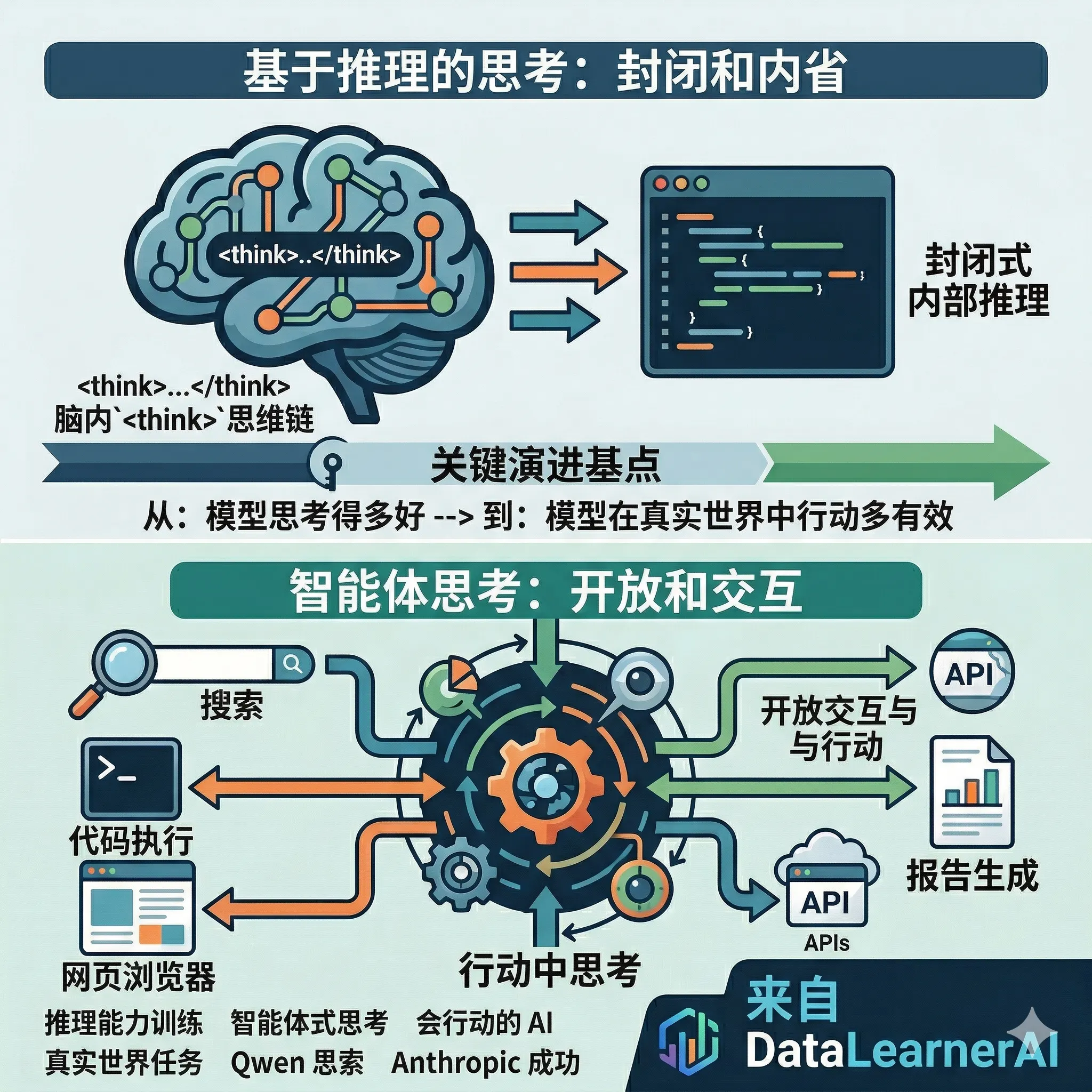
AI 的下一阶段,不是更长的推理链,而是真正的行动力,大模型训练将从“推理式思考”走向“智能体式思考”——前 Qwen 负责人林俊旸(Junyang Lin)最新判断
unyang 是前 Qwen(通义千问)负责人,前段时间他的离职造成了许多人的关注。不过他并未沉寂,就在刚才,Junyang 发表了一篇关于如何训练大模型推理能力、以及未来大模型推理能力训练应该走向何方的深度讨论。
汇总「大模型Agent」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
unyang 是前 Qwen(通义千问)负责人,前段时间他的离职造成了许多人的关注。不过他并未沉寂,就在刚才,Junyang 发表了一篇关于如何训练大模型推理能力、以及未来大模型推理能力训练应该走向何方的深度讨论。

PinchBench 是 Kilo Code 团队开发的开源基准测试系统,用于评估大型语言模型作为 OpenClaw 编码代理核心的表现。该系统运行一组固定真实世界任务,计算代理的任务完成成功率,同时记录执行速度和成本。所有结果通过公开排行榜 https://pinchbench.com 显示,目前包含 50 个模型的 403 次运行记录,最新更新时间为 2026 年 3 月 18 日。基准测试的代码和任务定义全部开源在 GitHub(pinchbench/skill 仓库),任何开发者均可本地复现或添加
