
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



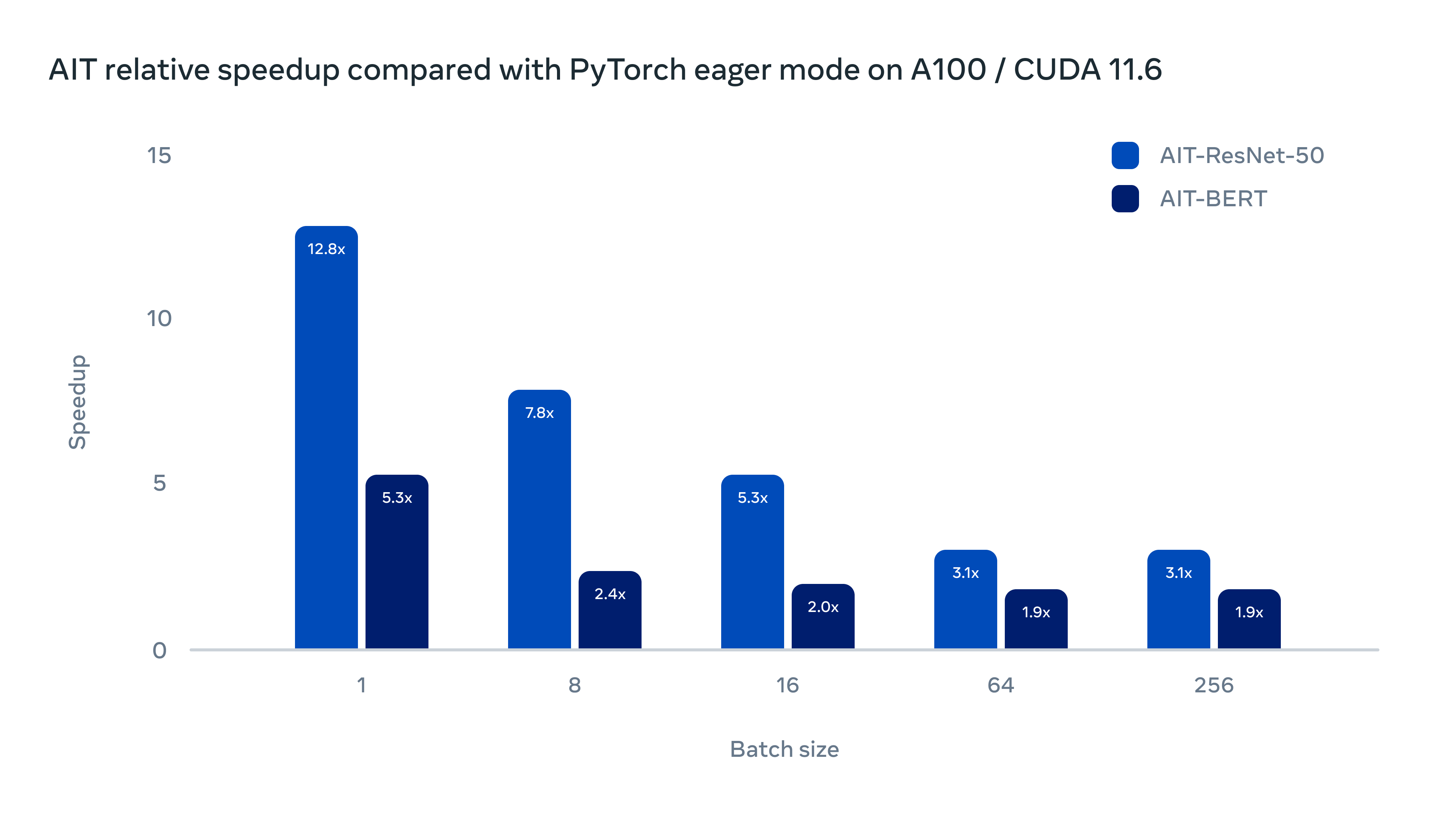
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。
