
Claude Code如何更加高效使用?Claude Code创始人分享的13条Claude Code实践经验总结
今天,Claude Code 的创建者 Boris 发了一条很长的 thread,第一次比较完整地讲了他自己是怎么使用 Claude Code 的。共13条总结,我们这里总结一下,供大家参考。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
今天,Claude Code 的创建者 Boris 发了一条很长的 thread,第一次比较完整地讲了他自己是怎么使用 Claude Code 的。共13条总结,我们这里总结一下,供大家参考。

AI Agent 的一个关键趋势正在浮现:从“快速回答问题”转向“长时间稳定执行复杂任务”。本文系统梳理了为什么 Anthropic、OpenAI 等企业开始强调“长时运行 Agent”,并解释其真实含义并非模型一直思考,而是通过作业化、异步执行、可恢复运行和动态上下文管理,实现跨会话完成复杂目标。文章深入对比了长时 Agent 与传统脚本化 LLM Loop 的本质差异,分析其在自治能力、上下文工程、耐久执行与治理上的核心价值,并总结构建长时运行 AI Agent 所需的关键技术等。
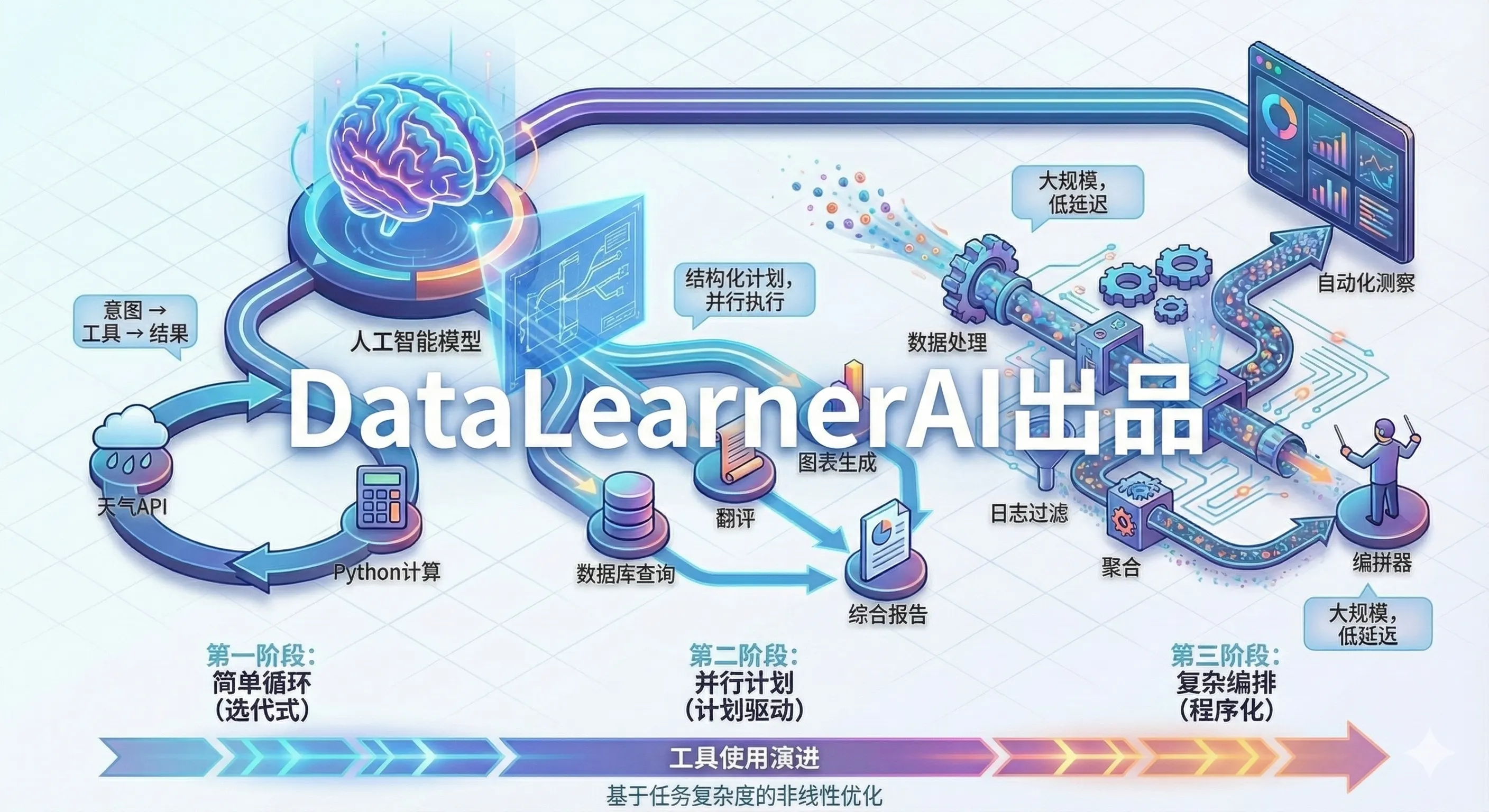
本文系统梳理了大模型工具使用(Tool Use)的三个演进阶段:循环式工具选择(Function Calling)、计划驱动执行(Plan-then-Execute)和程序化工具编排(Programmatic Tool Calling)。从 OpenAI Function Calling 的单次调用模式,到支持并行调度的计划-执行范式,再到最新的代码驱动编排方式,工具使用正在从"逐步决策"走向"计划驱动、代码驱动"。

