,在业界也有很多实际运用。本篇博客主要介绍了三种基本的深度学习的架构,并对深度学习的原理作了简单的描述。本篇文章翻译自Medium上一篇入门介绍。
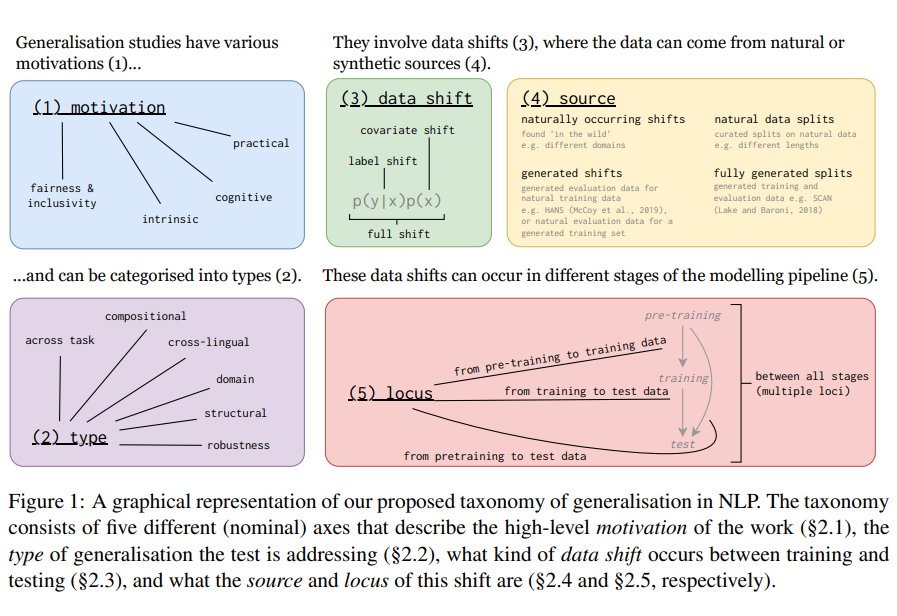
关于什么是好的泛化、存在哪些类型的泛化以及在不同的场景中哪些应该被优先考虑,人们对此了解甚少且意见不一。而MetaAI等机构的研究人员最近发布了一篇关于大模型泛化能力的综述,详细总结了大模型泛化能力的分类等。本篇论文详细总结一下大模型的泛化能力分类以及什么样的泛化是未来的中的重点等问题。

LAION全称Large-scale Artificial Intelligence Open Network,是一家非营利组织,成员来自世界各地,旨在向公众提供大规模机器学习模型、数据集和相关代码。