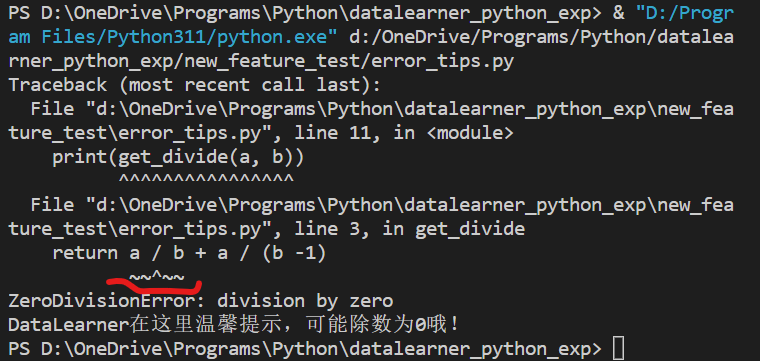
最新好课!从深度学习到stable diffusion的手把手入门教程
Stable Diffusion是最近很火的Text-to-Image预训练模型(详细信息:https://www.datalearner.com/ai-resources/pretrained-models/stable-diffusion )。而现在,相关的视频教程已经出现。fast.ai的团队宣布了一门新的深度学习课程《From Deep Learning Foundations to Stable Diffusion》上线!