就在刚刚,阿里巴巴正式免费开源了两款全新的多模态模型——Qwen3-VL-Embedding(多模态向量模型)和 Qwen3-VL-Reranker(多模态重排序模型),首次在开源体系中系统性补齐了多模态 RAG 在“向量化检索 + 精排重排”两个关键环节上的能力空白。这两个模型是基于强大的Qwen3-VL基础模型构建的专用多模态向量与重排(Reranking)模型。

MMEB(Massive Multimodal Embedding Benchmark)是一个用于评估多模态嵌入模型的基准测试框架。该基准最初聚焦于图像-文本嵌入,并在后续版本中扩展到文本、图像、视频和视觉文档输入。MMEB通过收集多样化数据集,提供一个统一的评估平台,用于测试模型在分类、检索和其他任务上的性能。

Anthropic 于 2026 年 1 月 12 日发布了 Cowork,这是一款基于 Claude 模型的新型 AI Agent工具,作为 Claude 桌面应用的 macOS 版本研究预览版推出。目前仅限 Claude Max 订阅者使用,未来计划扩展到 Windows 和跨设备同步。Cowork 继承了 Claude Code 的核心代理能力,但更注重非开发者用户的日常生产力任务,例如访问用户指定的文件夹,读取、编辑或创建文件,帮助整理杂乱下载、从截图生成电子表格,或从笔记起草报告。

就在大家还在争论 AI 编程上限的时候,Cursor 团队发布了一份非常值得大家关注的内部测试报告,展示了当我们将 Agent 的规模和运行时间推向极致时,会发生什么。这不仅仅是简单的代码生成,而是让 AI 像人类团队一样协作,构建百万行级别的项目。这项实验为我们揭示了 AI 在编码领域的潜力与局限,值得每位开发者关注。

ClawdBot 是一款开源AI代理工具,旨在帮助用户在本地设备上处理各种任务,在科技社区中迅速获得关注。它于2025年底由开发者Peter Steinberger(@steipete)推出,基于Anthropic的Claude模型,名称结合了“Claw”(龙虾钳子)和“Claude”,并以龙虾作为吉祥物,象征其适应性和本地运行特性。该工具强调本地优先的设计,用户可以完全控制数据和过程,避免对云服务的依赖。

最近这几天,如果你的 X (Twitter) 首页被 Clawdbot 刷屏了,不用惊讶,主要是太火了。但是这个软件的使用有一定门槛,而且争议比较大。X上有一位博主分享了他对这个东西的看法和使用经验,挺详细的,对于想了解Clawdbot是啥的,这个文章不错。大家看也可以从这个文章看到Clawdbot能做什么,和Cowork对比有啥优点和缺点

本文整理了 Andrej Karpathy 在 2025 年底关于 AI Agent 编程的核心观点。基于其使用 Claude Code 等大模型的真实工程经验,Karpathy 认为软件工程正从“手动编码”转向“由 AI Agent 执行、人类定义目标与约束”的新范式。文章同时分析了 AI Agent 在效率提升之外带来的工程风险、技能退化与内容质量问题,并指出 2026 年将是行业系统性消化 AI Agent 能力的关键一年。

