
生成式AI平台的玩家都有哪些?
近几年人工智能的发展已经让大家感受到AI算法不再是实验室的小玩具,它对社会和生活的影响已经在逐步显现。仅几年的AI模型如ChatGPT、DALL·E2、StableDiffusion等都是生成式模型,即基于无标注数据训练的可以根据输入观测数据的模型。而生成式AI平台可能是未来最重要的一种平台能力。本文是由Matt Bornstein, Guido Appenzeller, and Martin Casado等人发布的介绍当前生成式AI平台的相关企业。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
近几年人工智能的发展已经让大家感受到AI算法不再是实验室的小玩具,它对社会和生活的影响已经在逐步显现。仅几年的AI模型如ChatGPT、DALL·E2、StableDiffusion等都是生成式模型,即基于无标注数据训练的可以根据输入观测数据的模型。而生成式AI平台可能是未来最重要的一种平台能力。本文是由Matt Bornstein, Guido Appenzeller, and Martin Casado等人发布的介绍当前生成式AI平台的相关企业。

StabilityAI是当前最流行的开源文本生成图像大模型Stable Diffusion背后的公司。这家公司在文本生成图片和文本生成视频方面开源了诸多的大模型。其中,Stable Diffusion是目前使用人数最多的开源文本生成图像大模型。就在刚才,StabilityAI又发布了一个全新的实时的文本生成图像大模型Stable Diffusion XL Turbo,这个最新的模型在A100上生成一张图片只需要0.207秒!

Llama系列是MetaAI开源的大语言模型,是全球开源大模型中最重要的力量之一。第一代的Llama系列模型不允许商用,第二代模型则放松了范围,允许商用。而Llama系列模型因为优秀的品质,也是许多开源模型的基座。而今天Llama3即将发布。

虽然LLM在很多任务上很好用,但是实际应用中我们常见的文本分类、文本标注等工作目前却依然缺少一个可以利用LLM能力的好方法。LLM的强大并没有在工程落地上比肩传统的机器学习处理框架。上周,一个叫Scikit-LLM新的开源项目发布,将传统优秀的Scikit-learn框架与LLM结合,带来了LLM落地的新方法。
在大模型的应用中,处理复杂请求往往伴随着较高的延迟和成本,尤其是当请求内容存在大量重复部分时。这种“慢请求”的问题,特别是在长提示和高频交互的场景中,显得尤为突出。为了应对这一挑战,OpenAI 最近推出了 **提示缓存(Prompt Caching)** 功能。这项新技术通过缓存模型处理过的相同前缀部分,避免了重复计算,从而大幅减少了请求的响应时间和相关成本。特别是对于包含静态内容的长提示请求,提示缓存能够显著提高效率,降低运行开销。本文将详细介绍这项功能的工作原理、支持的模型,以及如何通过合理的提示结

今天,Google发布Gemini 2.5 Flash Lite。这是一款专为追求极致速度、超低延迟和高性价比场景打造的轻量级模型。它的发布标志着 Google 正在将旗舰模型的先进能力(如百万级上下文、原生多模态、工具调用等)逐步下放到更轻量、更经济的模型层级。根据 DataLearnerAI 的实测,这款模型的生成速度最高可达 400 tokens/秒,即使在输入达到 18K tokens 的情况下,也依然可以维持在 160+ tokens/秒 的性能表现,令人惊喜。

让AI Agent通过编写代码来调用工具,而不是直接工具调用。这种方法利用了MCP(Model Context Protocol,模型上下文协议)标准,能显著降低token消耗,同时保持系统的可扩展性。下面,我结合原文的逻辑,分享我的理解和改写版本,目的是记录这个洞察,并为后续实验提供参考。Anthropic作为领先的AI研究机构,于2024年11月推出了MCP,这是一个开放标准,旨在简化AI Agent与外部工具和数据的连接,避免传统自定义集成的碎片化问题。

