
Dask分布式任务中包含写文件的方法时候,程序挂起不结束的解决方案
使用Dask进行分布式处理的时候一个最常见的场景是有很多个文件,每个文件由一个进程处理。这种操作经常会遇到一个程序挂起的问题,使得程序永远运行,无法结束。本文描述如何解决。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
使用Dask进行分布式处理的时候一个最常见的场景是有很多个文件,每个文件由一个进程处理。这种操作经常会遇到一个程序挂起的问题,使得程序永远运行,无法结束。本文描述如何解决。
使用pandas的DataFrame和dask的DataFrame保存数据到csv文件时候会出现两个换行符的情况。本文描述如何解决。
Dask的集群启动创建也很简单,有好几种方式,最简单的是采用官方提供dask-scheduler和dask-worker命令行方式。本文描述如何使用命令行方法建立Dask集群。
当数据量达到一定程度,单机的处理能力会无法达到性能的要求,采用并行计算,并利用多台服务器进行分布式处理可能会提升数据处理的速度,达到性能要求。然而如果使用不当,并行处理可能并不会提升处理的速度。这篇博客介绍了Dask中关于并行处理的一些效率方面的建议,尽管是针对Dask的说明,但对于所有的并行处理来说都是适用的。
Dask提供了多种分布式调度器,当缺少多台服务器时候,也可以通过本地集群来实现单机分布式的计算。这篇博客主要就是介绍如何实现Dask的单机分布式调度器。第一小节是简介,第二节是单机调度器的简写版本,第三节是单机调度器的完整版本,第四节是使用的一些示例。
Pandas中的DataFrame选择某些行和某些列是有很多中操作和选择的,不太容易记,这里整理一下。
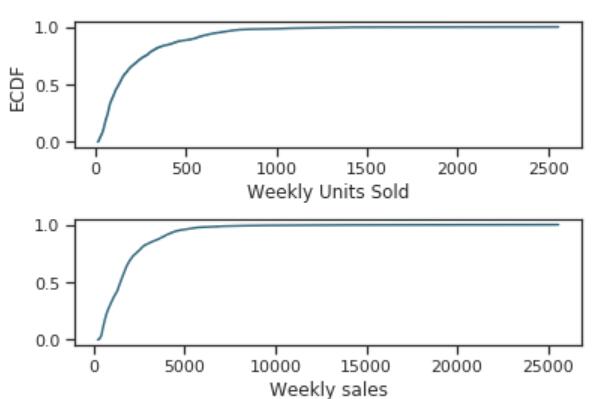
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。
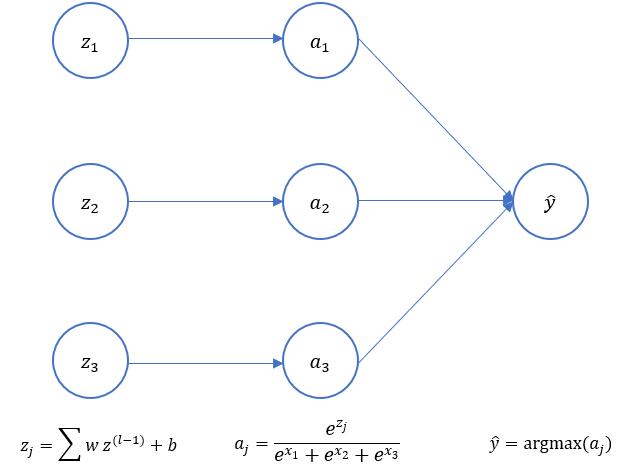
softmax作为多标签分类中最常用的激活函数,常常作为最后一层存在,并经常和交叉熵损失函数一起搭配使用。这里描述如何推导交叉熵损失函数的推导问题。

Tensorflow中tf.data.Dataset是最常用的数据集类,我们也使用这个类做转换数据、迭代数据等操作。本篇博客将简要描述这个类的使用方法。
pandas的使用
Microsoft Visual C++ 14.0 is required
本篇博客主要讲解如何从给定参数的的正态分布/均匀分布中生成随机数以及如何以给定概率从数字列表抽取某数字或从区间列表的某一区间内生成随机数,按照内容将博客分为3部分,并附上代码。
如何使用python绘制简单的散点图
您刚刚经历了一个耗时的过程,将一堆数据加载到python对象中。 也许你从数千个网站上爬取了数据。也许你计算了pi的数值。如果您的笔记本电脑电池耗尽或python崩溃,您的信息将丢失。 Pickling允许您将python对象保存为硬盘驱动器上的二进制文件。 在你pickle你的对象后,你可以结束你的python会话,重新启动你的计算机,然后再次将你的对象加载到python中。
神秘的numpy.argpartition
Scrapy网络爬虫实战[保存为Json文件及存储到mysql数据库]
python中Scrapy的安装详细过程
python中Scrapy的安装详细过程
python操作数据库