他们声称自己是真正的Open AI,100%非盈利且100%Free。在九月份,他们公布了一个全新的图像-文本对(image-text pair)数据集。该数据集包含4亿条数据。
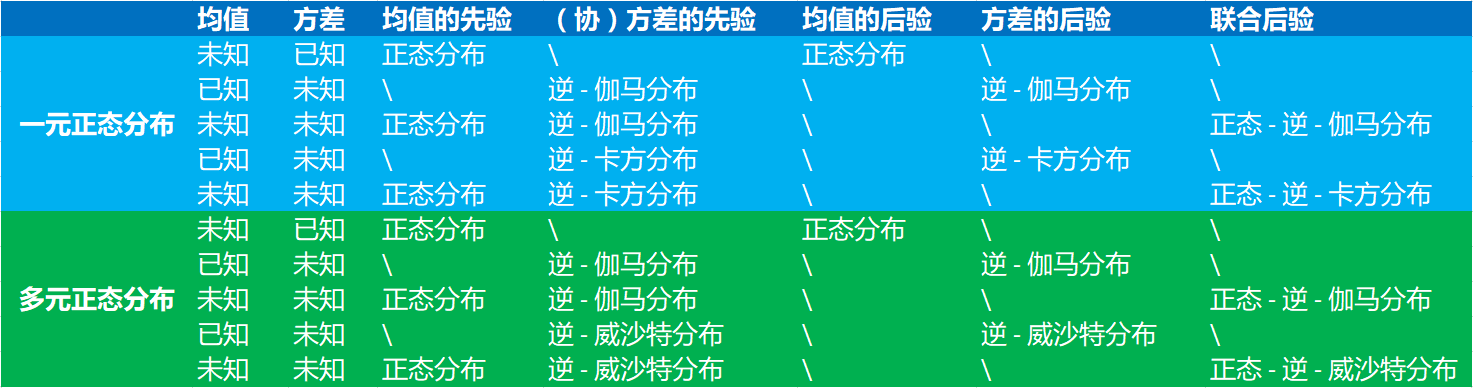
高斯分布是最常见的分布,也是数据挖掘和人工智能中相关统计学习方法所涉及到的最重要的分布之一。使用贝叶斯理论进行统计推断是目前最流行的推断方式。

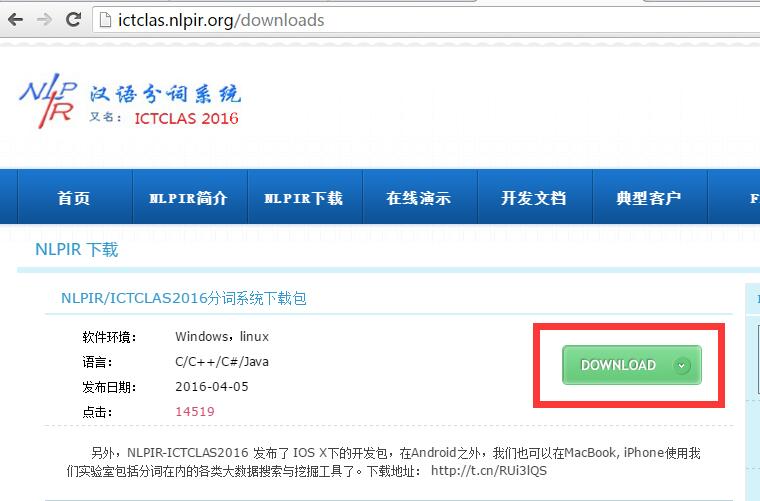