今日,Moonshot AI正式发布了最新旗舰模型 Kimi K2-Instruct-0905。这是一款基于混合专家架构(MoE)的前沿大语言模型,总参数规模达到 1万亿,激活参数为 320亿,不仅在编码智能上实现了断层式提升,更凭借 256K超长上下文 成为当前同类产品中的佼佼者。官方称其在公共基准和真实智能体任务上的表现均有显著突破,已对标并超越部分国际顶尖模型。
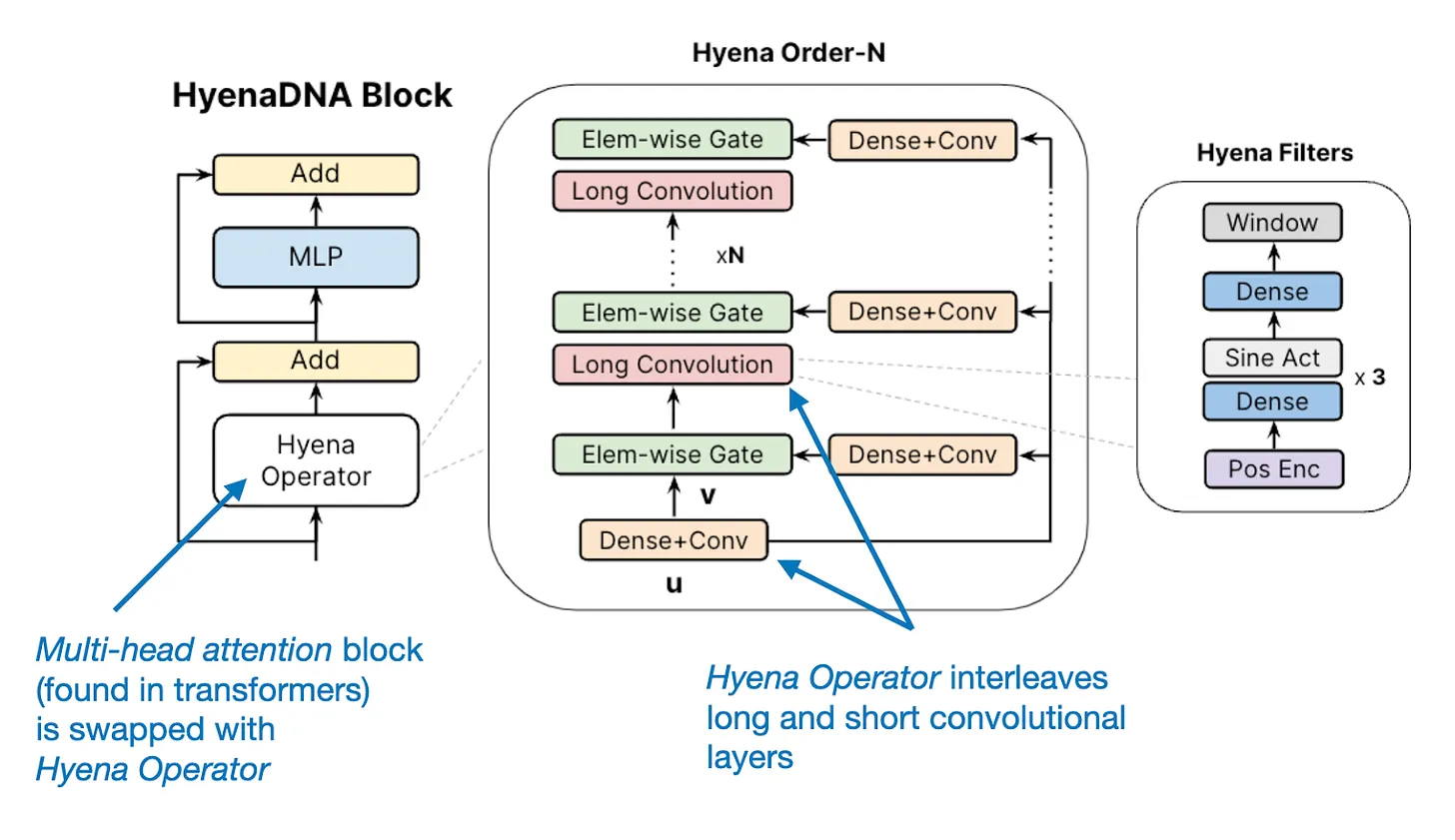
Sebastian Raschka博士是一位深度学习和人工智能研究员、程序员、作者和教育者。他曾是威斯康星大学麦迪逊分校的统计学助理教授,专注于机器学习和深度学习研究。然而,他在2023年辞职,全职投入到他在2022年加入的Lightning AI创业公司,担任首席AI教育者。本文是Sebastian Raschka博士最新的2023年AI进展总结的翻译,大家参考。