2026年1月27日,月之暗面(Moonshot AI)发布新一代模型Kimi K2.5。根据官方说明,这是Kimi K2的后续版本,目前已通过Kimi.com网页端和App向用户推送。该模型同步上线Kimi API开放平台及编程助手Kimi Code,模型权重与相关代码也在Hugging Face开源。

Andrej Karpathy预测2026年AI将主导软件编码工作流,带来巨大效率提升,但可能引发低质代码泛滥(slopacolypse)。Anthropic的Boris Cherny以Claude Code团队实践回应,展示近100% AI生成代码、通用工程师招聘策略,以及通过模型迭代有效控制质量问题。
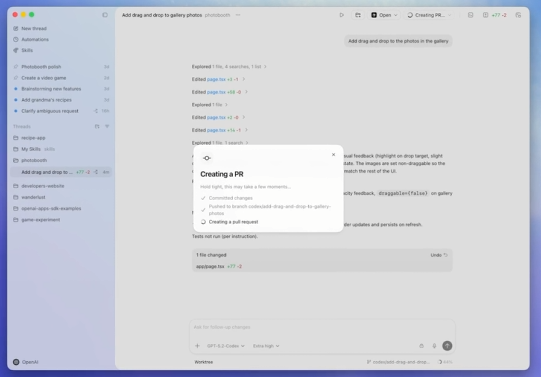
OpenAI 刚刚(2026年2月2日)正式推出了 Codex App (macOS 版)。这款产品被定位为“智能体指挥中心”(A Command Center for Agents),标志着 Codex 从单纯的代码生成工具演进为能够独立执行复杂、长周期任务的开发协作平台。
OpenAI在2025年9月推出的GDPval基准,将焦点转向“具有经济价值的真实任务”,而第三方独立机构Artificial Analysis在此基础上开发的GDPval-AA,进一步引入了agentic(代理)能力评估和ELO排行榜,成为当前最受关注的“实用性”评测基准之一。
