
标签平滑(Label Smoothing)——分类问题中错误标注的一种解决方法
在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,可以提高模型效果。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,可以提高模型效果。
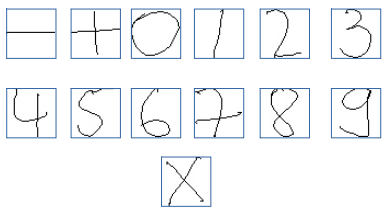
本文是发在Medium上的一篇博客:《Handwritten Equation Solver using Convolutional Neural Network》。本文是原文的翻译。这篇文章主要教大家如何使用keras训练手写字符的识别,并保存训练好的模型到本地,以及未来如何调用保存到模型来预测。

Tensorflow中tf.data.Dataset是最常用的数据集类,我们也使用这个类做转换数据、迭代数据等操作。本篇博客将简要描述这个类的使用方法。
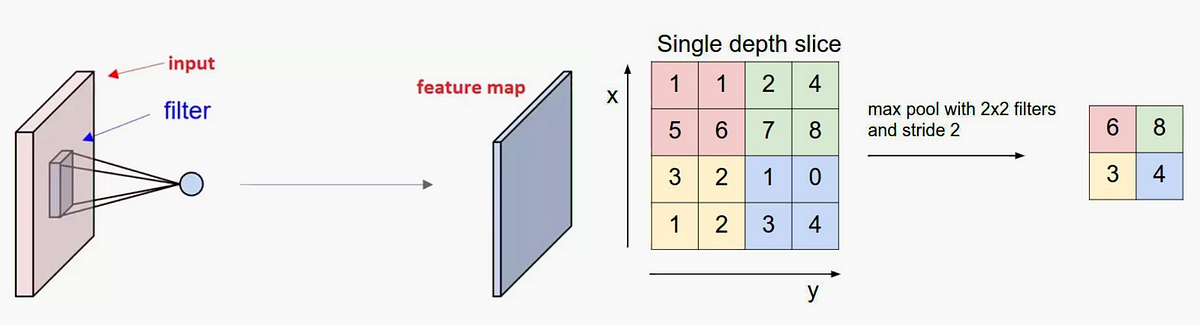
卷积神经网络是图像识别领域最重要的深度学习技术。也可以说是是本轮深度学习浪潮开始点。本文总结了CNN的三种高级技巧,分别是空洞卷积、显著图和反卷积技术。
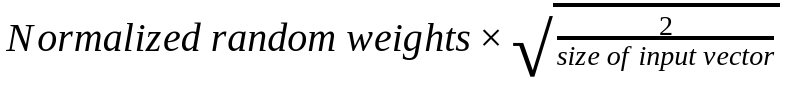
深度学习的初始化非常重要,这篇博客主要描述两种初始化方法:一个是Kaiming初始化,一个是LSUV方法。文中对比了不同初始化的效果,并将每一种初始化得到的激活函数的输出都展示出来以查看每种初始化对层的输出的影响。当然,作者最后也发现如果使用了BatchNorm的话,不同的初始化方法结果差不多。说明使用BN可以使得初始化不那么敏感了。
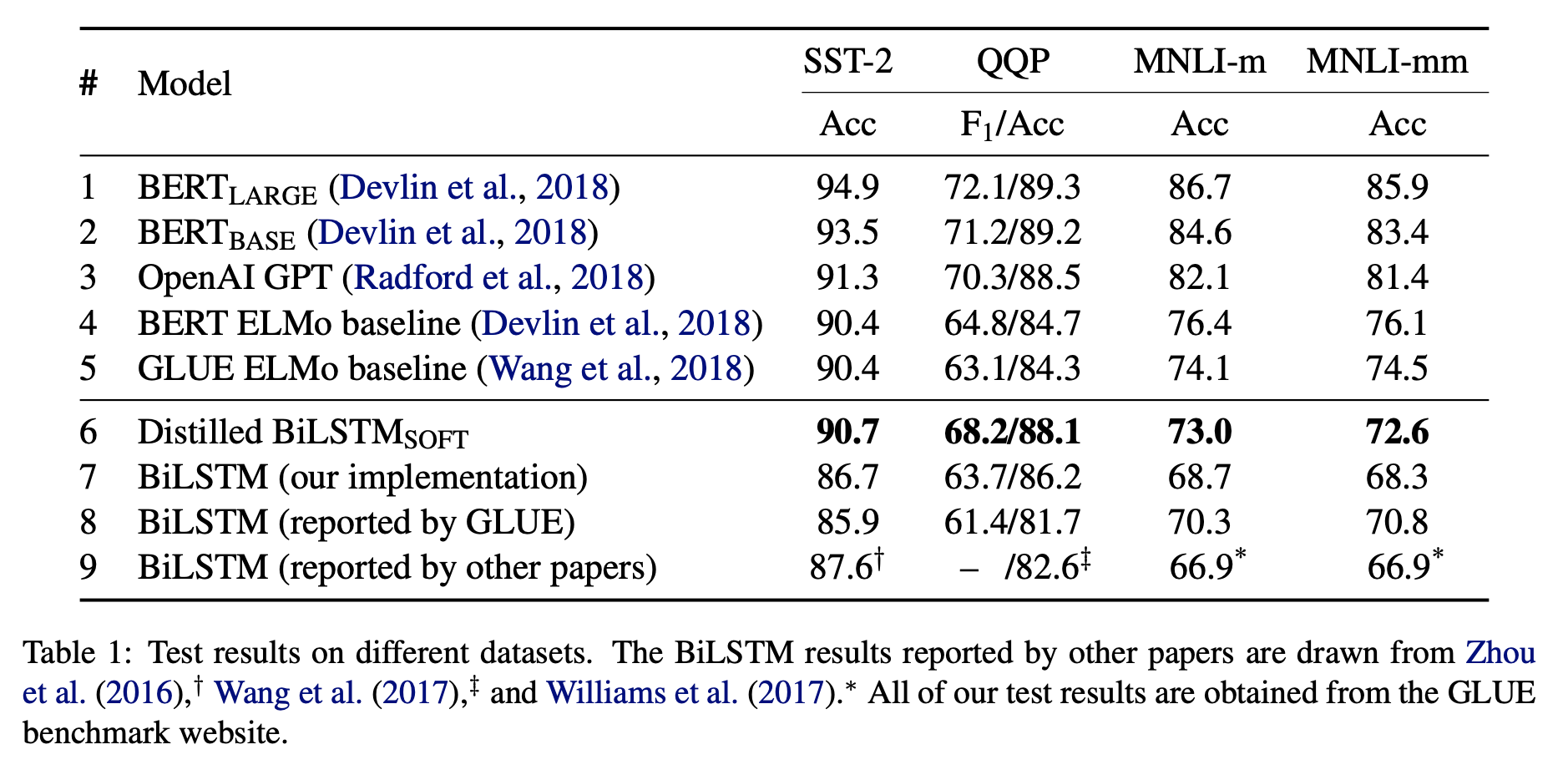
BERT是很好的模型,但是它的参数太大,网络结构太复杂。在很多没有GPU的环境下都无法部署。本文讲的是如何利用BERT构造更好的小的逻辑回归模型来代替原始BERT模型,可以放入生产环境中,以节约资源。