就在刚才,Grok官网出现了Grok 4.2 Beta版本,并且已经可以直接使用。即使是免费用户,目前看也可以使用至少8次的提问。

在过去的几年里,我们看到了AI在图像、视频和文本生成方面的巨大进步。然而,音频生成领域的进展却相对滞后。MetaAI这次再为开源贡献重磅产品:AudioCraft,一个支持多个音频生成模型的音频生成开发框架。

在去年末的OpenAI宫斗风波中,伴随着Sam下台和重新掌权过程中有一个非常重要但不被大家了解的算法Q*。国外的路透社曾经提到OpenAI内部一个称为Q*(Q Star)项目取得了非常重大的突破,使得部分人认为AGI很接近,进而引发了一系列事件。但是,Q*到底是什么?是否存在一直被很多人猜测。而最近,一个神秘的帖子继续爆料了Q*的信息。
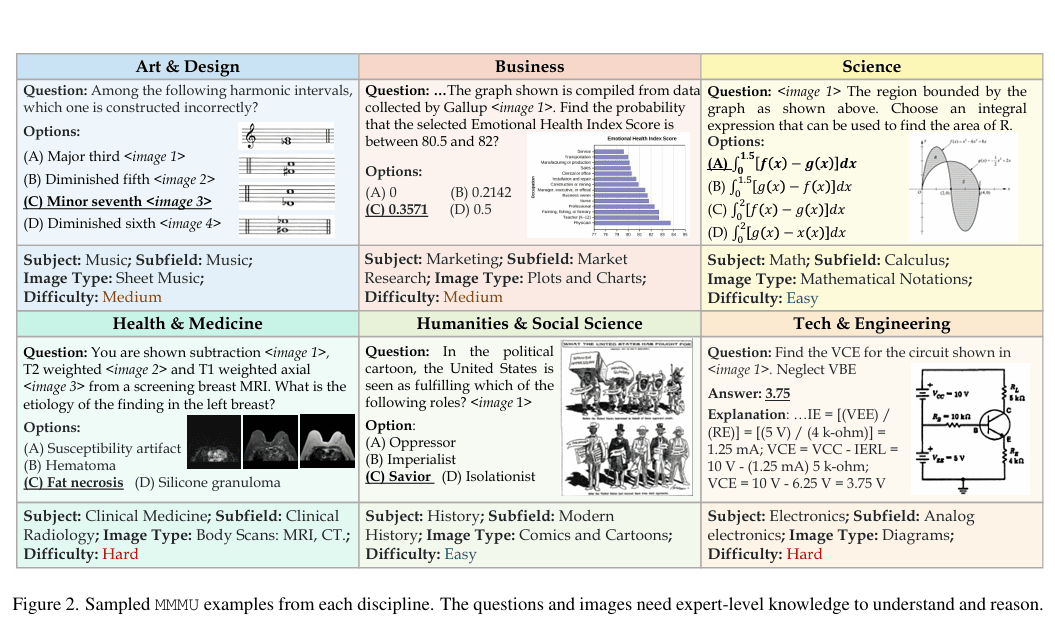
大规模多学科多模态理解与推理基准(MMMU)于2023年11月推出,是一种用于评估多模态模型的复杂工具。该基准测试人工智能系统在需要大学水平学科知识和深思熟虑推理的任务上的能力。与之前的基准不同,MMMU强调跨多个领域的先进感知和推理,旨在衡量朝专家级人工智能通用智能(AGI)的进展。
OpenAI的o1模型被认为是大模型领域中推理能力最强的代表之一,由于其强大的数学逻辑推理能力,被认为是大模型未来的进化方向。而就在2个月之后的11月快结束的时间里,幻方量化旗下人工智能企业DeepSeekAI发布了全新的DeepSeek-R1-Lite-Preview模型,号称是o1模型的有力挑战者。该模型利用了类似的o1的思维链思索过程,推理能力大幅增强。DataLearnerAI将在本文中对该模型进行介绍,并进行几个简单的对比结果测试。结果证明这个模型是非常优秀的!

