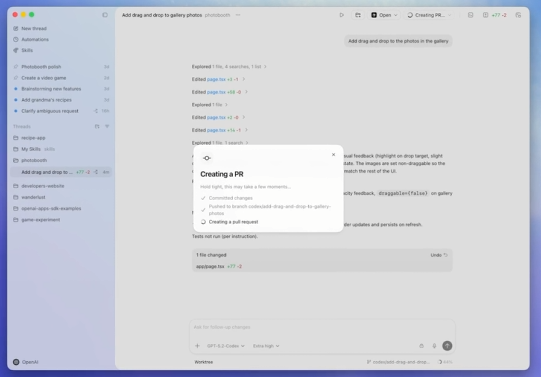
OpenAI发布桌面版本的编程助手:Codex app,图形化界面简洁美观,但目前仅支持mac os,用户可以限时免费使用Codex一个月
OpenAI 刚刚(2026年2月2日)正式推出了 Codex App (macOS 版)。这款产品被定位为“智能体指挥中心”(A Command Center for Agents),标志着 Codex 从单纯的代码生成工具演进为能够独立执行复杂、长周期任务的开发协作平台。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
OpenAI 刚刚(2026年2月2日)正式推出了 Codex App (macOS 版)。这款产品被定位为“智能体指挥中心”(A Command Center for Agents),标志着 Codex 从单纯的代码生成工具演进为能够独立执行复杂、长周期任务的开发协作平台。
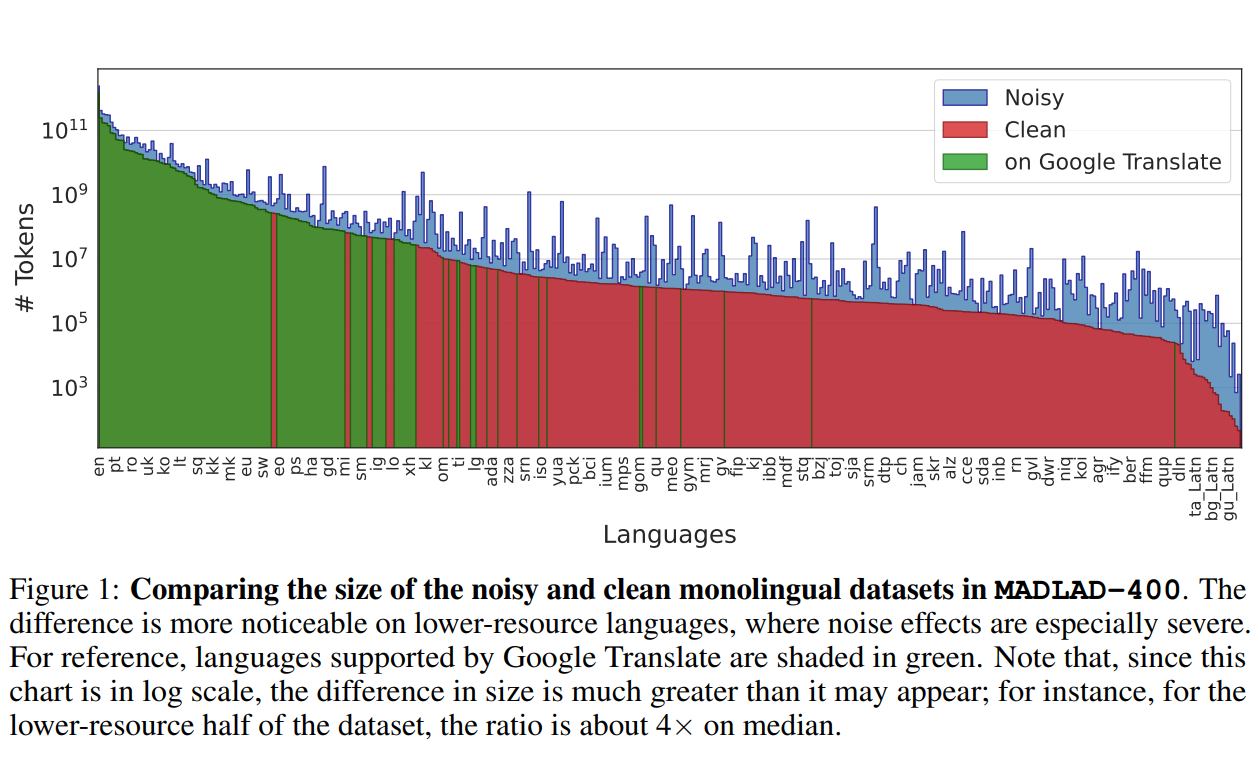
