MistralAI正式官宣开源全球最大的混合专家大模型Mixtral 8x22B,官方模型上架HuggingFace,包含指令微调后的版本!
MistralAI是法国的一家人工智能大模型初创企业,他们开源的Mistral系列大模型获得了非常多的好评。此前,他们开源的全球最有影响力的Mixtral 8×7B-MoE模型开启了全球的MoE大模型的潮流。在四个月之后的2024年4月10日,MistralAI在推特上发出了一个磁力链接,大家下载之后发现这是全新的Mixtral 8x22B模型,一周后的今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
Mixtral-8x22B模型基本信息
Mixtral-8x22B模型是一个稀疏混合专家大模型(sparse Mixture-of-Experts,SMoE),总参数量1410,每次推理激活其中的390亿参数。
Mixtral-8x22B的主要特点总结如下:
- 支持多语言,在英语、法语、意大利语、德语和西班牙语上非常流程(实际测试也能支持基本的中文)
- 数学推理和代码能力大幅提升
- 天然支持function calling特性
- 支持64K超长上下文
- Apache2.0开源协议,真正的开源
这里顺便说一下,虽然MetaAI开源了Llama系列大模型,但是他们最新的开源协议增加了遵守贸易合规的条款,这意味着很多中国企业可能无法使用!而Mixtral 8x22B模型的Apache2.0可以理解为真正的可商用的开源协议,几乎没有限制使用!
Mixtral 8x22B模型的效果
Mixtral 8x22B模型是混合专家模型,因此它的推理显存大小要求和参数总规模是一致的,即1410亿参数,大约需要280GB显存,不会有优势。但是推理只激活其中的390亿参数,意味着这个模型的推理速度方面与390亿参数规模模型差不多。下图是官方展示的对比结果:
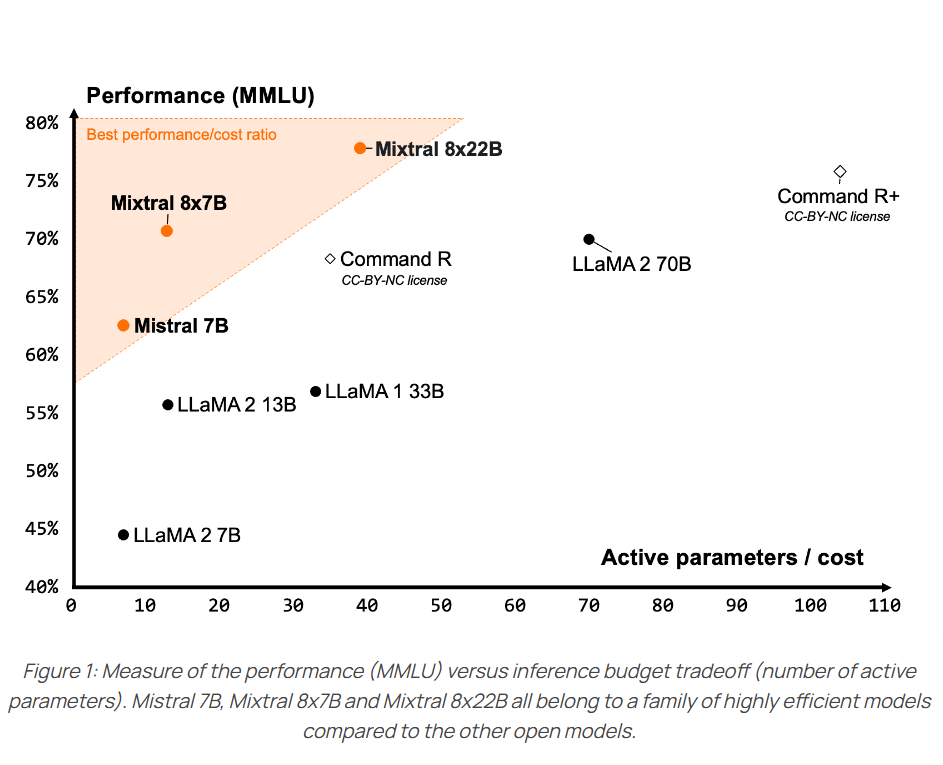
其中纵坐标是MMLU评分,横坐标是激活的参数数量,左上角区域意味着可以较少的参数获得更好的性能。
下图是DataLearnerAI收集的全球大模型排行结果(按照MMLU评分排序):
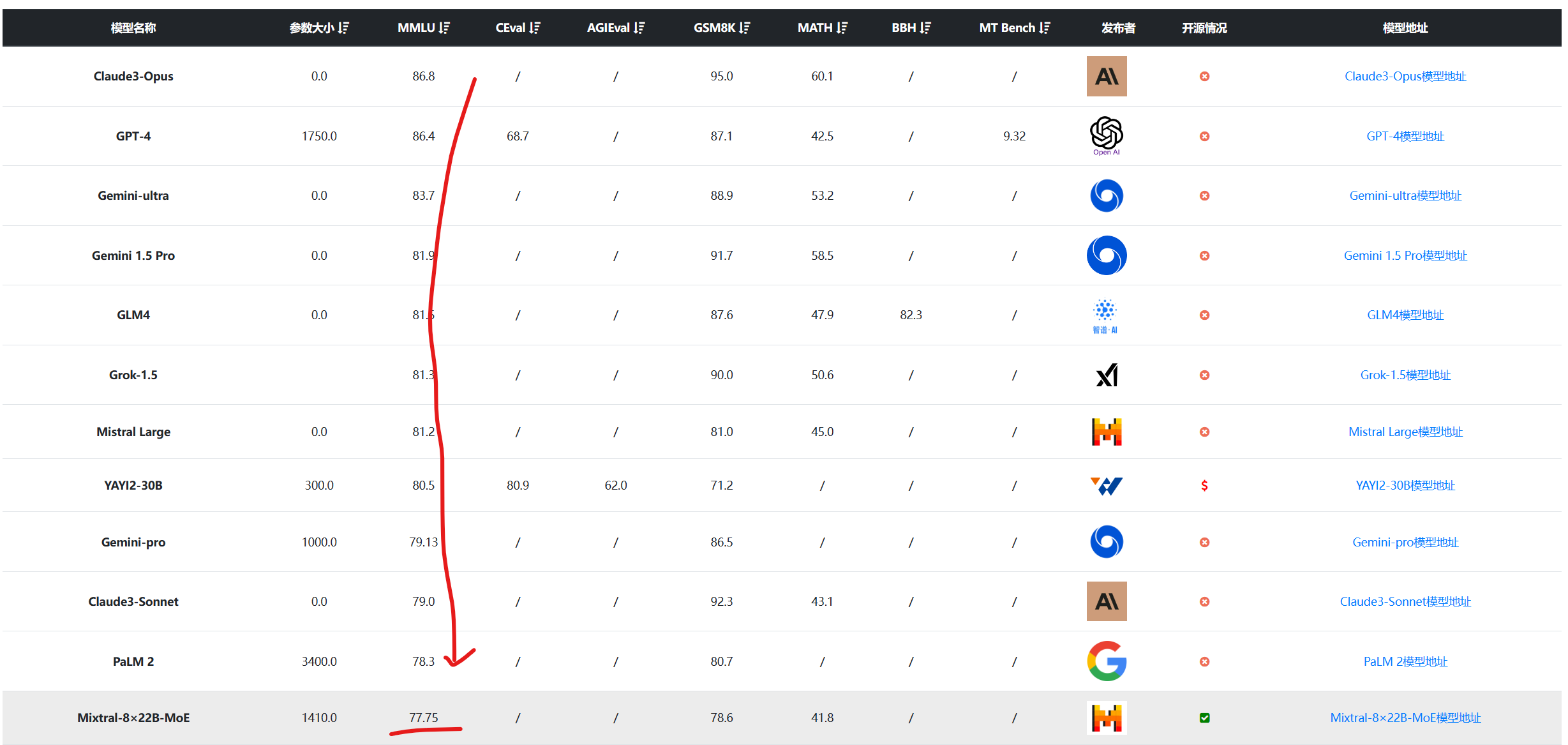
可以看到,MMLU得分77.5分,超过了Qwen1.5-72B-Chat,后者是聊天优化版本。尽管排名似乎没那么靠前,但是此前Mixtral-8×7B在开源领域的效果无人能比,所以可以看到这个成绩应该十分经得起考验。
与相应规模的开源模型对比结果如下:
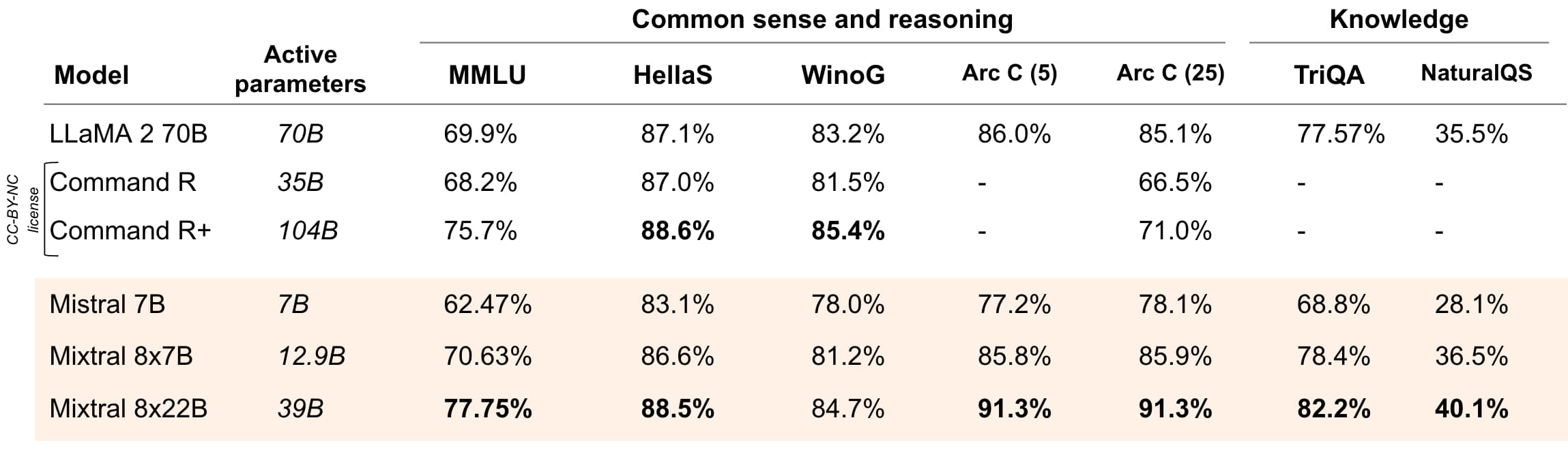
可以说除了部分评测不如Command R+外,Mixtral 8x22B模型在其它结果都是大幅领先的。要知道,Command R+虽然各项评测基准得分不高,但是在LM-SYS大模型匿名投票得分中是超过GPT-4早期版本的,这意味着Mixtral 8x22B模型很有可能在是实际使用中会很大惊喜(实话说,相比较很多刷榜的模型,MistralAI和MetaAI开源的模型评测得分虽然不是很好,但是实际应用要靠谱很多)。
Mixtral 8x22B模型多语言能力很强
MistralAI作为一家欧洲厂商,从一开始就支持欧洲的多国语言。本次发布的Mixtral 8x22B模型也不例外,在法语、德语、西班牙语等方面也是非常不错。
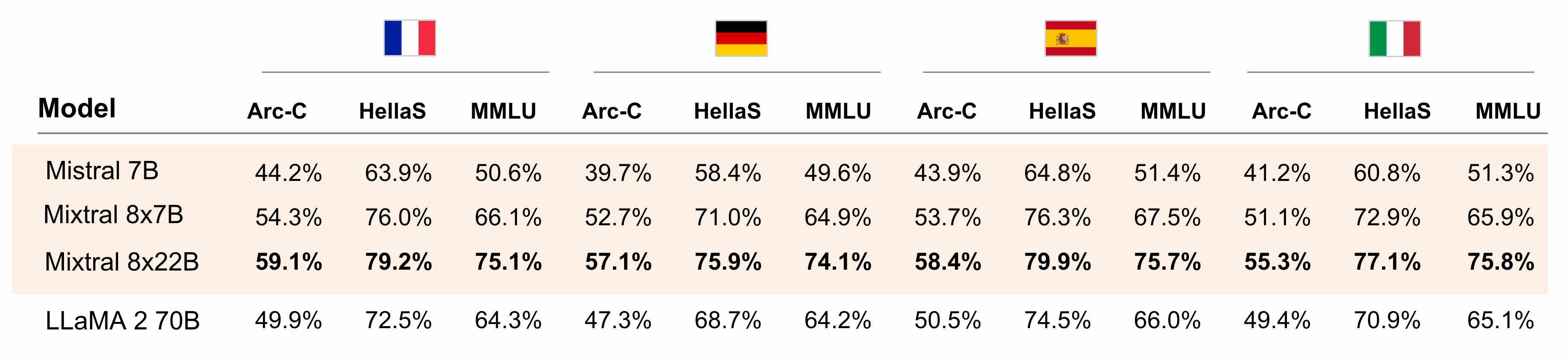
应该说,在开源领域是目前最靠谱的模型了。
Mixtral 8x22B模型大幅增强了推理和函数调用能力
随着大语言能力的增强,语义理解之外的能力越来越被大家所关注。其中数学推理和函数调用时两个十分重要的能力。前者在解决复杂问题、做AI Agent任务分解和规划时候都非常重要。后者则是AI Agent系统中使用对工具的支持的核心能力。
