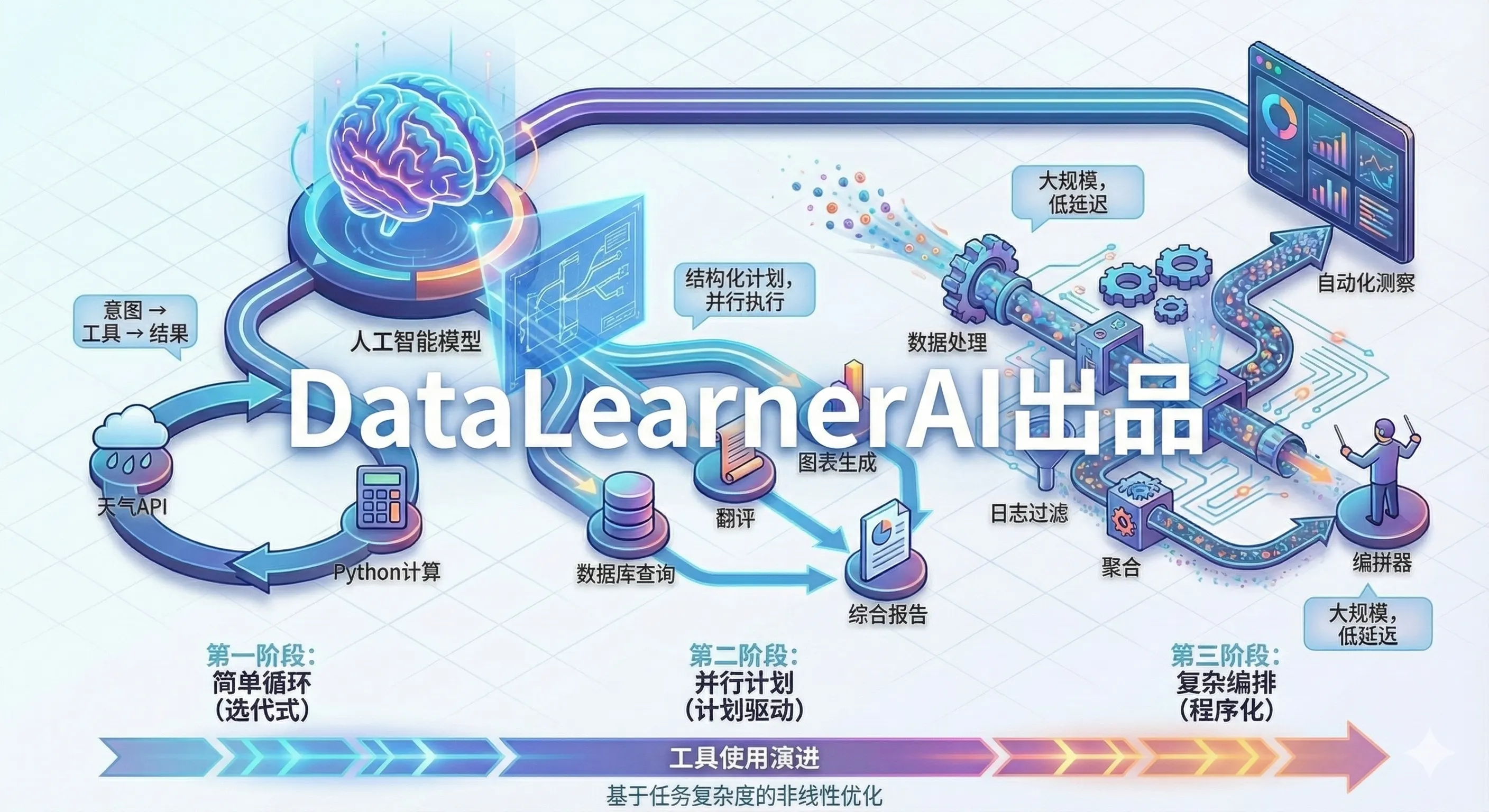
大模型工具使用的三次进化:从 Function Calling 到程序化编排
本文系统梳理了大模型工具使用(Tool Use)的三个演进阶段:循环式工具选择(Function Calling)、计划驱动执行(Plan-then-Execute)和程序化工具编排(Programmatic Tool Calling)。从 OpenAI Function Calling 的单次调用模式,到支持并行调度的计划-执行范式,再到最新的代码驱动编排方式,工具使用正在从"逐步决策"走向"计划驱动、代码驱动"。
汇总「技术」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
本文系统梳理了大模型工具使用(Tool Use)的三个演进阶段:循环式工具选择(Function Calling)、计划驱动执行(Plan-then-Execute)和程序化工具编排(Programmatic Tool Calling)。从 OpenAI Function Calling 的单次调用模式,到支持并行调度的计划-执行范式,再到最新的代码驱动编排方式,工具使用正在从"逐步决策"走向"计划驱动、代码驱动"。

大模型究竟能否真正提升工程师的编码效率?Anthropic 最近发布的一份重量级内部研究给出了少见的、基于真实工程环境的数据答案。研究覆盖 132 名工程师、53 场深度访谈,以及 20 万条 Claude Code 使用记录,展示了 AI 在软件工程中的实际作用:从生产力显著提升(人均合并 PR 数同比增长 67%)、任务空间扩张(27% 的 Claude 工作原本不会被执行),到工程师技能版图、协作方式与职业路径的深刻变化。与此同时,研究也揭示了技能萎缩、监督负担、工作流变化等新挑战。这是一份罕见的“