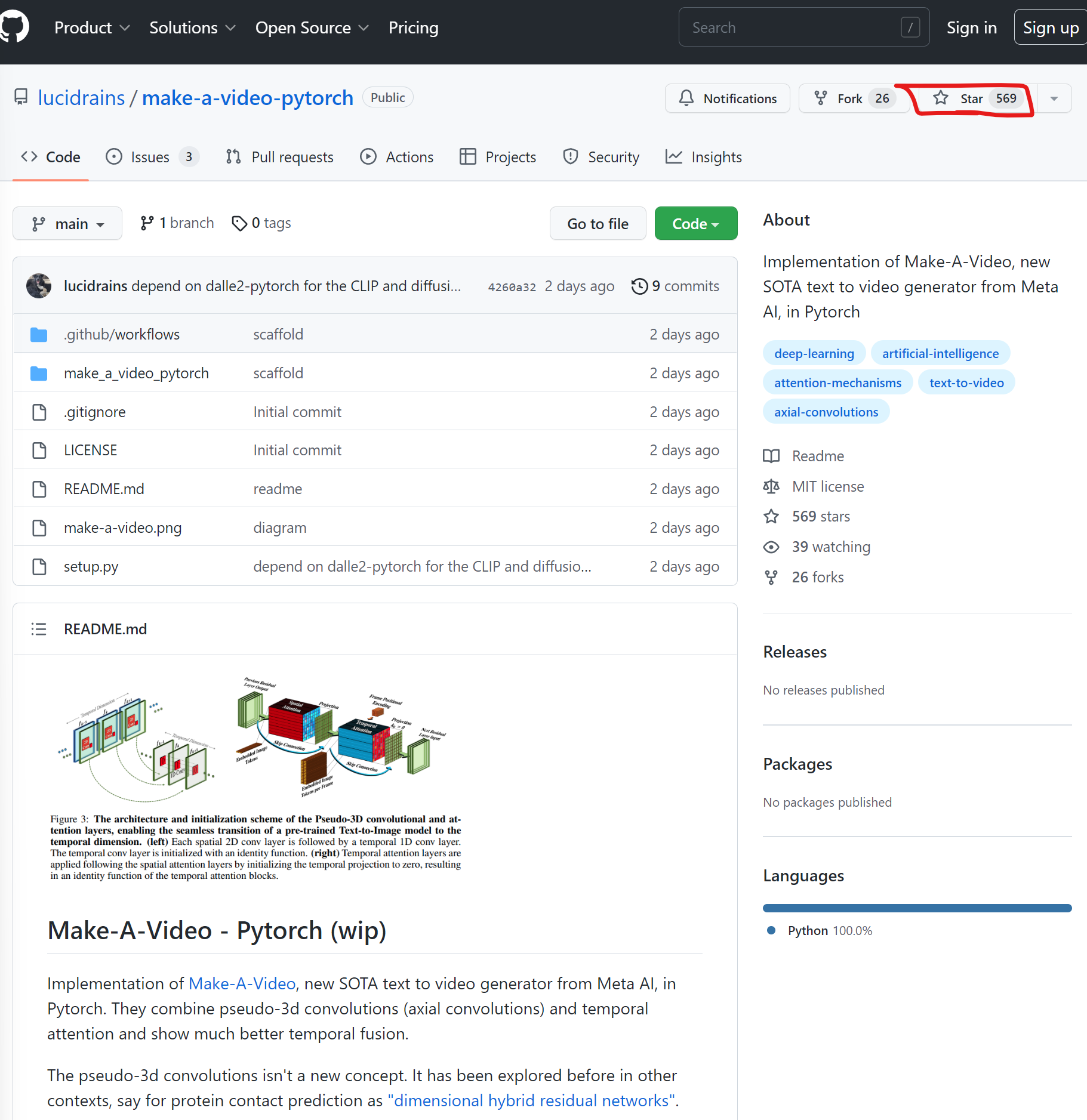
MetaAI在2天前刚发布了一个最新的Text-to-Video模型,让生成模型从逼真的图片生成往前推进到视频生成。当然,官方还是希望将其当作一种SaaS服务提供。但是,才2天,业界基于论文的开源PyTorch实现就已经准备公开,且获得了569个Star!卷到家了!

