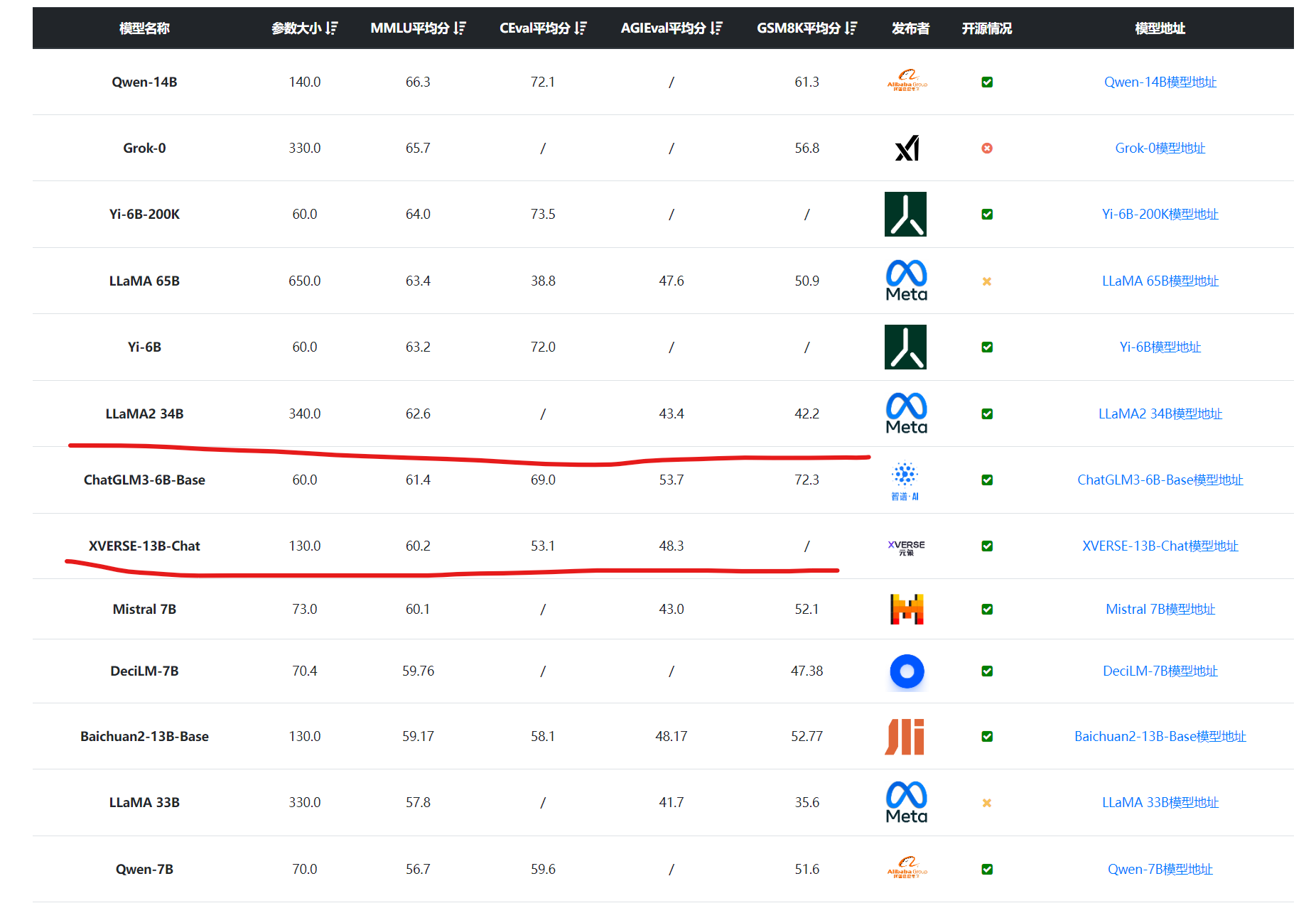
Open ChatGPT:一个整合了GPT-4和多模态能力的ChatGTP服务商,免费可用,月租也很合理~
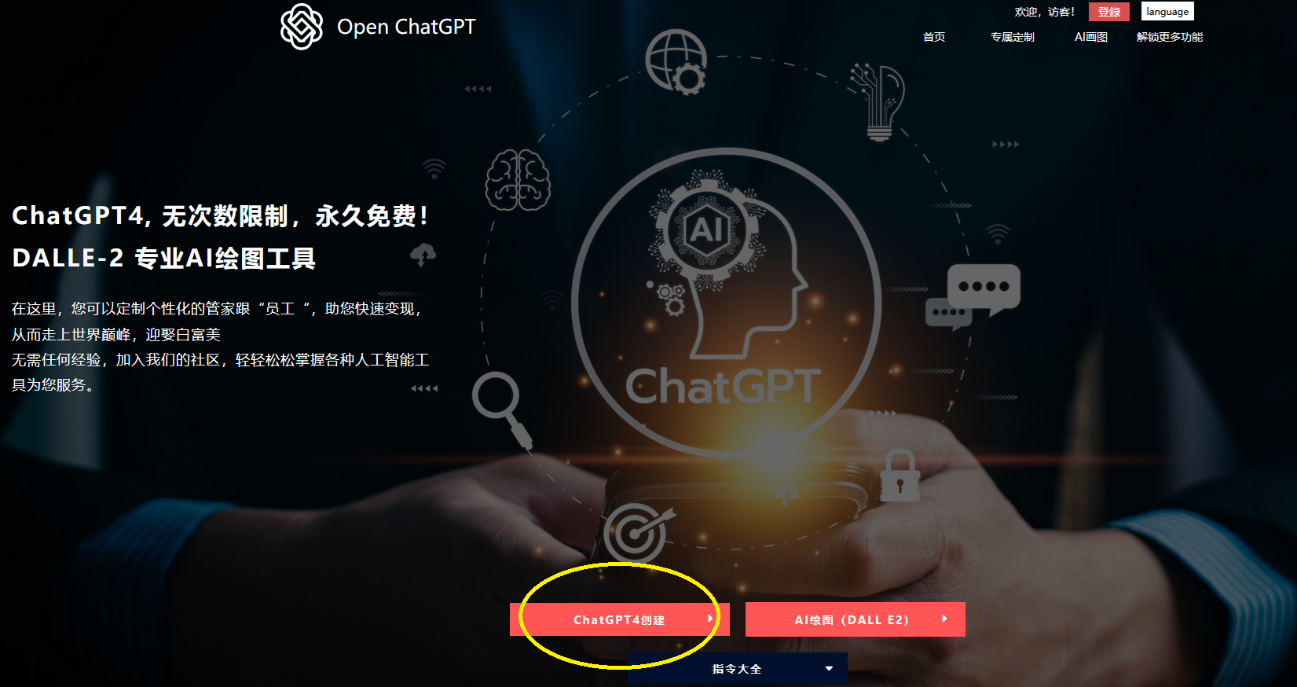
恰巧,我最近发现了一个网站——Open ChatGPT,网址是 https://open-chat-gpt.com/cn。 简单来说,该网站调用 ChatGPT-4 (最新版) 的 API,让用户创建各种指定角色,服务于生活跟工作。不仅如此,还支持连ChatGPT官网都还没用上的AI画图功能。目前,相比其他网页各种限制使用次数的,这网站非常可贵在于可以无限次免费使用ChatGPT-4...