
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




红黑树(Red-Black Tree)也是一种自平衡二叉查找树,与AVL不同的是它依靠节点颜色来维护树的平衡,在自平衡操作的时候,依赖变色和旋转两种操作来进行。
C语言的编程与Java和Python有所差别。C语言的开发环境的搭建与其它也有所不同。本文主要是针对初学者提供一个C语言开发环境的搭建指南。

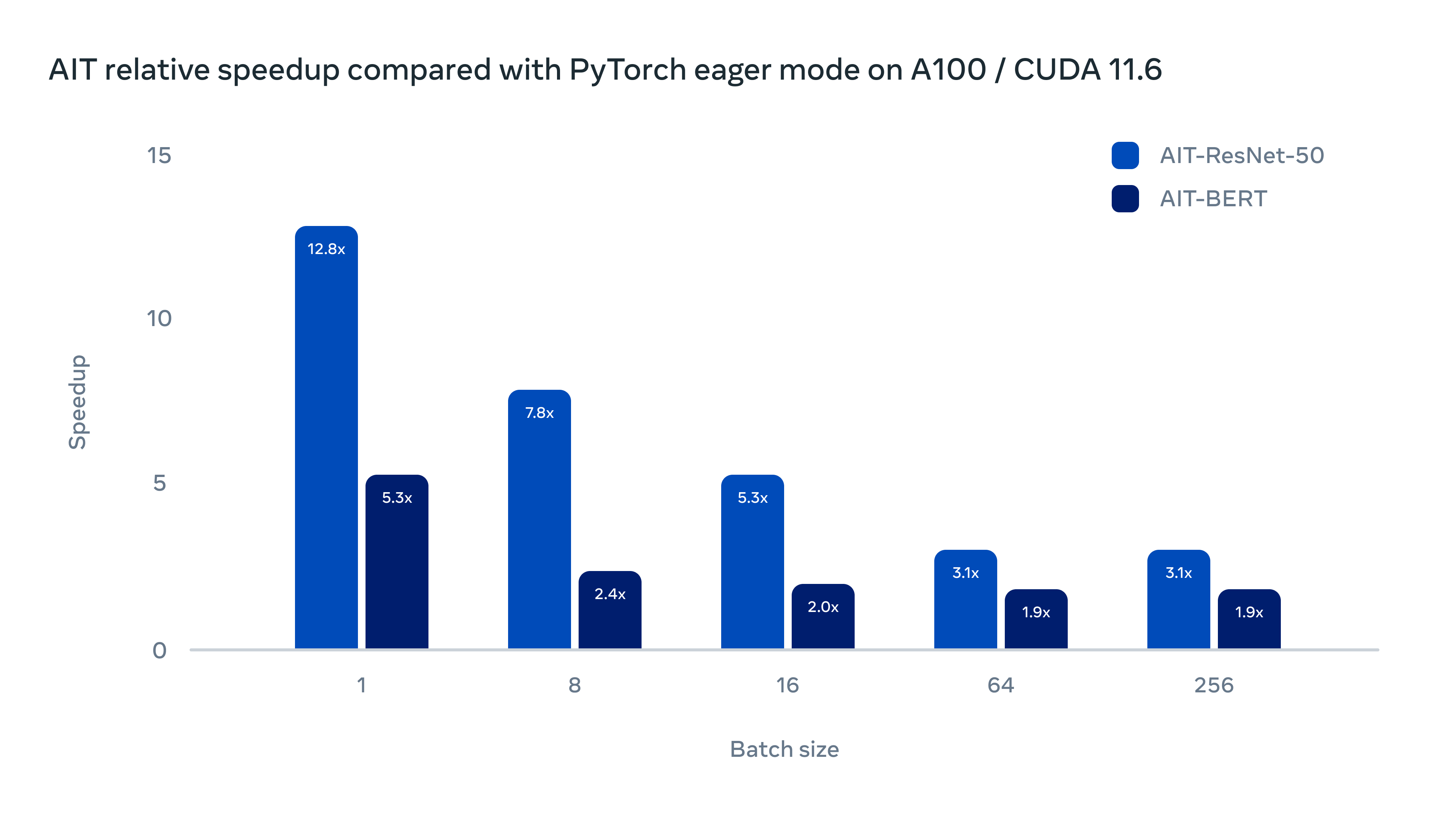
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。
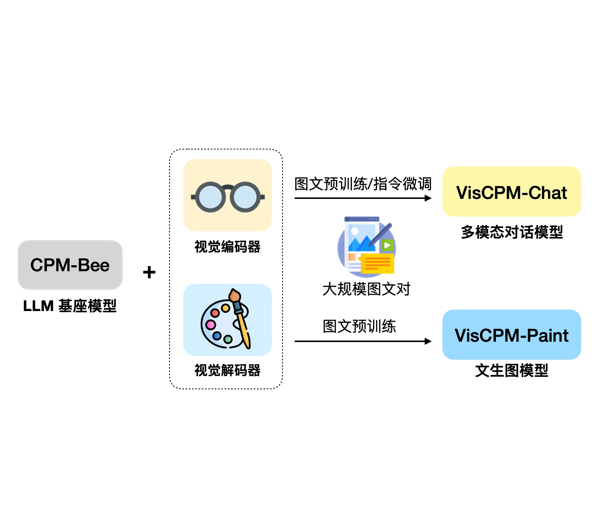
大模型的发展正在从单纯的语言模型向多模态大模型快速发展。尽管GPT-4号称也是一个多模态大模型,但是受限于GPU资源,GPT-4没有开放任何多模态的能力(参考:https://www.datalearner.com/blog/1051685866651273 )。目前大家所能接触到的多模态大模型很少。今天,清华大学NLP小组带来了新的选择,发布了VisCPM系列多模态大模型。VisCPM系列包含2类多模态大模型,分别针对多模态对话和文本生成图片进行优化。

大模型的发展一个重要的基础条件是底层硬件计算能力的大幅提高,特别是GPU的发展,与transformer架构的大模型训练非常契合。当前全球最大的GPU供应商英伟达系列的显卡几乎垄断了大模型训练与推理的所有GPU芯片市场。除了英伟达显卡本身算力强悍外,基于英伟达GPU之上构建的CUDA、PyTorch等平台软件生态也是非常重要的一环。而最新的PyTorch2.1版本发布的一个beta特性中包含了对华为昇腾芯片的原生支持,这也是大模型生态多样性发展的一个很重要的信号。

文本生成的主要目的是基于报表和分析生成总结性的文字以辅助商业决策,也就是NLG(Natural Language Generation)。主要的方向包括:基于图表生成洞察报告、基于数据与图表支持问答系统等。本文介绍文字生成的方案提供商。

5月4日,网络流传了一个所谓Google内部人员写的内部信,表达了Google和OpenAI这样的公司可能并不能在AI领域获得胜利的焦虑。里面说明了开源的AI模型发展迅速,不管是Google还是OpenAI都没有很好的护城河。

今日推荐
全球最大的39亿参数的text-to-image预训练模型发布
加州大学欧文分校信息技术办公室开放基于GPT-4.5的ZotGPT服务测试
如何对向量大模型(embedding models)进行微调?几行代码实现相关原理
ChatGPT颠覆更新!即将发布的ChatGPT新版本带来巨变,新界面和可以自定义GPT-4功能:可以对接私有数据与私有接口的个性化ChatGPT即将到来!
Java爬虫入门简介(二) —— HttpClient详细使用方法
Scrapy网络爬虫实战[保存为Json文件及存储到mysql数据库]
大模型评测的新标杆:超高难度的“Humanity’s Last Exam”(HLE)介绍