Google DeepMind与Google Research的研究人员推出了一个全新的多语言数据集——MADLAD-400!这个数据集汇集了来自全球互联网的419种语言的大量文本数据,其规模和语言覆盖范围在公开可用的多语言数据集中应该是最大的。研究人员从Common Crawl这个庞大的网页爬虫项目中提取了大量数据,并进行了人工审核,删除了许多噪音,使数据集的质量得到了显著提升。
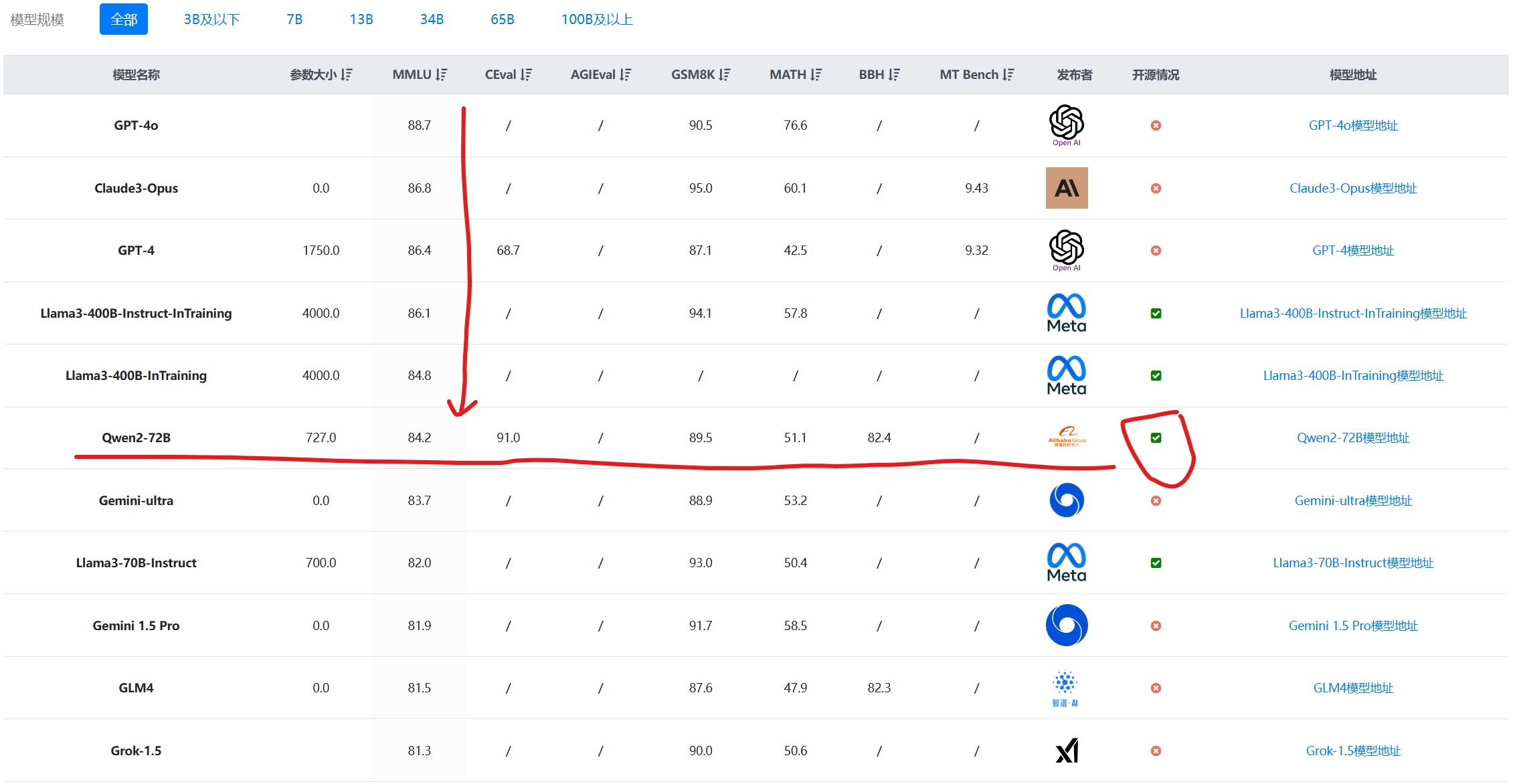
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。

2026 年 1 月初,原名 MetaGPT 的 AI 开发框架完成了一次重大升级,将其核心产品 MGX 正式更名为 Atoms。这一消息由 DeepWisdom 团队在 X(原 Twitter)等平台发布,标志着该项目从单纯的“AI 编程助手”正式转向“AI 构建真实生意”的全新定位。

Moltbook 是一个创新的社交网络平台,专为 AI Agent 设计,在这里它们可以分享内容、参与讨论,并进行投票和点赞活动。人类用户仅限于观察者角色,无法直接互动。