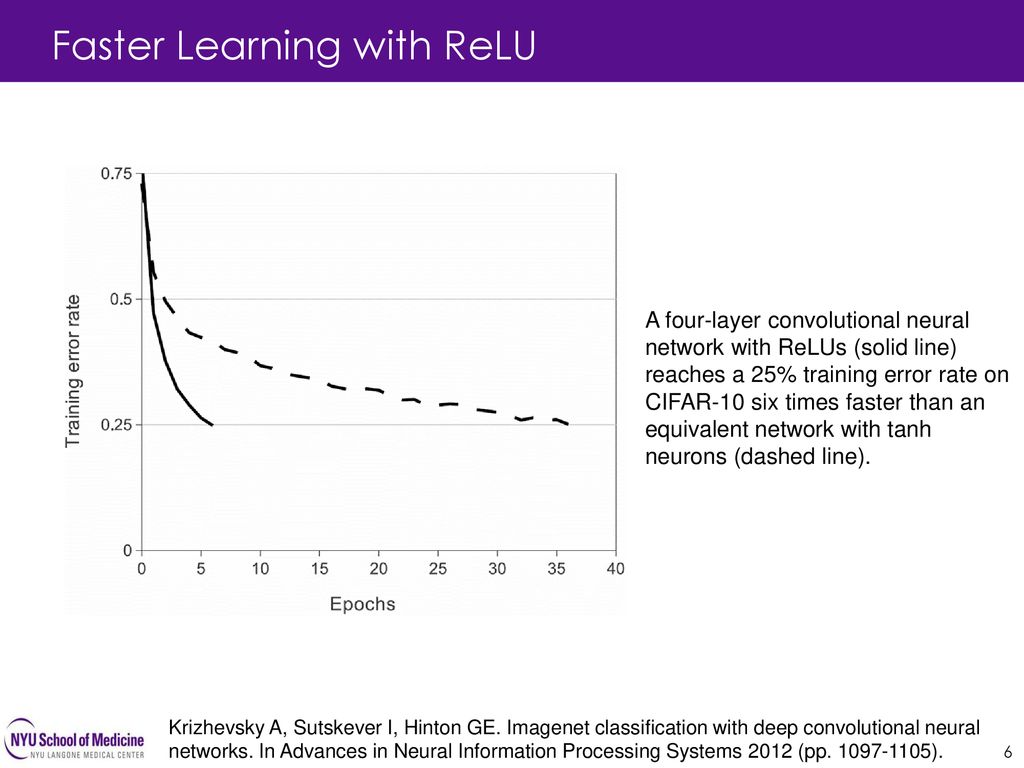
2012年发表的AlexNet可以算是开启本轮深度学习浪潮的开山之作了。由于AlexNet在ImageNet LSVRC-2012(Large Scale Visual Recognition Competition)赢得第一名,并且错误率只有15.3%(第二名是26.2%),引起了巨大的反响。相比较之前的深度学习网络结构,AlexNet主要的变化在于激活函数采用了Relu、使用Dropout代替正则降低过拟合等。本篇博客将根据其论文,详细讲述AlexNet的网络结构及其特点。
AdaBoost,全称是“Adaptive Boosting”,由Freund和Schapire在1995年首次提出,并在1996发布了一篇新的论文证明其在实际数据集中的效果。这篇博客主要解释AdaBoost的算法详情以及实现。它可以理解为是首个“boosting”方式的集成算法。是一个关注二分类的集成算法。
