
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




Prompt技巧一直是提升ChatGPT等大语言模型使用效率的最重要方法之一。为此,OpenAI官方也在不断地分享官方的Prompt技巧。2023年的8月31日,OpenAI官方最新分享了一个教室使用的Prompt来帮助老师授课的案例。尽管这是针对老师的Prompt教程,但是其中的设计思路其实也可以广泛运用在客服、问答系统、编程等领域。

Batch Normalization(BN)是深度学习领域最重要的技巧之一,最早由Google的研究人员提出。这个技术可以大大提高深度学习网络的收敛速度。简单来说,BN就是将每一层网络进行归一化,就可以提高整个网络的训练速度,并打乱训练数据,提升精度。但是,BN的使用可以在很多地方,很多人最大的困惑是放在激活函数之前还是激活函数之后使用,著名机器学习领域的博主Santiago总结了这部分需要注意的内容。

在今年的Microsoft Build 2023大会上,来自OpenAI的研究员Andrej Karpathy在5月24日的一场汇报中用了40分钟讲解了ChatGPT是如何被训练的,其中包含了训练一个能支持与用户对话的GPT的全流程以及涉及到的一些技术。信息含量丰富,本文根据这份演讲总结。

随着大型语言模型(LLM)如 GPT-3 和 BERT 在 AI 领域的崛起,如何在实际应用中高效地进行模型推断成为了一个关键问题。为此,英伟达推出了全新的大模型推理提速框架TensorRT-LM,可以将现有的大模型推理速度提升4倍!

Llama3是MetaAI开源的最新一代大语言模型。一发布就引起了全球AI大模型领域的广泛关注。这是MetaAI开源的第三代大语言模型,也是当前最强的开源模型。但相比较第一代和第二代的Llama模型,Llama3的升级之处有哪些?本文以图表的方式总结Llama3的升级之处。
Awesome ChatGPT Prompts是由JavaScript开发者Fatih Kadir Akın创建的一个网站和应用,里面收集了160多个关于ChatGPT的Prompt模板,可以让ChatGPT变成Linux终端、JavaScript控制台、Excel页面等。这些Prompts收集自优秀的实践案例。
苹果刚刚发布了一个全新的机器学习矿机MLX,这是一个类似NumPy数组的框架,目的是可以在苹果的芯片上更加高效地运行各种机器学习模型,当然最主要的目的是大模型。

在做LeetCode题目的时候,有一类题目是关于大数运算的。比如,全排列计算或者组合运算,在使用C语言或者Java代码解决这类问题的时候都会遇到变量数值超过阈值的情况。一般来说需要自己构造字符串数组或者是其它数组来存储超过长度的数值。但是,使用Python语言处理这类问题时候却毫无压力,这类题目的计算不会有任何问题。本文将从Python底层实现解释这个问题。