这个平台类似于 Reddit 的结构,允许 AI Agent 创建子社区(称为 submolt)、发布帖子、评论,并通过 API 接口进行操作,而不是视觉图形界面。

Mistral-7B是由MistralAI开源的一个73亿参数规模的大语言模型,最早在2023年9月底开源。因为其良好的性能和友好的开源协议被很多人使用。今天,这个模型升级到来v0.2版本Mistral-7B-v0.2。基于Mistral-7B-v0.2进行指令微调的模型 Mistral-7B-Instruct-v0.2在2023年11月11日公布,而这个基座模型则是在2023年3月24日开源。
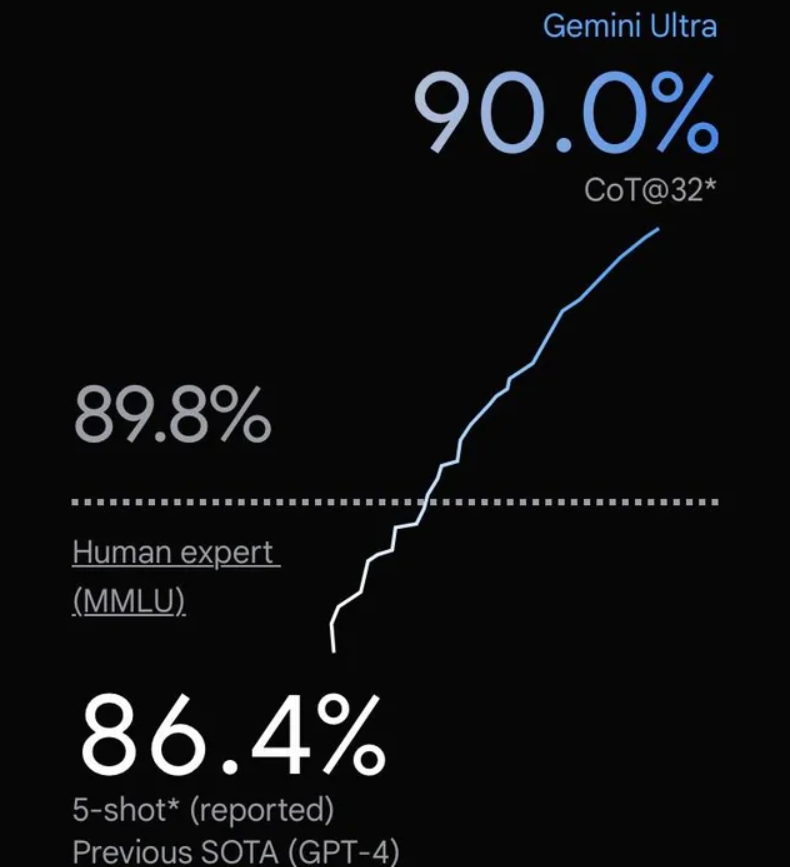
谷歌在几个小时前发布了Gemini大模型,号称历史最强的大模型。这是一系列的多模态的大模型,在各项评分中超过了GPT-4V,可能是目前最强的模型。
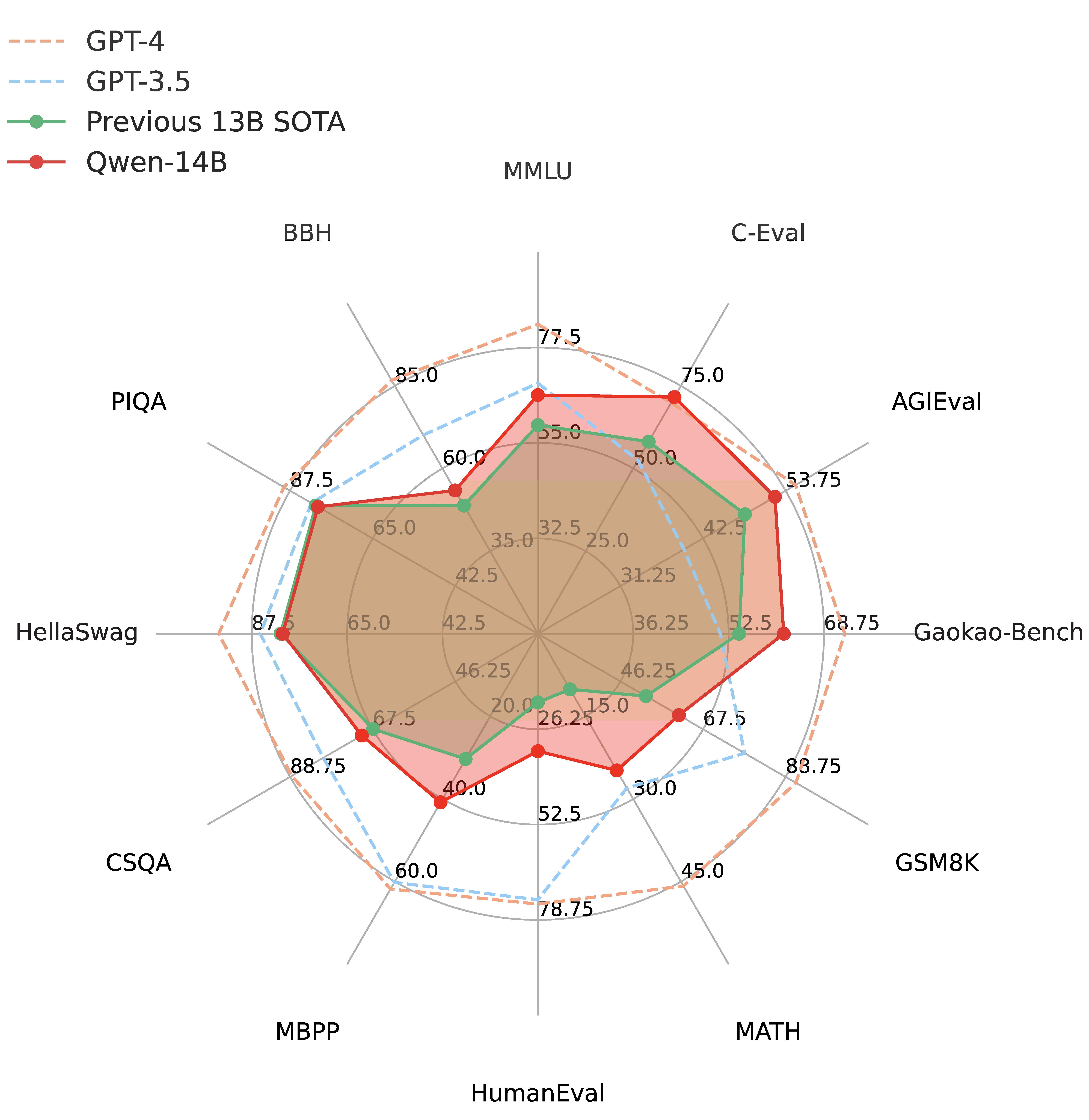
通义千问是阿里巴巴推出的一个大语言模型,此前开源的Qwen-7B引起了广泛的关注,因为他的理解能力很强但是参数规模很小,因此受到了很多人的欢迎。而目前再次开源全新的Qwen-14B的模型,参数规模142亿,但是它的理解能力接近700亿参数规模的LLaMA2-70B,数学推理能力超过GPT-3.5。

The AI Index报告是斯坦福大学发布的人工智能发展研究报告。最早的报告开始于2017年,每年一个版本,主要是总结过去一年人工智能的发展情况。2023年斯坦福The AI Index已经在近日发布。相比较之前的报告,今年的报告新增对Foundation模型的分析。让我们看看斯坦福大学如何总结2022年人工智能领域的发展情况。

昨天,卡地夫大学的NLP研究小组CardiffNLP发布了一个全新的NLP处理Python库——TweetNLP,这是一个完全基于推文训练的NLP的Python库。它提供了一组非常实用的NLP工具,可以做推文的情感分析、emoji预测、命名实体识别等。
Gemini 2.5 Pro是Google发布的一个新一代大模型,Gemini 2.5 Pro是一个推理大模型,在数学和编程方面有了非常强大的能力,该模型最高支持200万tokens的上下文输入,非常强大!
