
原创博客
原创AI技术博客
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
文本预处理的一般步骤和方法
文本预处理是一件极其耗费时间的事情,不仅繁琐而且涉及的细节很多,处理不好对后面的事情的影响很大。本文将简要介绍文本预处理的一般步骤和方法。
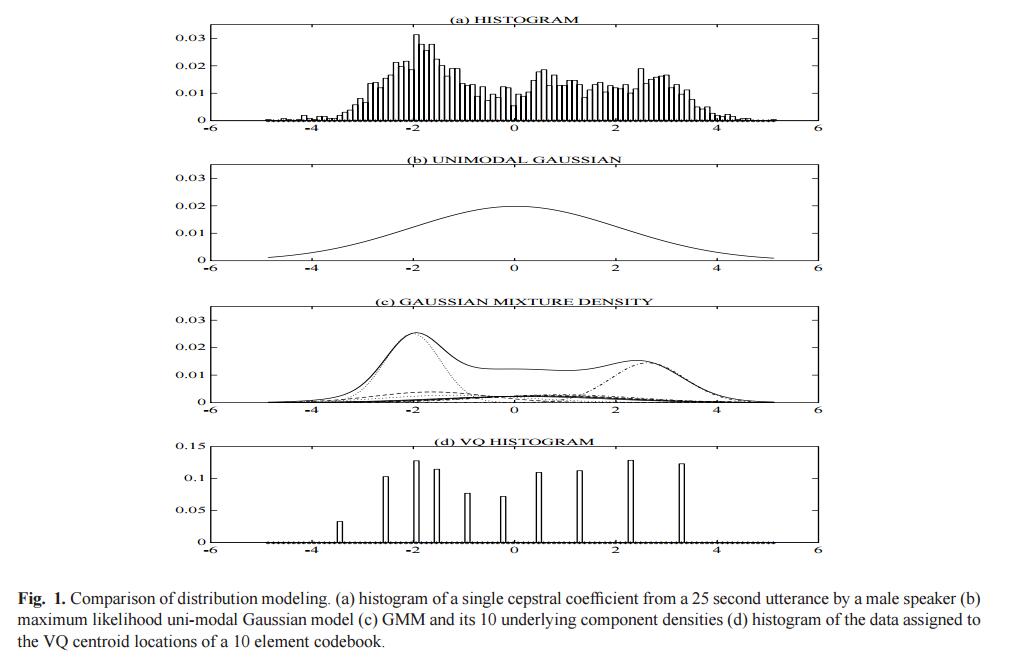
高斯混合模型(GMM)
高斯混合模型是一个参数概率密度函数,它是一组高斯密度函数的加权求和。在生物统计领域,高斯混合模型通常是连续测度或者特征的概率分布的参数模型。高斯混合模型可以使用迭代的EM算法或者最大后验概率法估计参数。
多项式分布的贝叶斯推断
多项式分布是非常常见的分布,他是二项分布在多维上的推广。例如掷骰子结果中,1-6点出现的次数就是一个多项式分布。多项式分布在如主题建模中非常常见,本文将讲述多项式分布的贝叶斯推导过程。

如何理解狄利克雷过程(Dirichlet Process)
狄利克雷过程是非参贝叶斯推断的基础模型。本博客将简要介绍狄利克雷过程模型
keras解决多标签分类问题
multi-class classification problem和 multi-label classification problem在keras上的实现


MySQL启用中文全文检索功能
MySQL支持对文本进行全文检索,全文检索可以类似搜索引擎的功能,相比较模糊匹配更加灵活高效且更快。MySQL5.7之后也支持对中文的全文检索,这里描述如何启用MySQL的中文全文检索。
《Effective Java 第三版》笔记之一 创建静态工厂方法而不是使用构造器
本文是Effective Java第三版笔记的第一个之创建静态工厂方法而不是使用构造器