
AIME 2026:基于2026年美国数学邀请赛的大模型数学能力评估基准
AIME 2026 是基于美国数学邀请赛(American Invitational Mathematics Examination)2026 年问题的评测基准,用于评估大语言模型在高中水平数学推理方面的表现。该基准包含 15 个问题,覆盖代数、几何、数论和组合数学等领域。模型通过生成答案并与标准答案比较来计算准确率。
A curated list of original AI and LLM articles related to "大模型数学能力", updated regularly.
AIME 2026 是基于美国数学邀请赛(American Invitational Mathematics Examination)2026 年问题的评测基准,用于评估大语言模型在高中水平数学推理方面的表现。该基准包含 15 个问题,覆盖代数、几何、数论和组合数学等领域。模型通过生成答案并与标准答案比较来计算准确率。
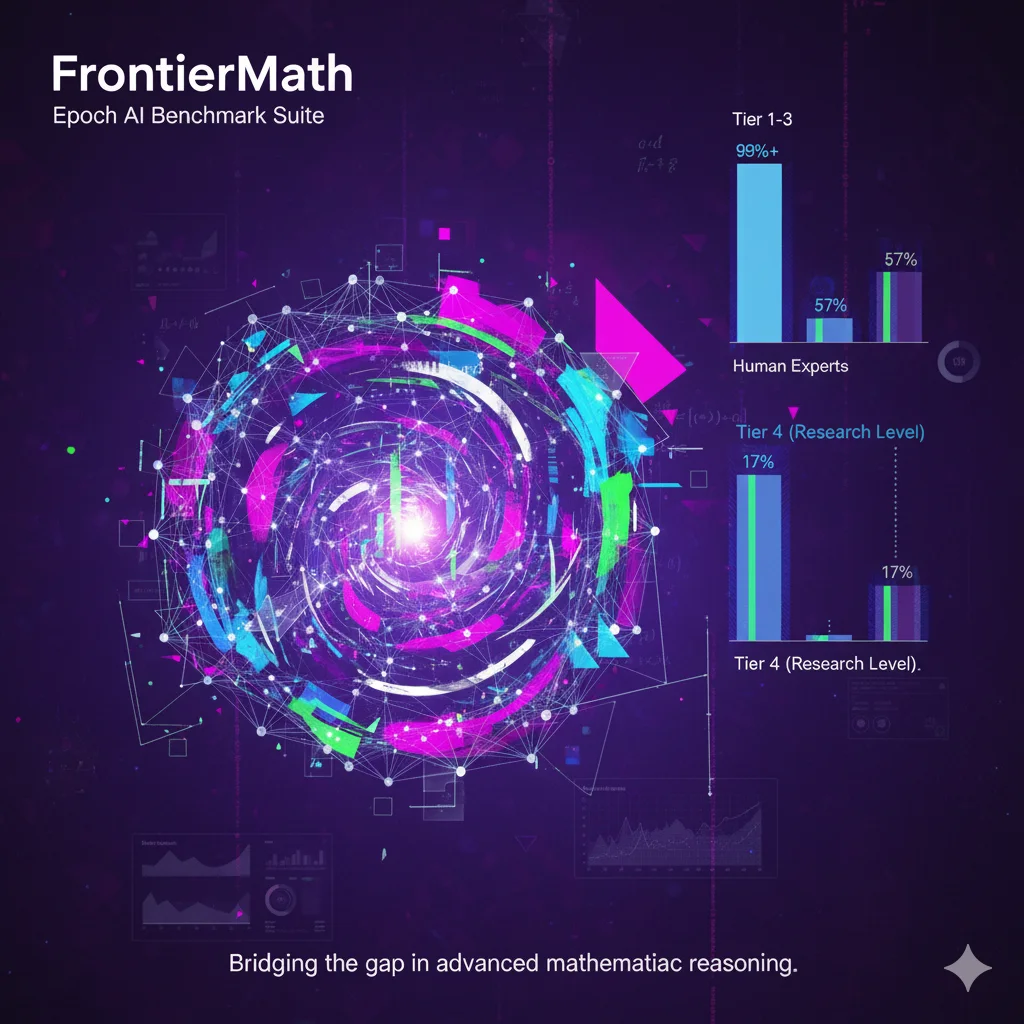
FrontierMath是一个由Epoch AI开发的基准测试套件,包含数百个原创的数学问题。这些问题由专家数学家设计和审核,覆盖现代数学的主要分支,如数论、实分析、代数几何和范畴论。每个问题通常需要相关领域研究人员投入数小时至数天的努力来解决。基准采用未发表的问题和自动化验证机制,以减少数据污染风险并确保评估可靠性。当前最先进的AI模型在该基准上的解决率低于2%,这反映出AI在处理专家级数学推理时的局限性。该基准旨在为AI系统向研究级数学能力进步提供量化指标。
在衡量大语言模型(LLM)智能水平的众多方法中,除了常见的常识推理、专业领域测评外,还有一个正在兴起且极具挑战性的方向——算法问题求解。在这一领域,几乎没有哪项比赛能比 国际信息学奥林匹克(International Olympiad in Informatics,简称 IOI) 更具权威性与含金量。