OSWorld(Open Source World)是首个真正基于真实操作系统环境的多模态Agent评测平台。它不同于传统的模拟环境(如MiniWoB或WebArena),而是直接在完整的Ubuntu、Windows和macOS系统中运行,让AI代理通过截图观察、鼠标键盘操作来完成任务。
AIME 2026 是基于美国数学邀请赛(American Invitational Mathematics Examination)2026 年问题的评测基准,用于评估大语言模型在高中水平数学推理方面的表现。该基准包含 15 个问题,覆盖代数、几何、数论和组合数学等领域。模型通过生成答案并与标准答案比较来计算准确率。
PinchBench 是 Kilo Code 团队开发的开源基准测试系统,用于评估大型语言模型作为 OpenClaw 编码代理核心的表现。该系统运行一组固定真实世界任务,计算代理的任务完成成功率,同时记录执行速度和成本。所有结果通过公开排行榜 https://pinchbench.com 显示,目前包含 50 个模型的 403 次运行记录,最新更新时间为 2026 年 3 月 18 日。基准测试的代码和任务定义全部开源在 GitHub(pinchbench/skill 仓库),任何开发者均可本地复现或添加
SWE-bench Multilingual 是 SWE-bench 基准系列的扩展版本。该基准用于评估大语言模型在软件工程任务上的表现,覆盖多种编程语言。数据集包含 300 个从真实 GitHub 问题与对应拉取请求中提取的任务,涉及 42 个仓库和 9 种编程语言。模型接收问题描述与仓库快照后,需生成代码补丁,并通过失败到通过(F2P)和通过到通过(P2P)测试套件进行验证。
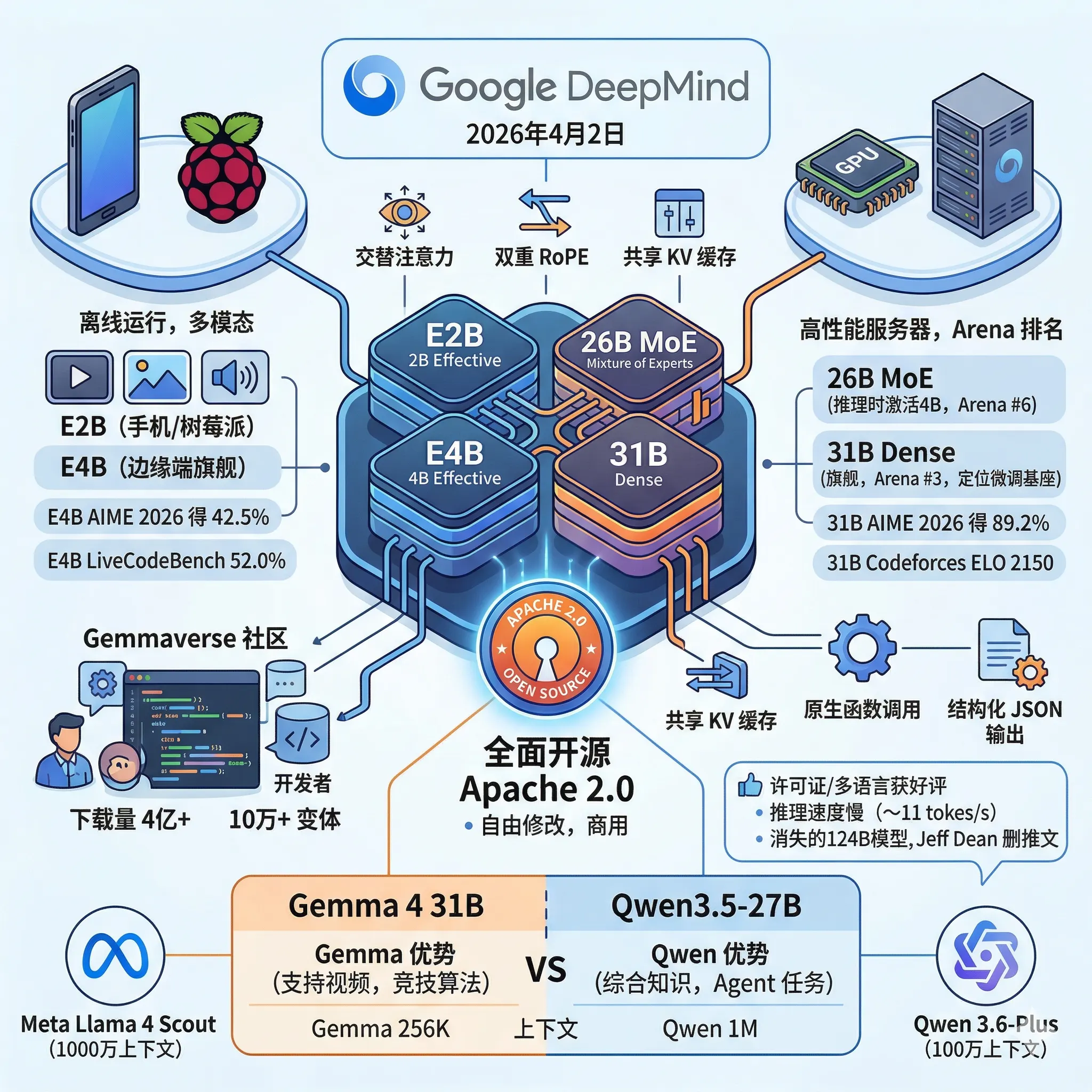
2026年4月2日,Google DeepMind 发布了 Gemma 4 系列,共四个版本:E2B、E4B、26B A4B 和 31B Dense。这也是 Gemma 系列首次采用 Apache 2.0 授权,允许完全商用和二次分发。
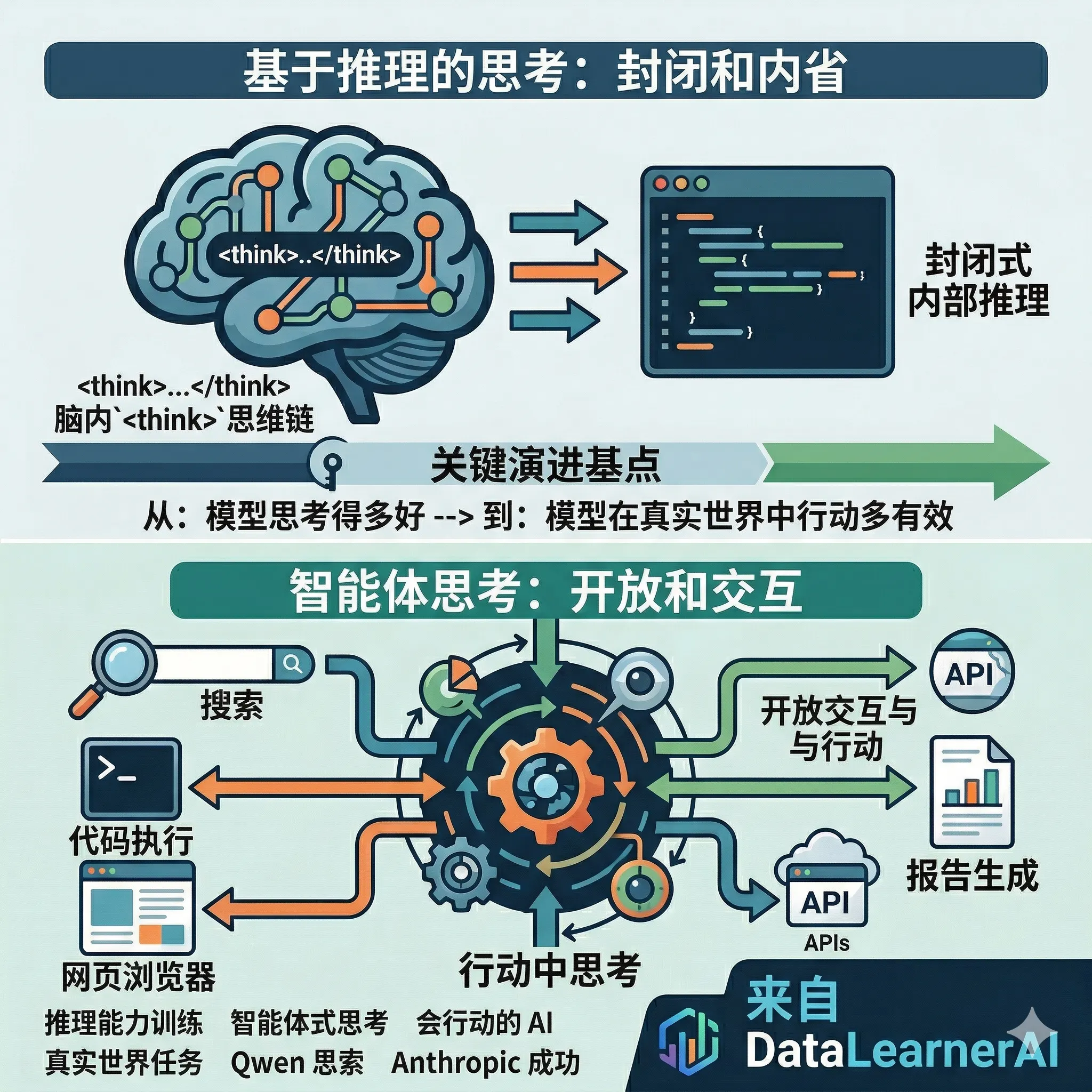
unyang 是前 Qwen(通义千问)负责人,前段时间他的离职造成了许多人的关注。不过他并未沉寂,就在刚才,Junyang 发表了一篇关于如何训练大模型推理能力、以及未来大模型推理能力训练应该走向何方的深度讨论。