Stable Diffusion是一种功能强大的开源文本到图像(Text-to-Image)生成模型。虽然目前有多个开源项目可以实现基于文本提示(prompt)创建图像,但Stable Diffusion性能极其强大,其结果甚至可以媲美DALL·E2。而现在KerasCV提供了这个模型的官方实现!
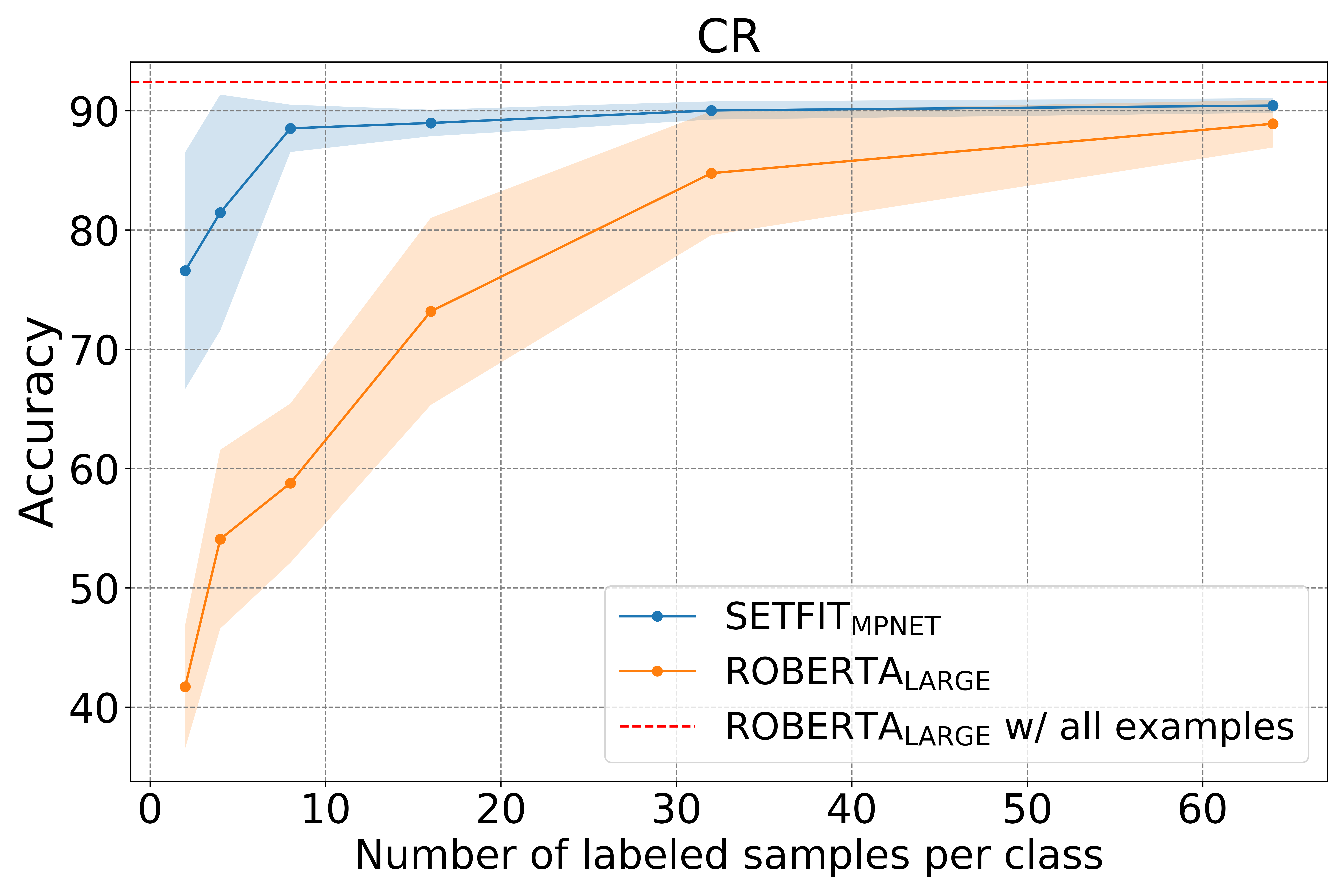
少量标记的学习(Few-shot learning)是一种在较少标注数据集中进行模型训练的一种学习方法。为了解决大量标注数据难以获取的情况,利用预训练模型,在少量标记的数据中进行微调是一种新的帮助我们进行模型训练的方法。而就在昨天,Hugging Face发布了一个新的语句transformers(Sentence Transformers)框架,可以针对少量标记数据进行模型微调以获取很好的效果。
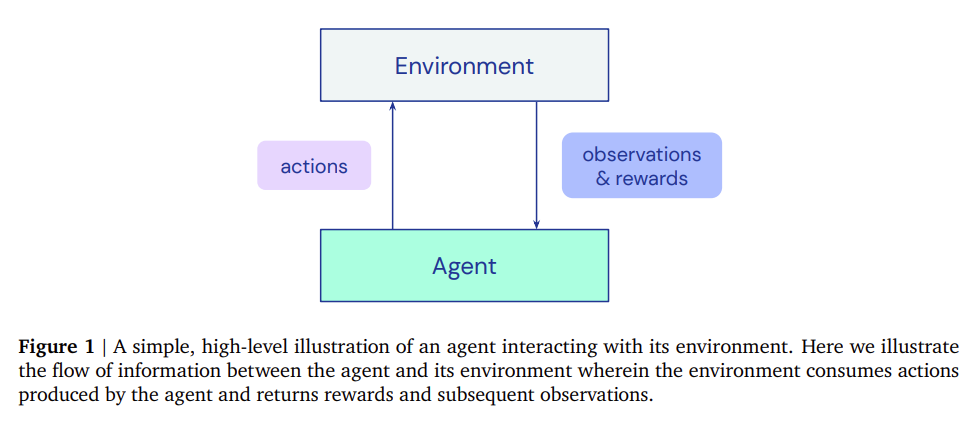
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的
昨天,Meta的Zuckerberg宣布,将PyTorch由Meta AI移交给Linux Foundation托管。这意味着PyTorch从今天起从Meta独立,并作为Linux Foundation下的一个项目。

随着安全隐私被大家所重视,网站开启HTTPS访问已经是不可阻挡的趋势。HTTPS协议就是借助SSL/TLS证书实现http的加密传输的协议(HTTP Over SSL/TLS)。本文将记录如何使用第三方库申请Let's Encrypt证书,并在tomcat中开启相关的功能。
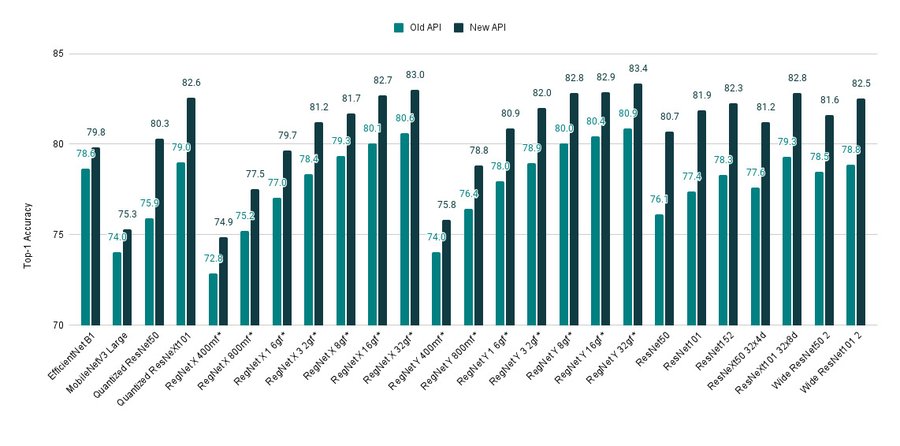