大模型究竟能否真正提升工程师的编码效率?Anthropic 最近发布的一份重量级内部研究给出了少见的、基于真实工程环境的数据答案。研究覆盖 132 名工程师、53 场深度访谈,以及 20 万条 Claude Code 使用记录,展示了 AI 在软件工程中的实际作用:从生产力显著提升(人均合并 PR 数同比增长 67%)、任务空间扩张(27% 的 Claude 工作原本不会被执行),到工程师技能版图、协作方式与职业路径的深刻变化。与此同时,研究也揭示了技能萎缩、监督负担、工作流变化等新挑战。这是一份罕见的“

智谱AI刚刚开源了新一代视觉-语言模型(Vision-Language Model, VLM)——GLM-4.5V。该模型基于其旗舰文本基础模型GLM-4.5-Air(总参数量1060亿,激活参数量120亿),延续GLM-4.1V-Thinking的技术路线,在42项公开视觉多模态基准测试中,在同规模模型中实现领先性能。GLM-4.5V面向图像、视频、文档理解以及GUI任务等常见多模态场景,采用Mixture-of-Experts(MoE)架构,并保持开源。

Assistant API是OpenAI提供的一个大模型助手类的接口,可以让开发者更加自由、准确地构建类AI Assitant系统。一个AI Assistant可以利用大模型、工具和文件来响应用户的问题。
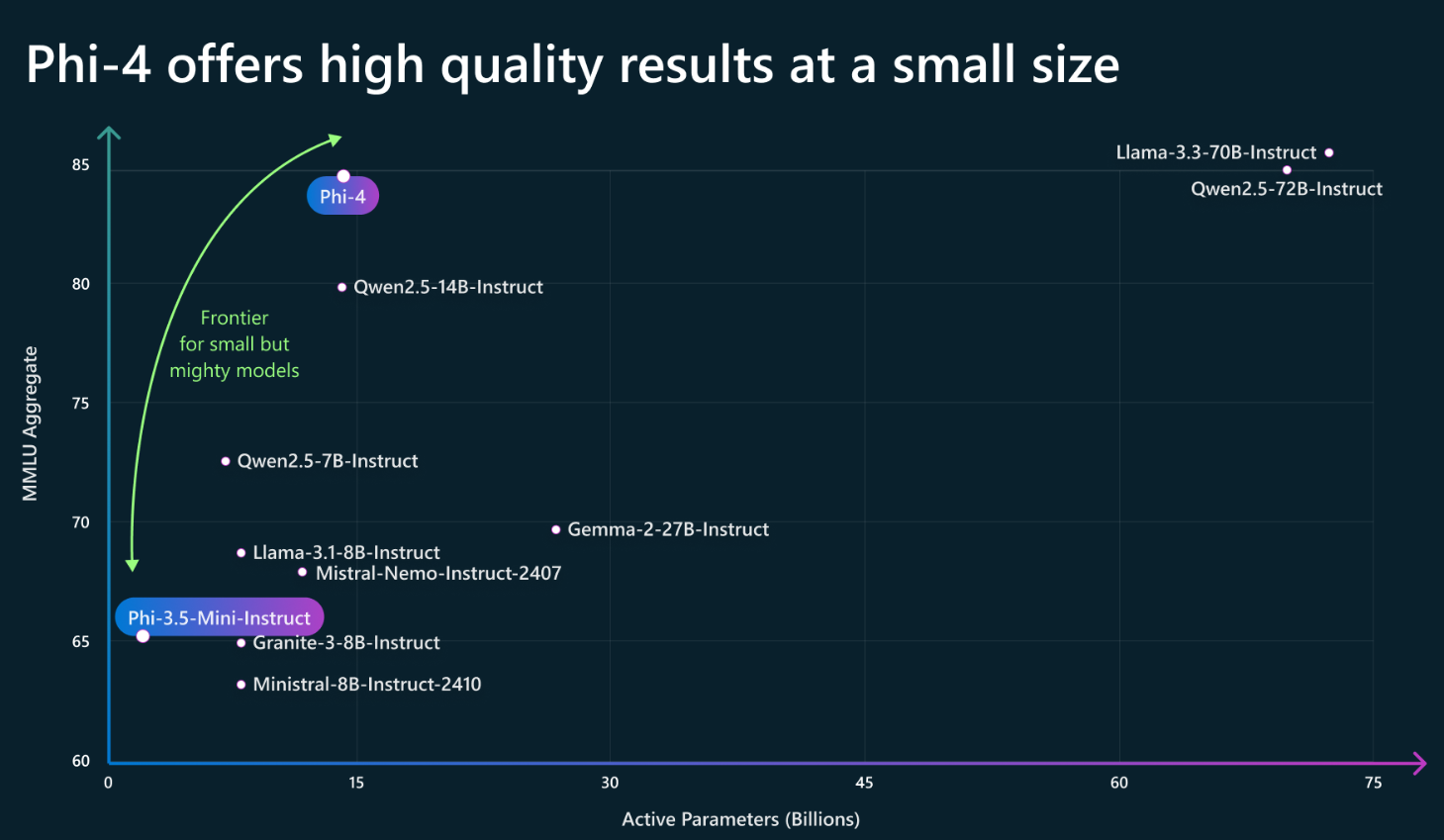
Phi大语言模型是微软发布的一系列小规模大语言模型,其主要的目标是用较小规模参数的大语言模型达成较大参数规模的大语言模型的能力。就在今天,微软发布了Phi4-14B模型,参数规模仅140亿,但是数学推理能力大幅增强,在多个评测基准上甚至接近GPT-4o的能力。