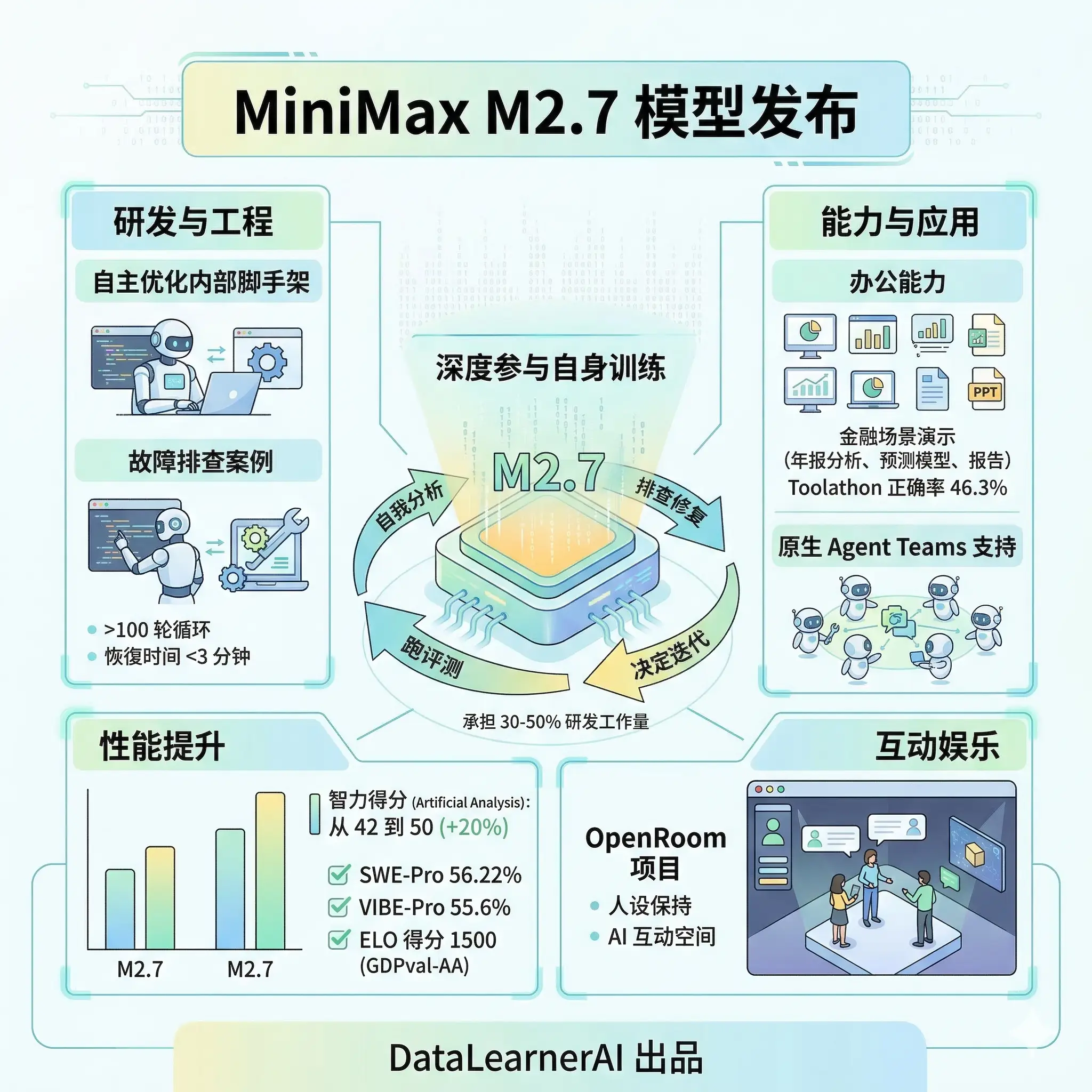
MiniMaxAI 刚刚发布了全新的 M2.7 模型,官方说本次发布的 M2.7 最大的特点是第一个深度参与迭代自身训练流程的模型,也就是说模型在训练过程中进行了自我分析并参与迭代。目前 M2.7 已经可以在官网使用,接口价格不变。不过该模型当前并未宣布开源,还不确定未来情况。
2026年4月2日,Google DeepMind 正式发布了 Gemma 4 系列模型。自2024年首代 Gemma 发布以来,开发者已经累计下载超过4亿次,并在此基础上衍生出超过10万个变体版本,形成了所谓的"Gemmaverse"社区生态。这次的 Gemma 4,Google 不只是做了常规的性能升级,而是在许可证、模型架构和部署覆盖范围上同时迈出了一大步。

几个小时前,Anthropic发生一起信息泄露事件,还没来得及官宣,自家最强新模型就被”意外”公之于众。新模型的能力据称远超Opus 4.6!
就在刚才,很多人发现DeepSeek官网已经更新了模型,虽然不确定是DeepSeek-V4,但是目前可以肯定,这不是之前公布的DeepSeek-V3.2而是一个全新的模型。为此,DataLearnerAI实测正式,这个模型的确并非此前的版本。