PyTorch最新的1.12版本已经在前天发布。而其中TorchVision是基于PyTorch框架开发的面向CV解决方案的一个PyThon库,其最主要的特点是包含了很多流行的数据集、模型架构以及预训练模型等。本次也随着PyTorch1.12的发布更新到了v0.13。此次发布包含几个非常好的提升,值得大家关注。

就在儿童节前一天,Hugging Face发布了一个最新的深度学习模型评估库Evaluate。对于机器学习模型而言,评估是最重要的一个方面。但是Hugging Face认为当前模型评估方面非常分散且没有很好的文档。导致评估十分困难。因此,Hugging Face发布了这样一个Python的库,用以简化大家评估的步骤与时间。

自从苹果发布M1系列的自研芯片开始,基于ARM架构的电脑处理器开始大放异彩。而强大的M1芯片的能力也让很多Mac用户高兴很久。而就在现在,M1也开始支持PyTorch的深度学习框架了。PyTorch官网刚刚宣布,经过和Apple的Metal工程师队伍的合作,PyTorch支持Mac的GPU加速了。

很多童鞋在查询期刊的时候会发现某些期刊不是SCI(SCIE)索引,而是一个叫ESCI的索引。这似乎有点像SCI,但好像又有区别,所以大家会有疑问,本篇博客将解释二者的区别。
昨天,Copilot团队推出了一个名为GitHub Copilot Labs的VS Code配套扩展。它独立于(并依赖于)GitHub Copilot扩展。它可以用来解释代码和翻译代码。
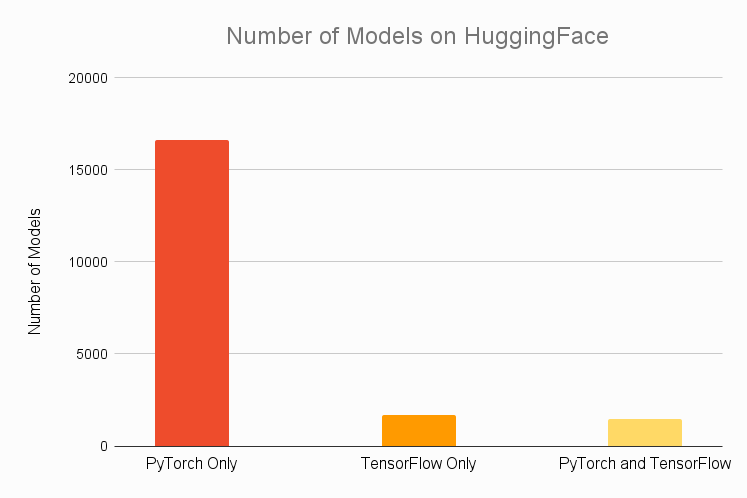