这篇文章基于 Dwarkesh Patel 对 SSI 创始人、前 OpenAI 首席科学家 Ilya Sutskever 的长访谈,系统梳理了他对模型泛化、人类智能结构、持续学习、RL 与预训练局限、超级智能路径、对齐策略,以及 AI 未来经济与治理的整体判断。文章不仅整理了核心观点,也结合具体原文展开解读,呈现 Ilya 如何从“人类为何能泛化”这一根问题出发,重新思考下一代智能系统应当如何构建。

AI 能不能替我做报告”几乎成了办公室里出现频率最高的疑问之一。模型能力的提升有目共睹,API 的边界也在持续扩张,但回到日常,那些真正让人感到疲惫的依旧是最具体的任务:一份复盘写到深夜,一个 PPT 改了十几版,一张 Excel 来回分析到眼花。它们看似普通,却占据了知识工作中惊人比例的时间。本文主要看一下办公小浣熊这个颇具代表性的大模型应用落地思路。

就在昨天,Anthropic 发布了一套非常重要的工程方案,专门针对这些挑战而设计:基于“Initializer Agent + Coding Agent”的双 Agent 架构。

近日,OpenAI在发布其开源模型gpt-oss-120b和gpt-oss-20b的同时,也推出了一种专为这些模型设计的全新消息格式——Harmony。对于希望在自有解决方案中充分利用这些开源模型的开发者而言,理解Harmony至关重要。本文将以客观的第三方视角,详细解析Harmony格式的设计理念与技术细节。
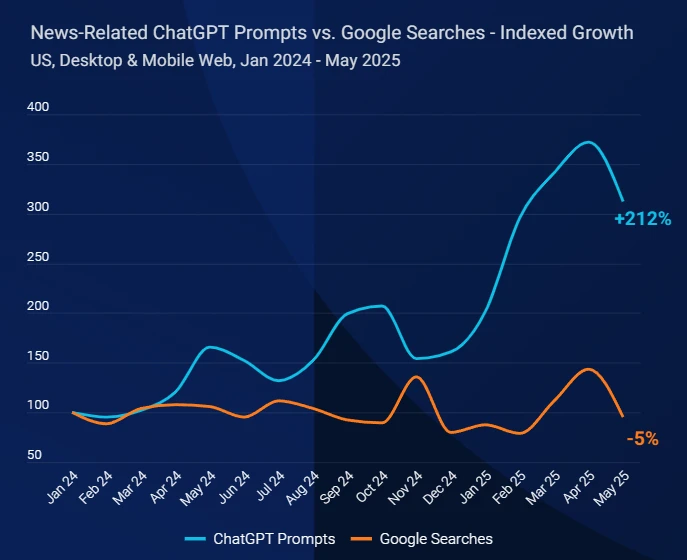
今天,SimilarWeb发布了一个全新的报告,描述了自从ChatGPT这种大模型产品发布之后,新闻出版网站的流量下滑严重,并提供了相关的分析。尽管这是针对新闻网站的报告,但是实际上所有的内容网站或者是内容生产者可能都是有影响的。我们基于这份报告进行解读,为大家提供一个参考。
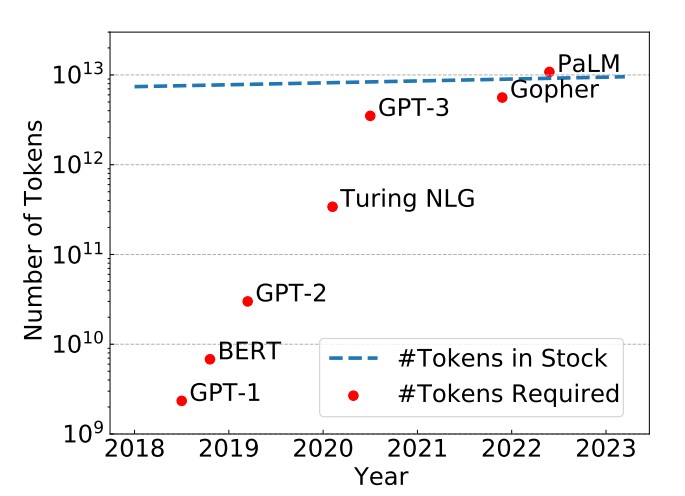
epoch是一个重要的深度学习概念,它指的是模型训练过程中完成的一次全体训练样本的全部训练迭代。然而,在LLM时代,很多模型的epoch只有1次或者几次。这似乎与我们之前理解的模型训练充分有不一致。那么,为什么这些大语言模型的epoch次数都很少。如果我们自己训练大语言模型,那么epoch次数设置为1是否足够,我们是否需要更多的训练?
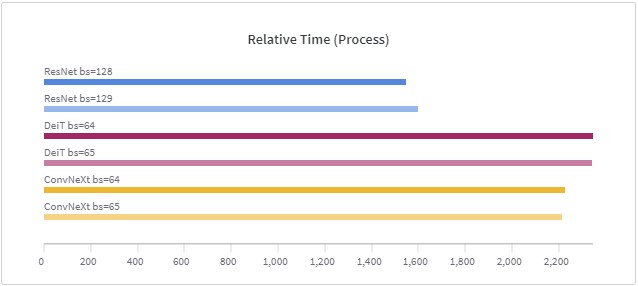
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。