刚刚,X平台疑似泄露出GPT-5的评测结果,共四项评测结果,均排名第一。根据泄露的信息,GPT-5的评测包含2个不同的版本,分别是基础版本的GPT-5以及带推理模式的GPT-5 Reasoning。各项评测结果均大幅超越当前现有其它模型,都是第一!且都是断档领先!
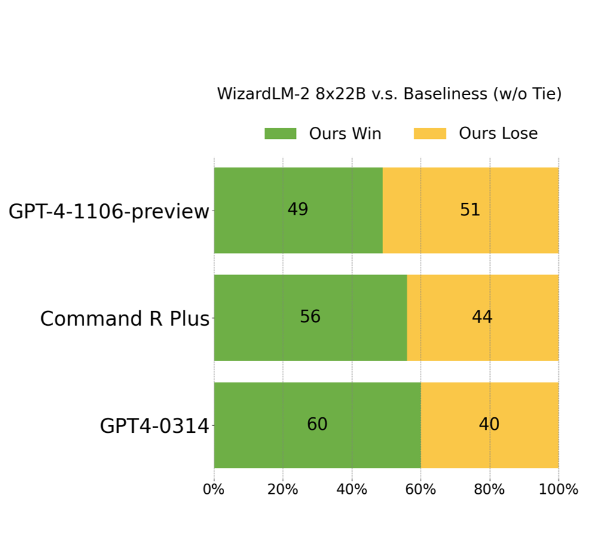
开源大模型是促进大模型技术发展最重要的技术力量之一。此次,微软以Apache 2.0开源协议开源了一个在ChatArena匿名投票评测上打败GPT-4早期版本的模型,即WizardLM-2。这是一系列模型,其中最大的版本是基于Mixtral-8×22B开源模型进行后训练得到的模型。MT-Bench得分8.96,超过了GPT-4-0314。

智谱AI开源了一个60亿参数规模的文生图大模型CogView4-6B,支持生成的图像中加入文字,文字效果自然融入图像中,且该模型支持支持宽高范围512px至2048px内的任意尺寸图像(有限制,正文解释)。

上海人工智能实验室是国内顶尖的人工智能实验室,此前在大模型领域,他们与商汤科技发布的书生·浦语系列在国内引起了很大的关注。此次,他们又开源了一个全新的200亿参数规模的大语言模型InternLM 20B,应该是截止目前中文领域开源的参数规模最大的一个大模型了。

GLM-4.1V-Thinking是智谱AI(Zhipu AI)与清华大学KEG实验室联合推出的多模态推理大模型。这款模型并非简单的版本迭代,而是通过一个以“推理为中心”的全新训练框架,旨在将多模态模型的能力从基础的视觉感知,推向更复杂的逻辑推理和问题解决层面。多模态理解能力接近720亿的Qwen2.5-VL-72B。
Kiro 是一款AWS刚发布的、具有代理(agentic)能力的集成开发环境(IDE),它的目的是希望通过简化的开发者体验,帮助开发者从概念原型无缝过渡到生产级别的应用。它的核心理念是“规格驱动开发”(spec-driven development),以解决当前 AI 编程从有趣的原型到可靠的生产系统之间存在的鸿沟。