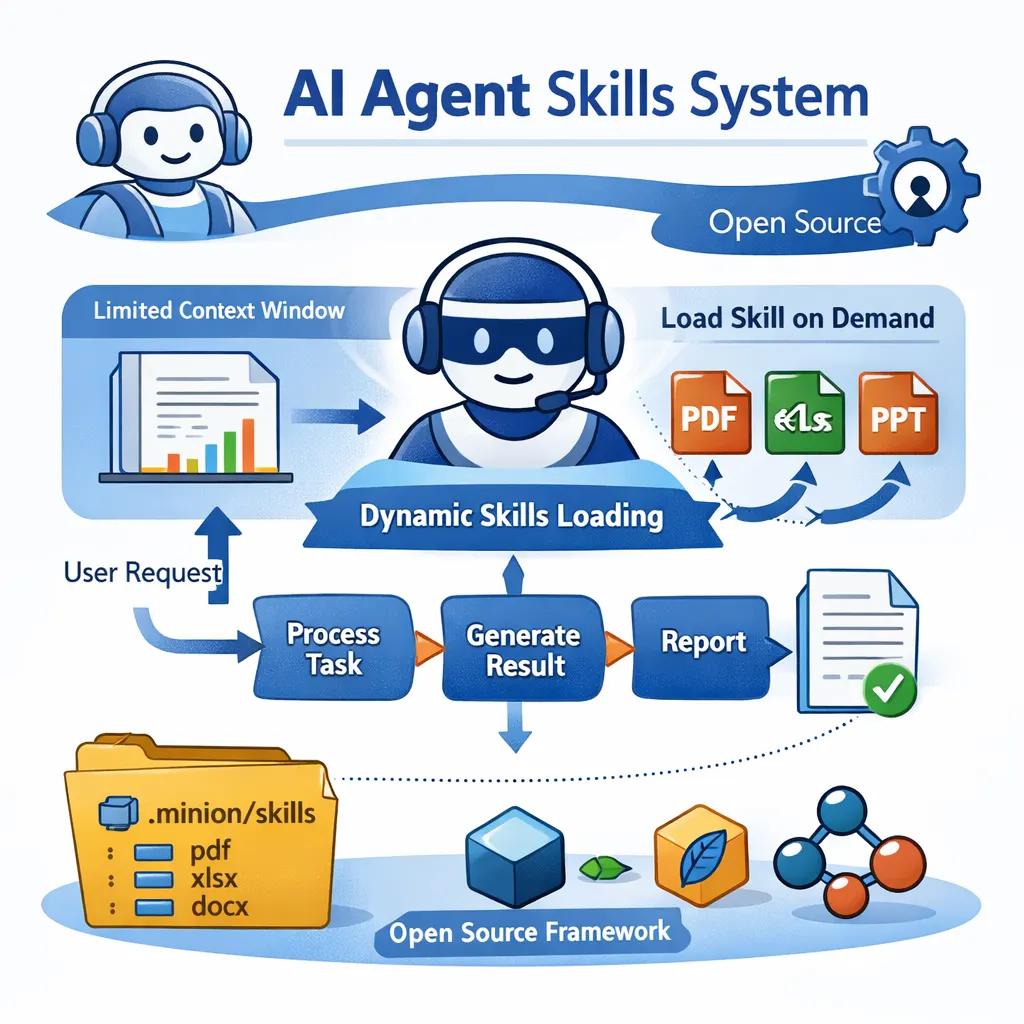
本文介绍了 Claude 最近推出的 Skills 系统,以及作者在 Minion 框架中实现的一个完全开源的版本。Skills 的核心思路是让 AI Agent 在需要时再加载对应的专业能力,而不是一开始就把所有工具和知识都塞进上下文,从而缓解上下文窗口有限、成本高、响应慢的问题。
本文介绍 Terminal-Bench 的设计理念,深入讲解 core、Terminal-Bench Hard 与最新 Terminal-Bench 2.0 的区别,帮助开发者选择合适的 AI 终端评测基准。

为了解决大模型的Agent操作依赖交互和人工处理这个问题,普林斯顿大学与 Sierra Research 的研究团队在 2025 年 6 月提出了 τ²-Bench(Tau-Squared Benchmark),并发布了论文《τ²-Bench: Evaluating Conversational Agents in a Dual-Control Environment》。 它是对早期 τ-Bench 的扩展版本,旨在建立一种标准化方法,评估智能体在与用户共同作用于环境时的表现。