深度学习是目前最火的算法领域。他在诸多任务中取得的骄人成绩使得其进化越来越好。本文收集深度学习中的经典算法,以及相关的解释和代码实现。
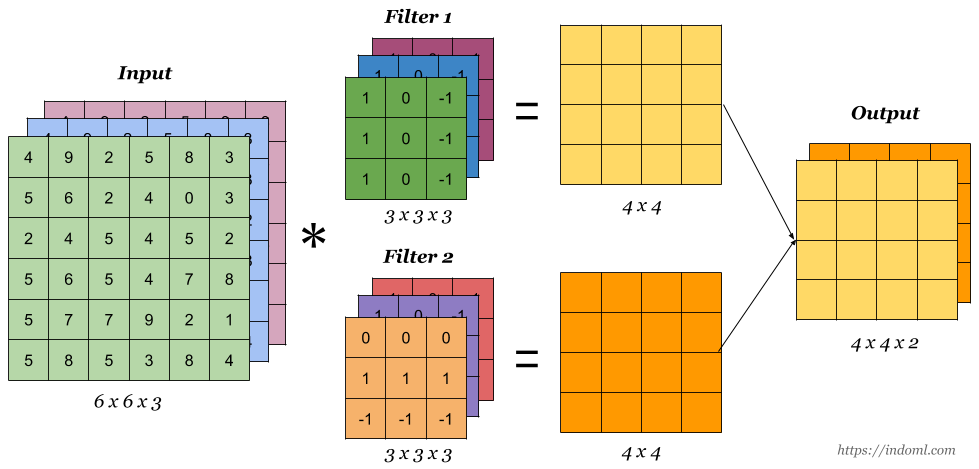
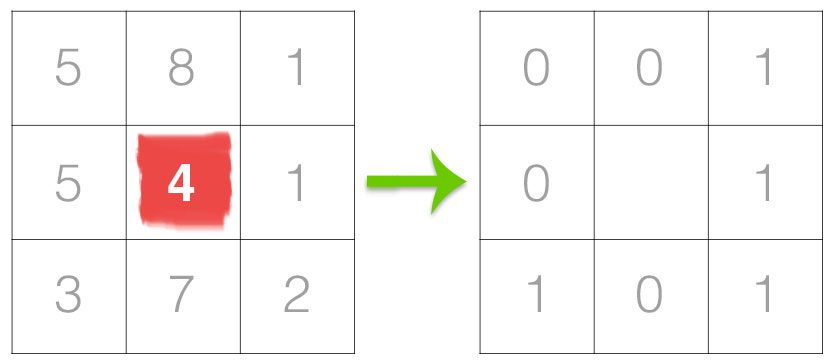
卷积操作的维度计算是定义神经网络结构的重要问题,在使用如PyTorch、Tensorflow等深度学习框架搭建神经网络的时候,对每一层输入的维度和输出的维度都必须计算准确,否则容易出错,这里将详细说明相关的维度计算。
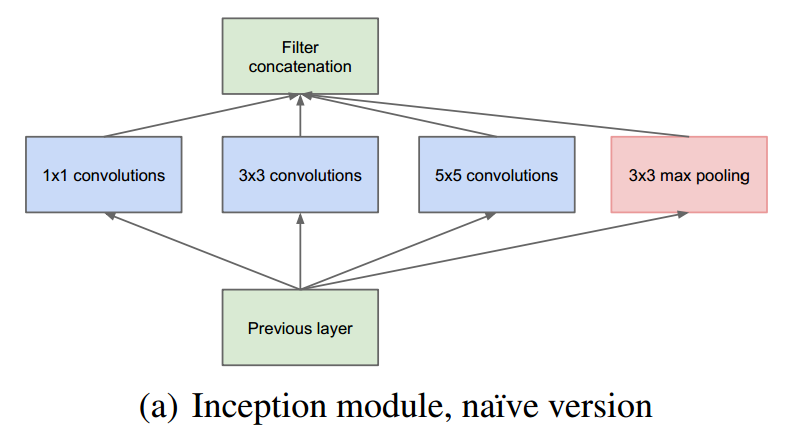
GoogLeNet是谷歌在2014年提出的一种CNN深度学习方法,它赢得了2014年ILSVRC的冠军,其错误率要低于当时的VGGNet。