本次开源的Mixtral 8x22B模型在这两方面都做了大幅优化,不仅在数学推理方面评测提升很多,还天然支持工具的选择。
在GSM8K和Math的评测结果上,得分很高。而函数调用则是在prompt里面就可以。为此,Mixtral 8x22B模型的tokenizer 使用了更多的特殊标记(tokens),主要包括:
[TOOL_CALLS]
[AVAILABLE_TOOLS]
[/AVAILABLE_TOOLS]
[TOOL_RESULT]
[/TOOL_RESULTS]
因此代码使用方面也有了大幅的变化,具体使用工具的代码参考附录。
Mixtral 8x22B模型开源情况
MistralAI官方开源了2个版本的模型,一个是基础的预训练结果,一个是针对指令优化的模型。具体的开源地址参考DataLearnerAI模型信息卡:
Mixtral 8x22B模型:https://www.datalearner.com/ai-models/pretrained-models/Mixtral-8%C3%9722B-MoE Mixtral-8x22B-Instruct-v0_1:https://www.datalearner.com/ai-models/pretrained-models/Mixtral-8x22B-Instruct-v0_1
此外,微软基于Mixtral 8x22B模型进行后训练得到的WizardLM-2 8x22B模型在MT-Bench评分上甚至超过了GPT-4早期版本,匿名投票得分开源第一!WizardLM-2具体信息参考:https://www.datalearner.com/blog/1051713245748504
附录:Mixtral 8x22B的函数调用代码示例
需要注意,在instruct模型中这个支持会好一点,所以用instruct版本。
from transformers import AutoModelForCausalLM
from mistral_common.protocol.instruct.messages import (
AssistantMessage,
UserMessage,
)
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.tokens.instruct.normalize import ChatCompletionRequest
device = "cuda" # the device to load the model onto
tokenizer_v3 = MistralTokenizer.v3()
mistral_query = ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
)
)
],
messages=[
UserMessage(content="What's the weather like today in Paris"),
],
model="test",
)
encodeds = tokenizer_v3.encode_chat_completion(mistral_query).tokens
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x22B-Instruct-v0.1")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
sp_tokenizer = tokenizer_v3.instruct_tokenizer.tokenizer
decoded = sp_tokenizer.decode(generated_ids[0])
print(decoded)
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
