支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3
4,095 views
尽管大语言模型发展速度很快,但是大多数模型对于上下文长度的支持都非常有限。长上下文对于很多任务来说都十分重要。如文档生成、多轮对话、代码生成等任务都需要较长的上下文输入才能取得较好的效果。

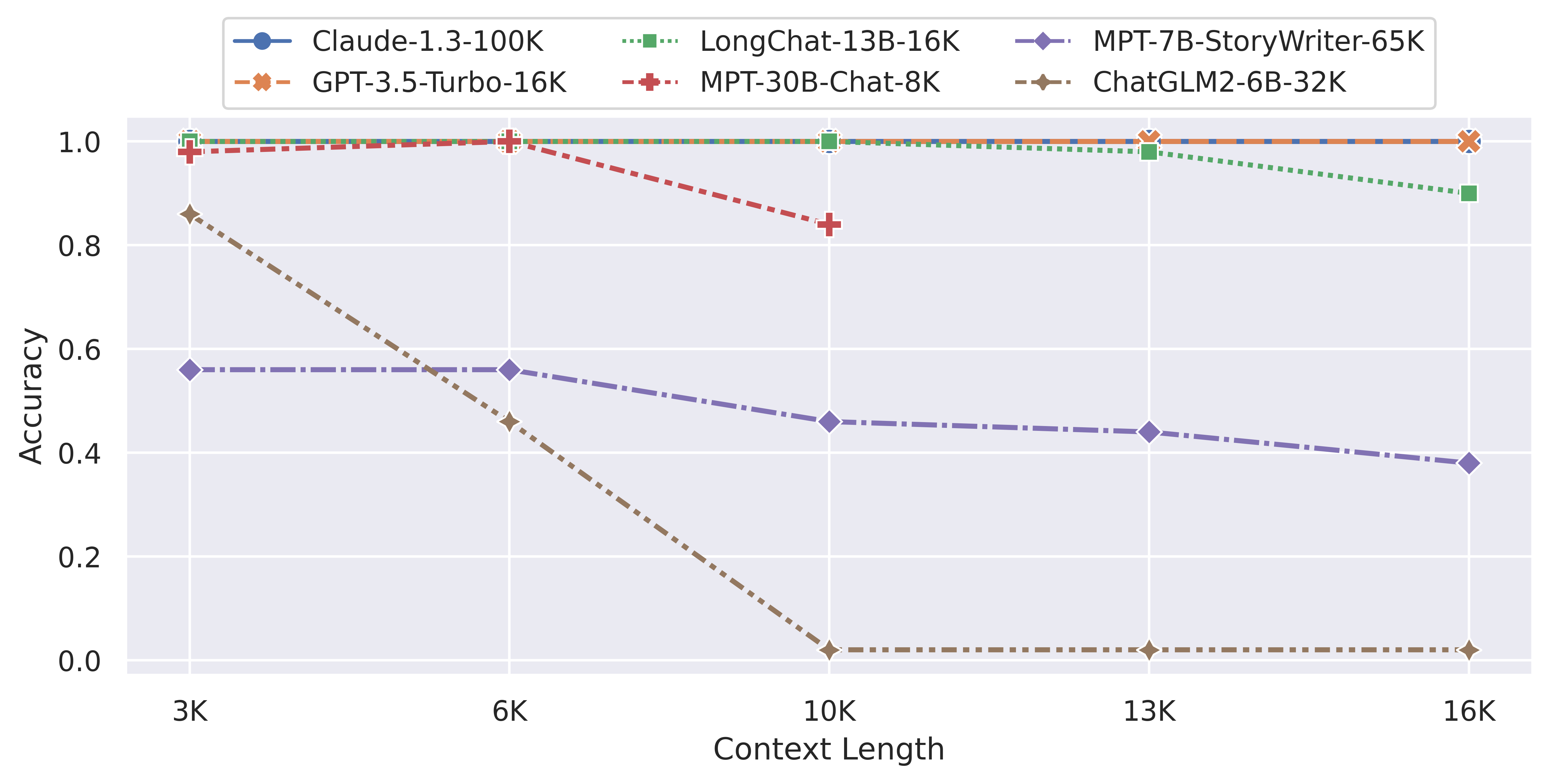
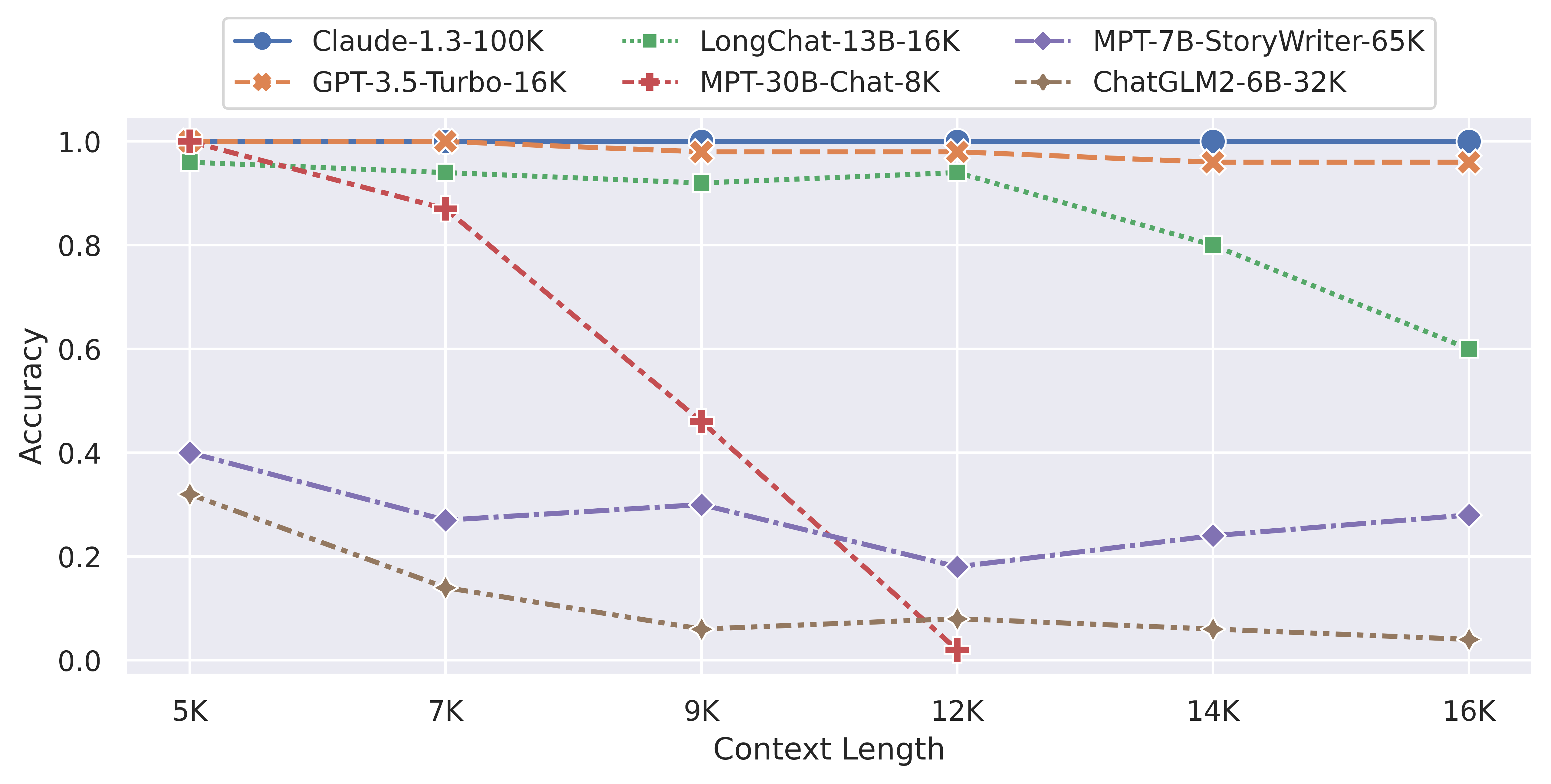
目前开源领域已经有一些模型宣称支持了8K甚至是更长的上下文。那么这些模型在长上下文的支持上表现到底如何?最近LM-SYS发布了LongChat-7B和LangChat-13B模型,最高支持16K的上下文输入。为了评估这两个模型在长上下文的表现,他们对很多模型在长上下文的表现做了评测,让我们看看这些模型的表现到底怎么样。
支持超长上下文对大语言模型(LLM)意味着什么
所谓LLM的上下文长度其实就是LLM背后模型的输入长度。大多数大语言模型的输入长度都在2K以内。以输入长度是2048为例。这个长度的含义是模型一次性接受输入的tokens数量为2048个。根据OpenAI官方的介绍,一般tokens换算到单词的比例是75%左右,这意味着2K模型的输入一般只能支持2048*0.75=1500个单词的输入(关于为什么LLM输入是token而不是单词可以参考:https://www.datalearner.com/blog/1051671195034710 )。