张华平汉语分词系统,现称为NLPIR汉语分词系统,是优秀的中文分词系统。但其使用却有一些配置上的设置是新手可能遇到的一个困难。这里我们简单介绍使用Eclipse导入NLPIR分词系统工程的使用方法。
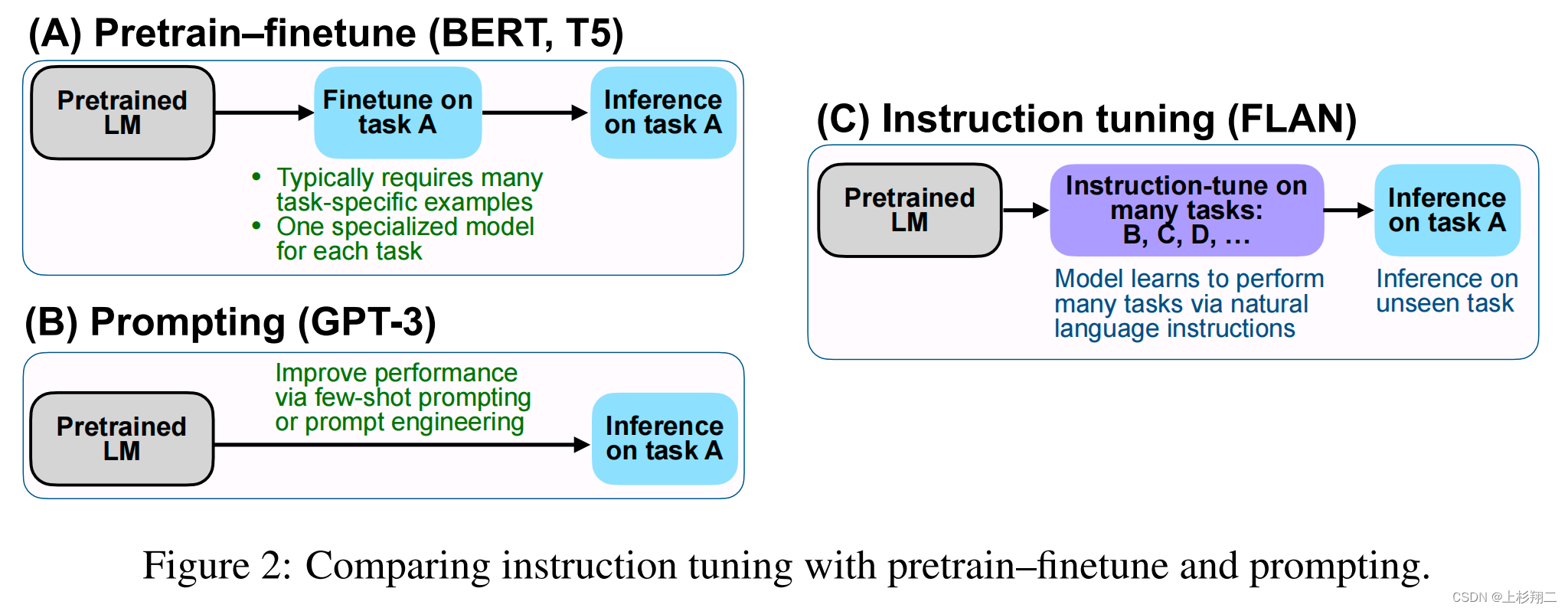
通过调整提示文本,可以使语言模型更好地理解任务的要求和上下文,从而提高其在特定任务上的表现。Prompt tuning是使大型语言模型更加智能和高效的关键步骤之一。只有通过精心设计和优化提示文本,我们才能充分发挥大型语言模型的潜力,并使其更好地服务于人类的需求。因此,Prompt engineering,这一种新的工程能力也开始变得重要。