Tensorflow和PyTorch是深度学习最流行的两个框架,二者都有坚定的支持者。一般认为由于Google的支持,TensorFlow的社区支持比较好,在工业应用广泛。但是尽管有keras加持,但易用性方面依然被认为不如PyTorch。而后者最早由Facebook人工智能团队开发。由于其易用性,被认为在科学研究中有广泛使用。那么,最近几年二者发展如何,是否实际还如之前的观点一样,这里AssemblyAI的一个作者做了一些对比。

计算机视觉与自然语言处理是近几年人工智能领域进步最快以及应用最为成熟的两个方向。计算机视觉里面任务涉及面广,有很多细分领域,本文将对计算机视觉领域中比较常见的六种任务进行总结并同时展示以下相关任务的一些成绩。
这是一篇来自Sayak Paul的预测,这个哥们长期混迹于各个开源社区,积极参与各大公司的开发者大会。目前在一家初创企业工作,简历非常丰富,非常积极在社区推广自己。但是不管怎么说,他在计算机视觉领域也是一直在一线工作。他对未来计算机视觉的发展方向有五个预测,虽然不一定准确,但是我们可以借助这个进行思考。
今日推荐
DataLearner大模型综合评测对比表!国产大模型与全球最强大模型大比拼:语义理解、数学推理同台竞技,究竟谁更厉害~
如何使用git从GitHub上下载项目、更新远端项目并提交本地的更改
截止目前中文领域最大参数量的大模型开源:上海人工智能实验室开源200亿参数的书生·浦语大模型(InternLM 20B系列),性能提升非常明显!
在消费级显卡上微调OpenAI开源的自动语言识别模型Whisper:8GB显存即可针对你自己的数据建立ASR模型
主题模型聚类匹配2018TKDE阅读笔记(Topic Models for Unsupervised Cluster Matching)
主题模型结合词向量模型(Improving Topic Models with Latent Feature Word Representations)