与之前的深度学习网络思路不同,之前的CNN网络的主要目标还是加深网络的深度,而GoogLeNet则提出了一种新的结构,称之为inception。GoogLeNet利用inception结构组成了一个22层的巨大的网络,但是其参数却比之前的如AlexNet网络低很多。是一种非常优秀的CNN结构。
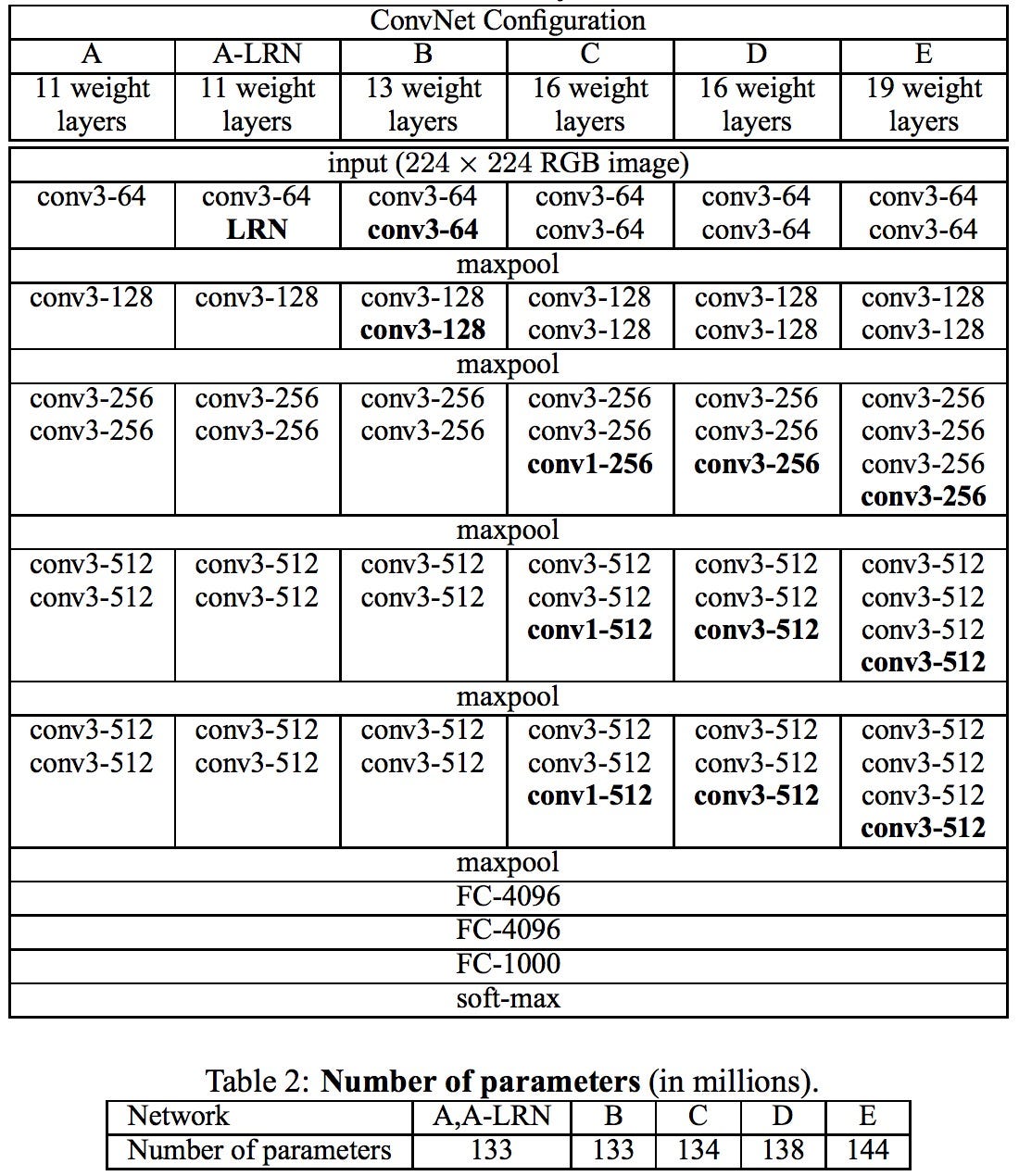
VGGNet(Visual Geometry Group)是2014年又一个经典的卷积神经网络。VGGNet最主要的目标是试图回答“如何设计网络结构”的问题。随着AlexNet提出,很多人开始利用卷积神经网络来解决图像识别的问题。一般的做法都是重复几层卷积网络,每个卷积网络之后接一些池化层,最后再加上几个全连接层。而VGGNet的提出,给这些结构设计带来了一些标准参考。