嵌入(Embedding)是深度学习方法处理自然语言文本最重要的方式之一。它将人类的自然语言和文本转换成一个浮点型的向量。向量之间的距离代表了它们的关系。今天,OpenAI宣布了他们的Embedding新模型——text-embedding-ada-002。官方宣称这是目前OpenAI最强的嵌入模型,可以将任意文本转换成一个向量,且效果好于目前所有OpenAI的模型。
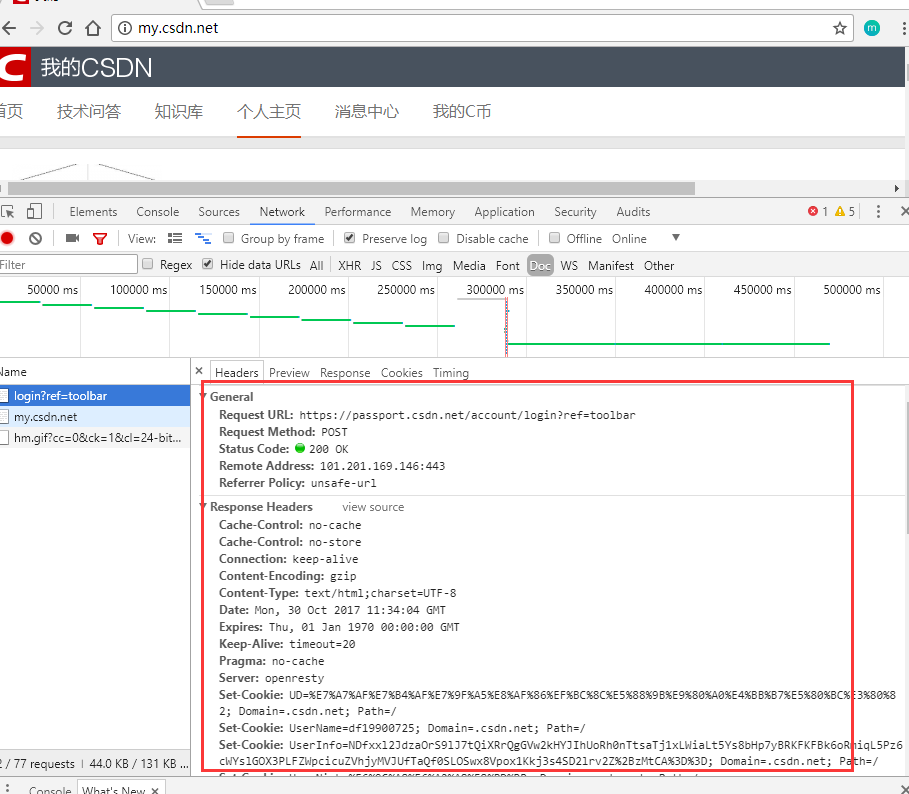
网络爬虫需要解决的一个重要的问题就是要针对某些需要用户名和密码访问的页面可以模拟用户自动登录。在这一篇博客中我们将介绍如何使用Chrome浏览器自带的抓包工具分析页面并模拟用户自动登录
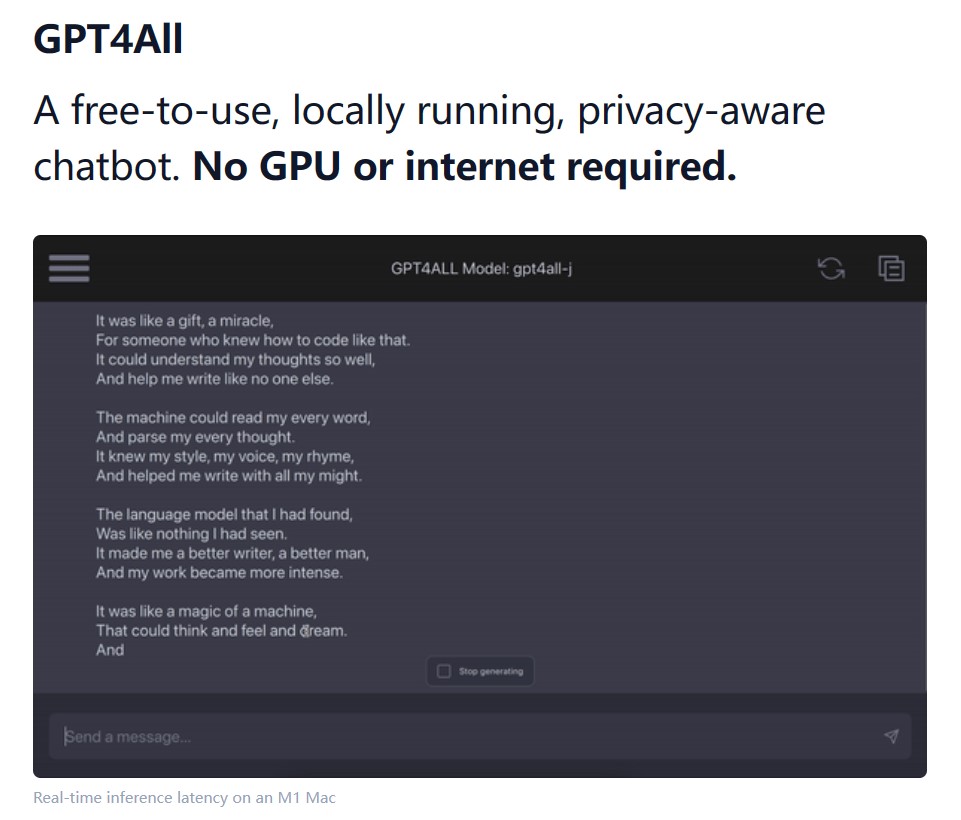