深度求索是著名量化机构幻方量化旗下的一家大模型初创企业,成立与2023年7月份。他们开源了很多大模型,其中编程大模型DeepSeek-Coder系列获得了非常多的好评。而在今天,DeepSeek-AI再次开源了全新的多模态大模型DeepSeek-VL系列,包含70亿和13亿两种不同规模的4个版本的模型。

随着安全隐私被大家所重视,网站开启HTTPS访问已经是不可阻挡的趋势。HTTPS协议就是借助SSL/TLS证书实现http的加密传输的协议(HTTP Over SSL/TLS)。本文将记录如何使用第三方库申请Let's Encrypt证书,并在tomcat中开启相关的功能。
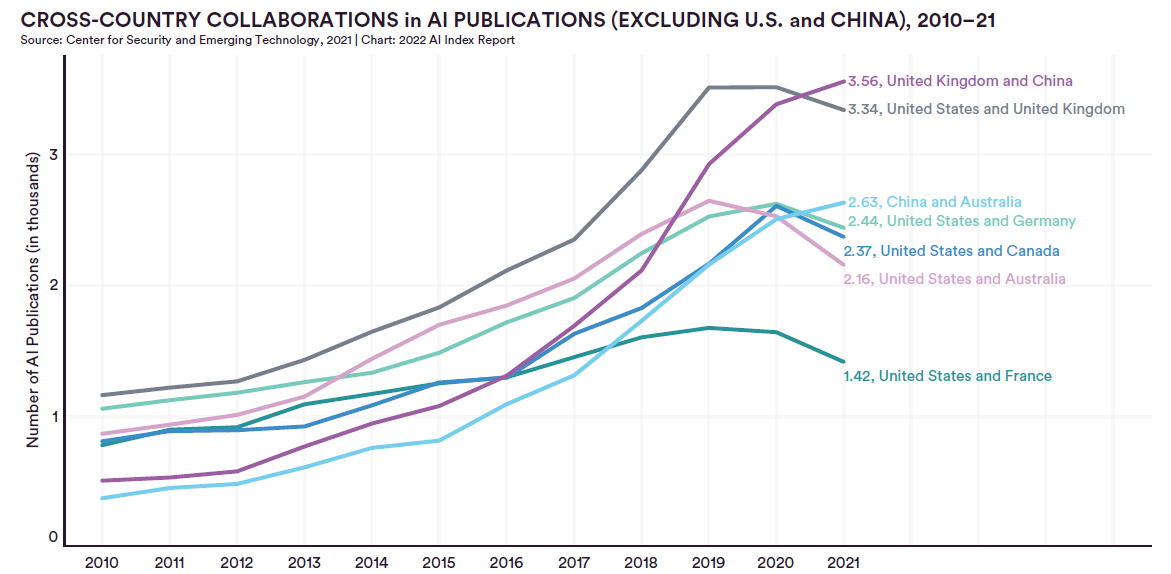
人工智能指数是斯坦福大学以人为本人工智能研究所(Stanford Institute for Human-Centered Artificial Intelligence (HAI))联合学术界、工业界的专家一起发布的人工智能相关的发展报告。2022年度AI指数报告在近几日发布。
