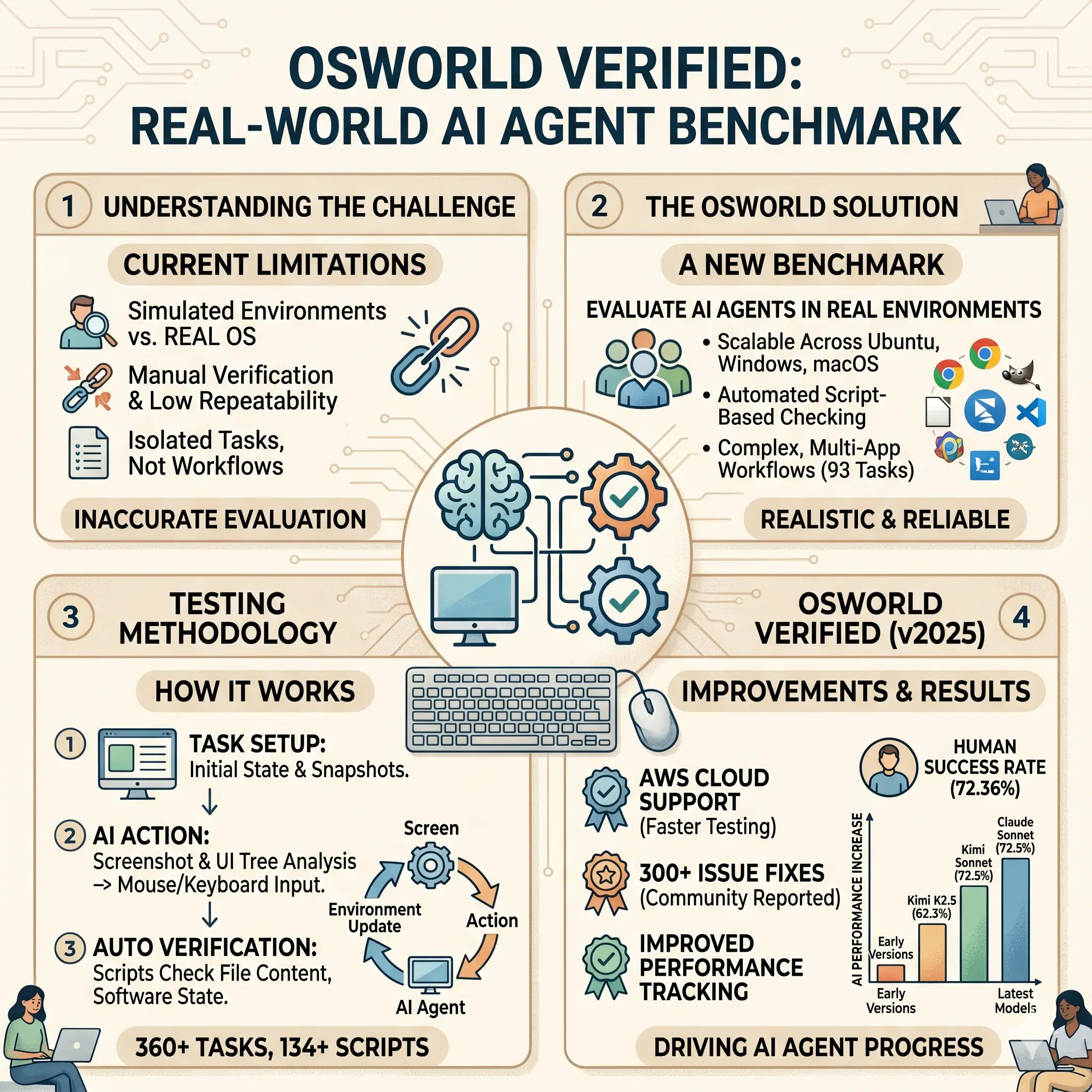
MistralAI开源240亿参数的多模态大模型Mistral-Small-3.1-24B:评测结果与GPT-4o-mini与Gemma 3 27B有来有回,开源且免费商用,支持24种语言
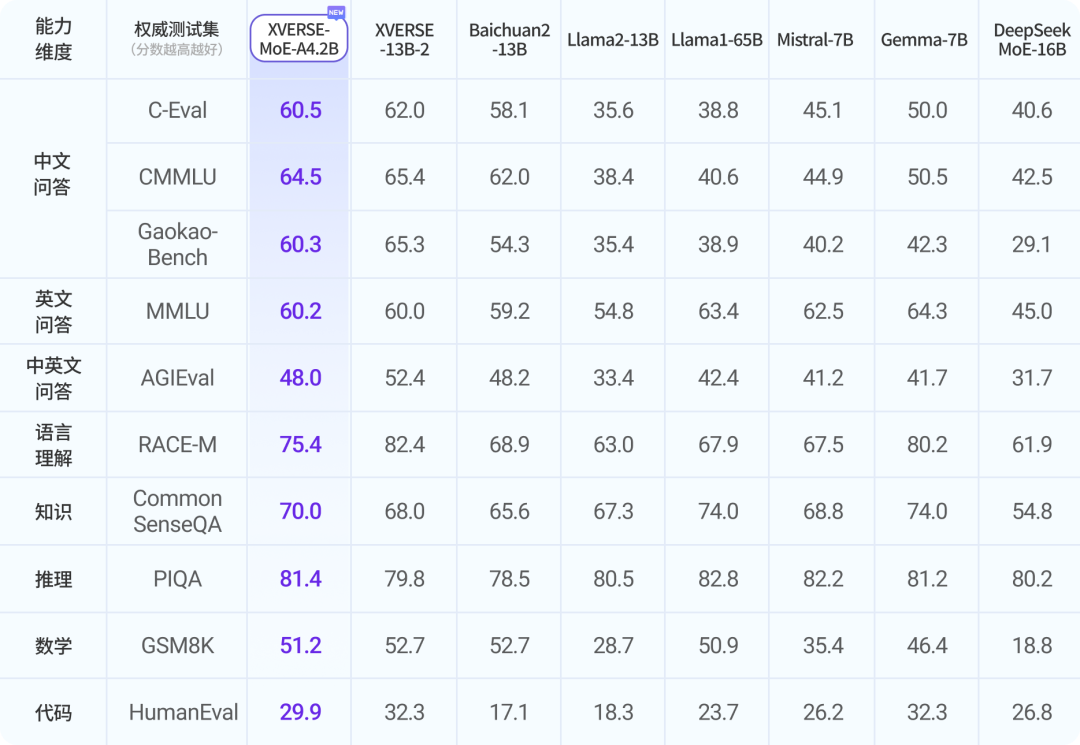
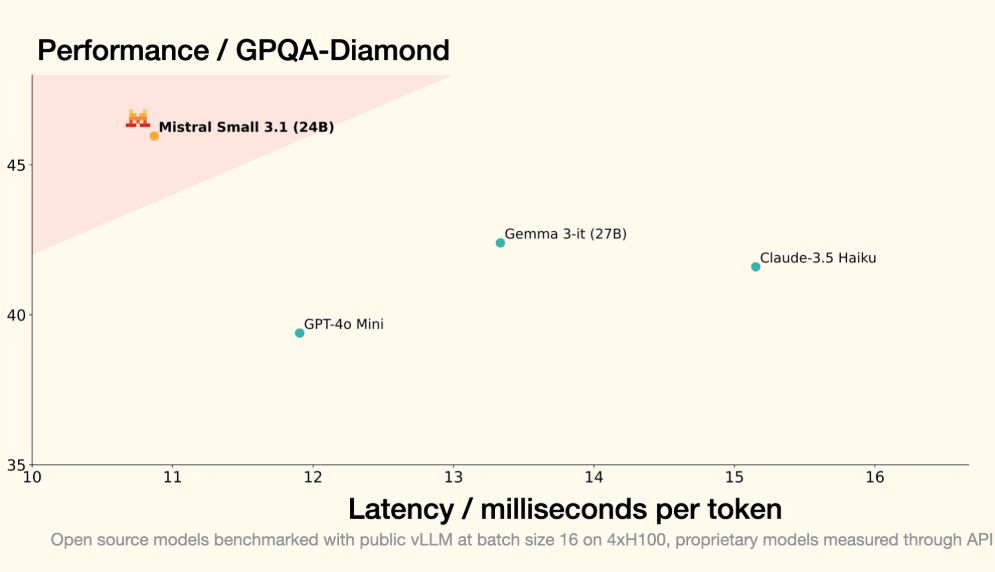
欧洲大模型之光MistralAI开源了2个全新的多模态大模型,即Mistral-Small-3.1-24B基座版本和指令微调版本。这两个大模型均以Apache2.0协议开源,因此可以完全免费商用。而官方也给出了这个模型在多个评测集上的效果,高于GPT-4o-mini和Gemma 3 27B。因为其参数规模较小,推理速度可以达到每秒150个tokens,同时支持多种语言,是一个非常值得关注的小而美的多模态大模型。