NomicAI推出了GPT4All这款软件,它是一款可以在本地运行各种开源大语言模型的软件。GPT4All将大型语言模型的强大能力带到普通用户的电脑上,无需联网,无需昂贵的硬件,只需几个简单的步骤,你就可以使用当前业界最强大的开源模型。
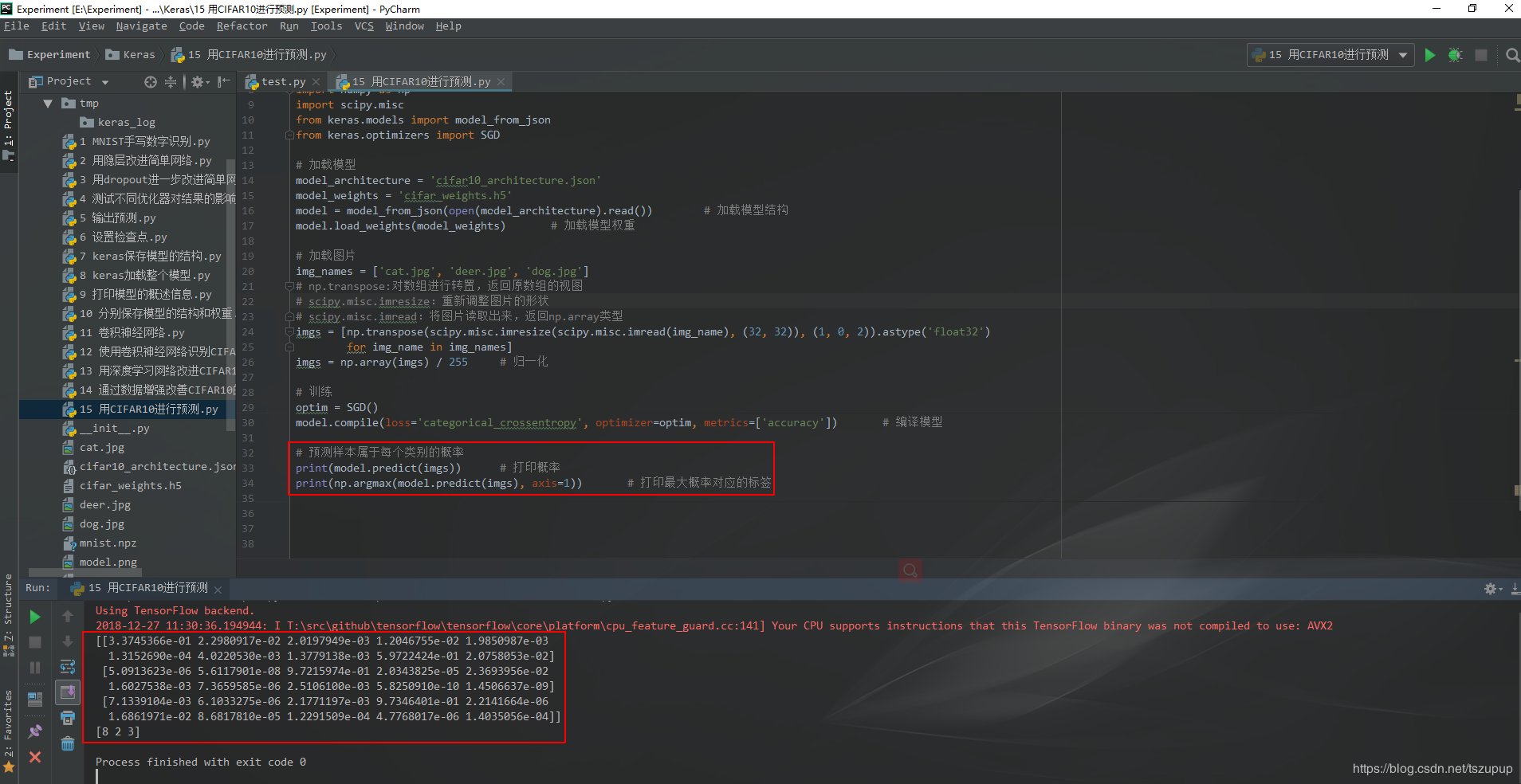
Keras中predict()方法和predict_classes()方法的区别
贝叶斯分析在概率模型中有非常重要的作用,这些年以来比较有影响力的模型如LDA、非参数贝叶斯模型等都是基于贝叶斯分析的。贝叶斯分析有一些非常基础性的知识,在这里我们描述了贝叶斯分析里面的一些基本表示和一些分析准则等内容。