1998年,LeCun提出了LeNet-5网络用来解决手写识别的问题。LeNet-5被誉为是卷积神经网络的“Hello Word”,足以见到这篇论文的重要性。在此之前,LeCun最早在1989年提出了LeNet-1,并在接下来的几年中继续探索,陆续提出了LeNet-4、Boosted LeNet-4等。本篇博客将详解LeCun的这篇论文,并不是完全翻译,而是总结每一部分的精华内容。
深度学习本质上是表示学习,它通过多层非线性神经网络模型从底层特征中学习出对具体任务而言更有效的高级抽象特征。针对一个具体的任务,我们往往会遇到这种情况:需要用一个模型学习出特征表示,然后将学习出的特征表示作为另一个模型的输入。这就要求我们会获取模型中间层的输出,下面以具体代码形式介绍两种具体方法。
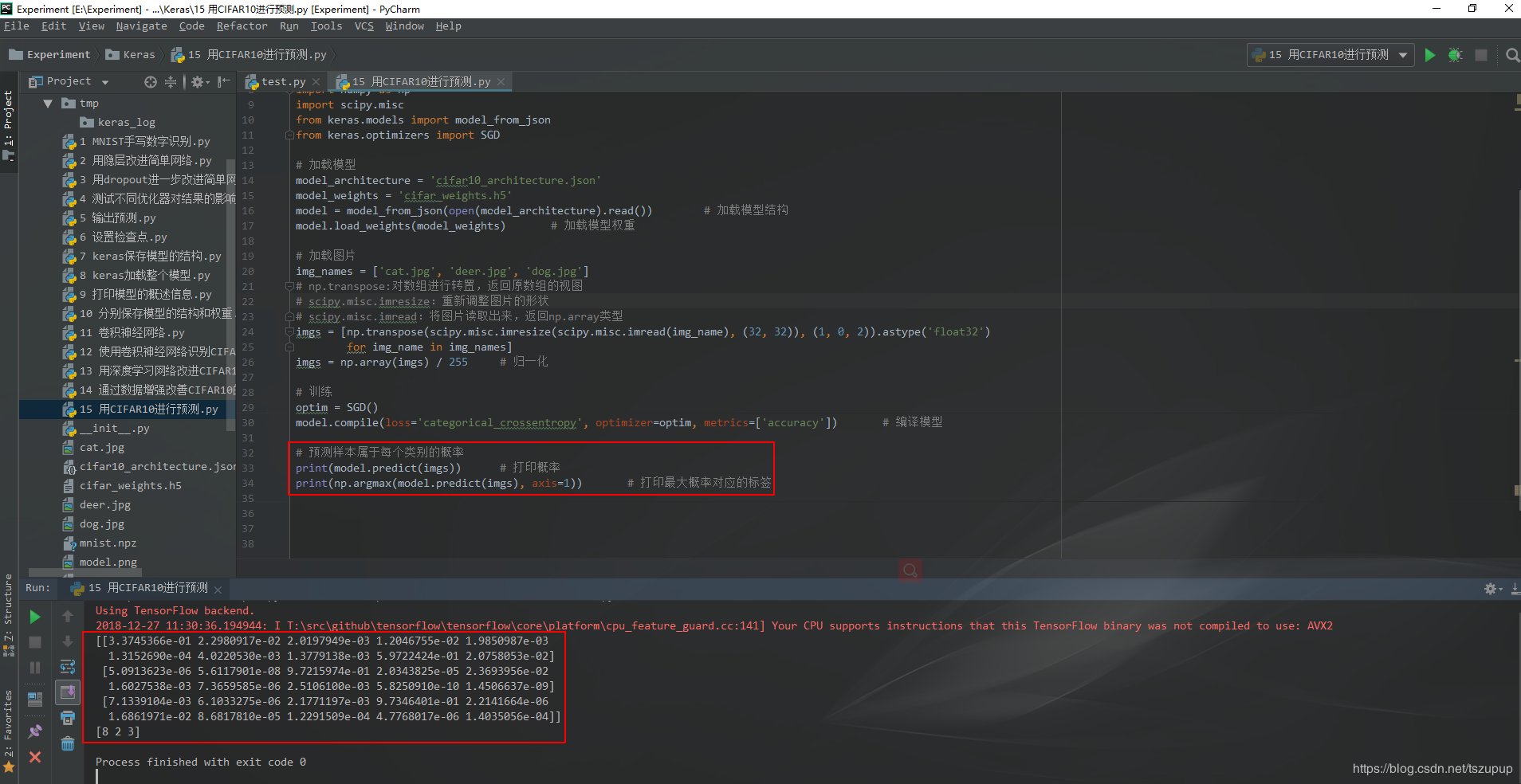
Keras中predict()方法和predict_classes()方法的区别
Sequence-to-Sequence model
tf.nn.softmax_cross_entropy_with_logits函数