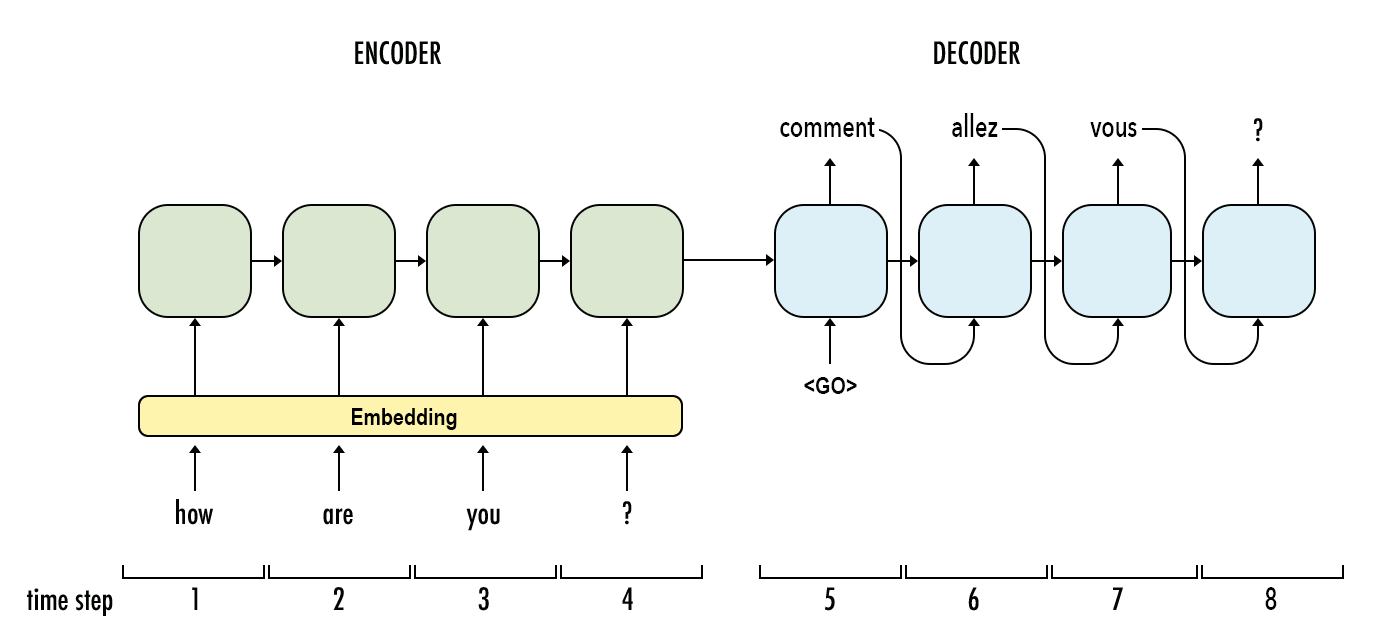
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
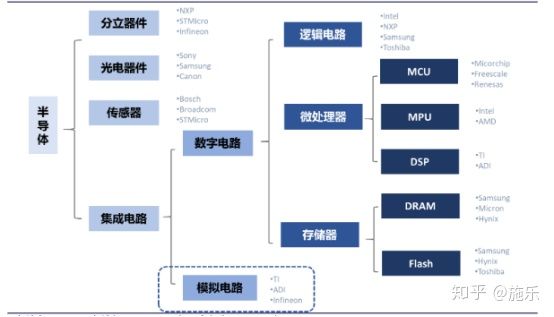
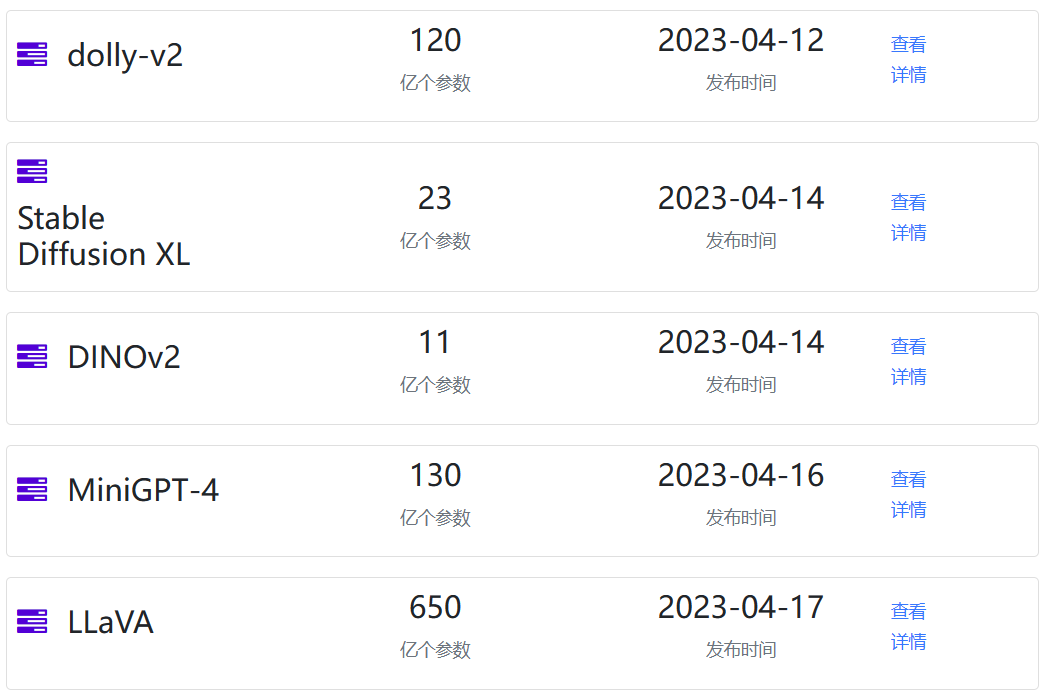
AI模型的发展速度令人惊讶,几乎每天都会有新的模型发布。而2023年4月中旬也有很多新的模型发布,我们挑出几个重点给大家介绍一下。

前段时间,OpenAI的CEO Sam Altman与二十多位开发者一起聊了很多关于OpenAI的API和产品的规划问题。Sam Altman透露了一些非常重要的OpenAI的发展方向,包括GPT产品功能的未来规划等。目前这份原始博客内容已经应OpenAI的要求被删除,这里我们简单总结一下这些内容。
今日推荐
来自Microsoft Build 2023:大语言模型是如何被训练出来的以及语言模型如何变成ChatGPT——State of GPT详解
MetaAI开源高质量高精度标注的图像数据集FACET:3.2万张图片、5万个主题,平均图像解析度达到1500×2000
Kimi开源K2大模型:全球首个开源可商用的1万亿参数规模大模型,MoE架构,评测结果与DeepSeekV3相当,但模型文件有1TB!
重磅!MetaAI开源4050亿参数的大语言模型Llama3.1-405B模型!多项评测结果超越GPT-4o,与Claude-3.5 Sonnet平分秋色!