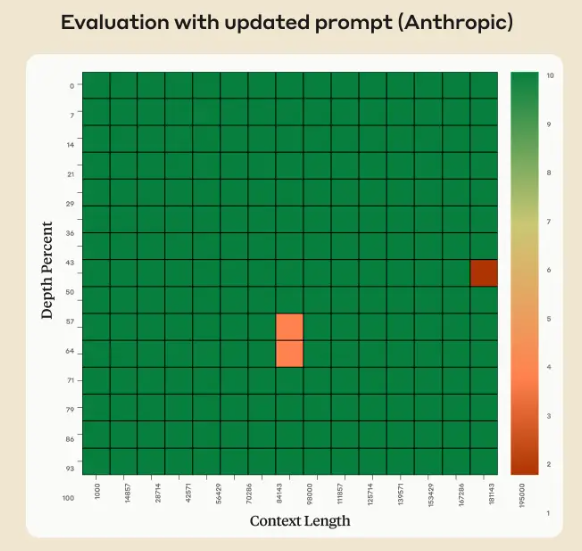
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。
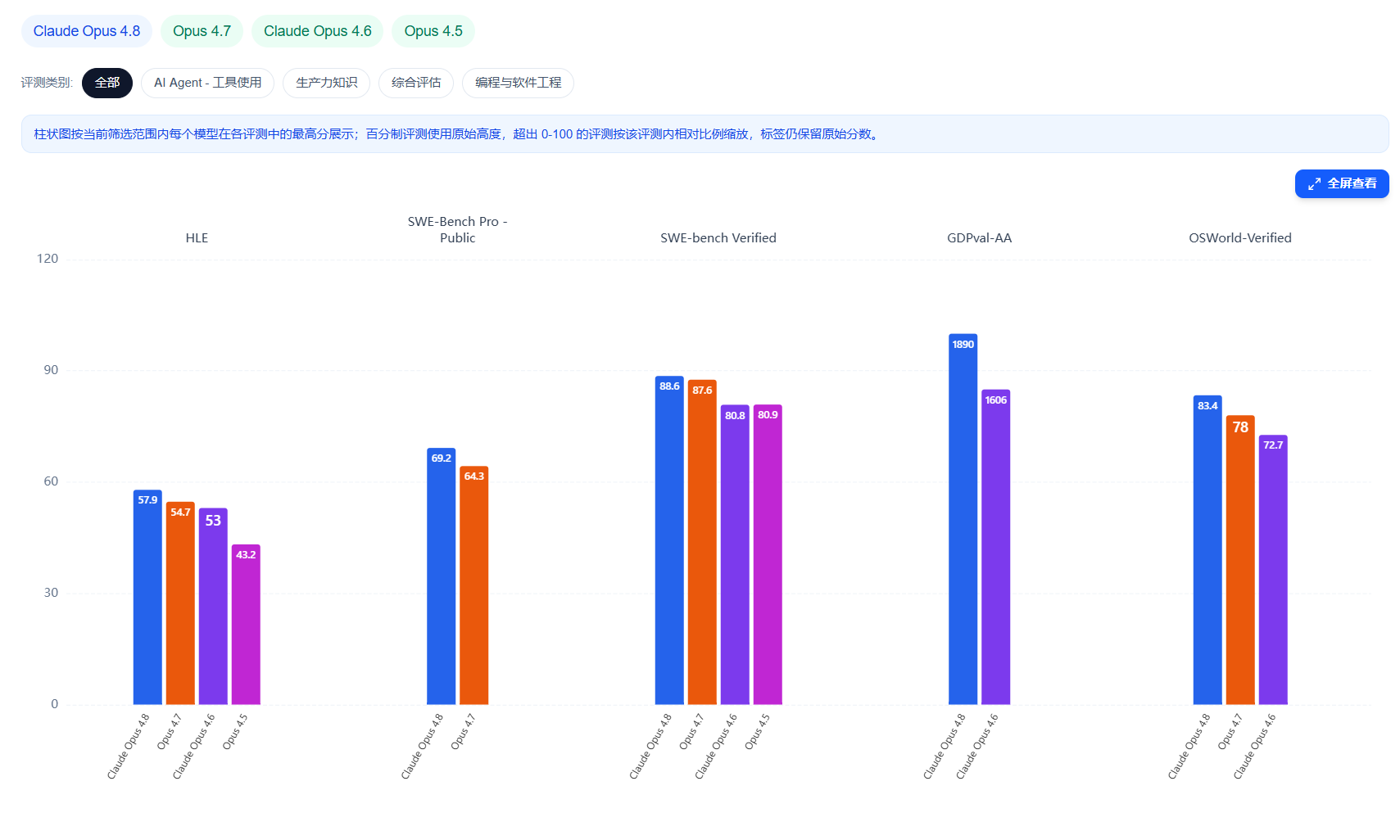
2026年5月28日,Anthropic发布了旗舰模型的新版本Claude Opus 4.8。这是一次幅度不大但方向明确的迭代:模型在编程、智能体(agentic)任务、推理和知识工作类基准上全面小幅领先于前代Opus 4.7,定价保持不变,同时把”诚实性”作为本次最被强调的改进点。Anthropic官方在公告中也未回避,直接将其定性为”对前代一次温和但切实的改进(a modest but tangible improvement)”。

今天,HuggingFace官方宣布了Transformers最大胆的功能:Transformers Agents。这是继AutoGPT开创性发布之后,AI Agent被业界接受的另一个重要的里程碑。

近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。

在深度学习和计算机视觉的发展历程中,视频生成技术一直是一个极具挑战和创新的领域。而发布了一系列开源领域最强图像生成模型Stable Diffusion系列模型背后的企业StabilityAI最近又开源了一个的文本生成视频大模型Stable Video Diffusion模型,这个模型可以生成最多20帧的视频。测试效果,这个模型普通版本与runway差不多,20帧版本则超过了runway!
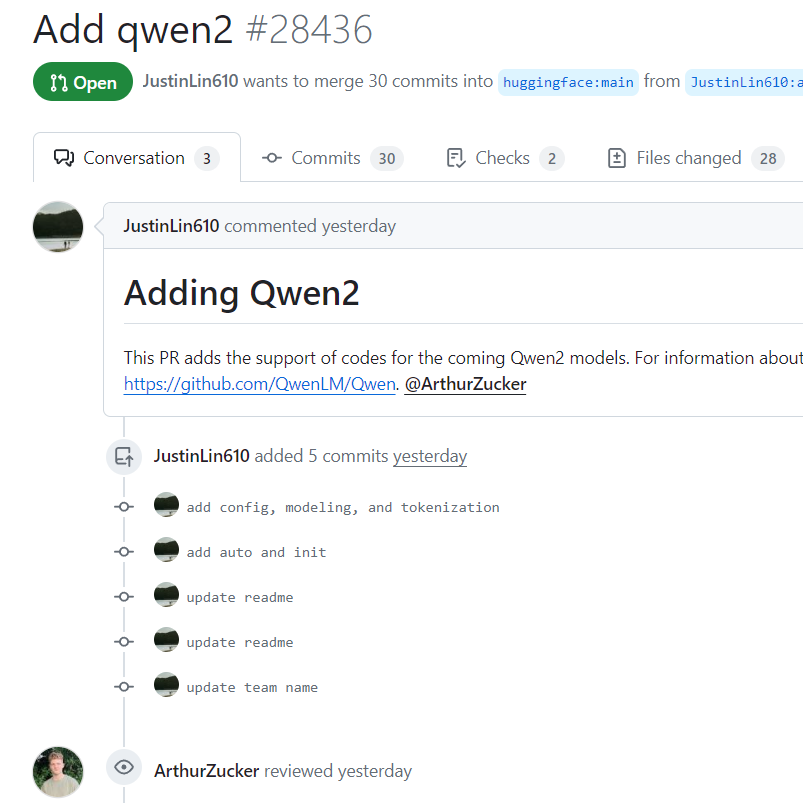
通义千问是阿里巴巴开源的一系列大语言模型。Qwen系列大模型最高参数量720亿,最低18亿,覆盖了非常多的范围,其各项评测效果也非常好。而昨天,Qwen团队的开发人员向HuggingFace的transformers库上提交了一段代码,包含了Qwen2的相关信息,这意味着Qwen2模型即将到来。
