Dask的本地集群配置和编程
Dask提供了多种分布式调度器,当缺少多台服务器时候,也可以通过本地集群来实现单机分布式的计算。这篇博客主要就是介绍如何实现Dask的单机分布式调度器。第一小节是简介,第二节是单机调度器的简写版本,第三节是单机调度器的完整版本,第四节是使用的一些示例。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Dask提供了多种分布式调度器,当缺少多台服务器时候,也可以通过本地集群来实现单机分布式的计算。这篇博客主要就是介绍如何实现Dask的单机分布式调度器。第一小节是简介,第二节是单机调度器的简写版本,第三节是单机调度器的完整版本,第四节是使用的一些示例。

Pandas中的DataFrame选择某些行和某些列是有很多中操作和选择的,不太容易记,这里整理一下。
Git操作记录
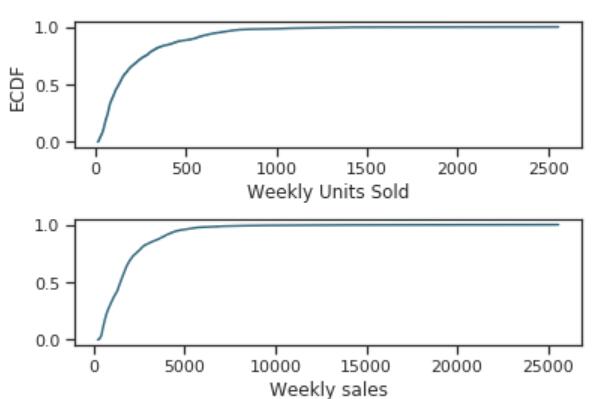
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。

Scikit-Learn有很优秀的机器学习处理思想,包括TensorFlow等新框架都借鉴了它的设计思想。最近的更新也让Scikit-Learn更加强大。在描述这个更新之前我们先简单看一下历史,然后让我们一起看看都有什么新内容吧。
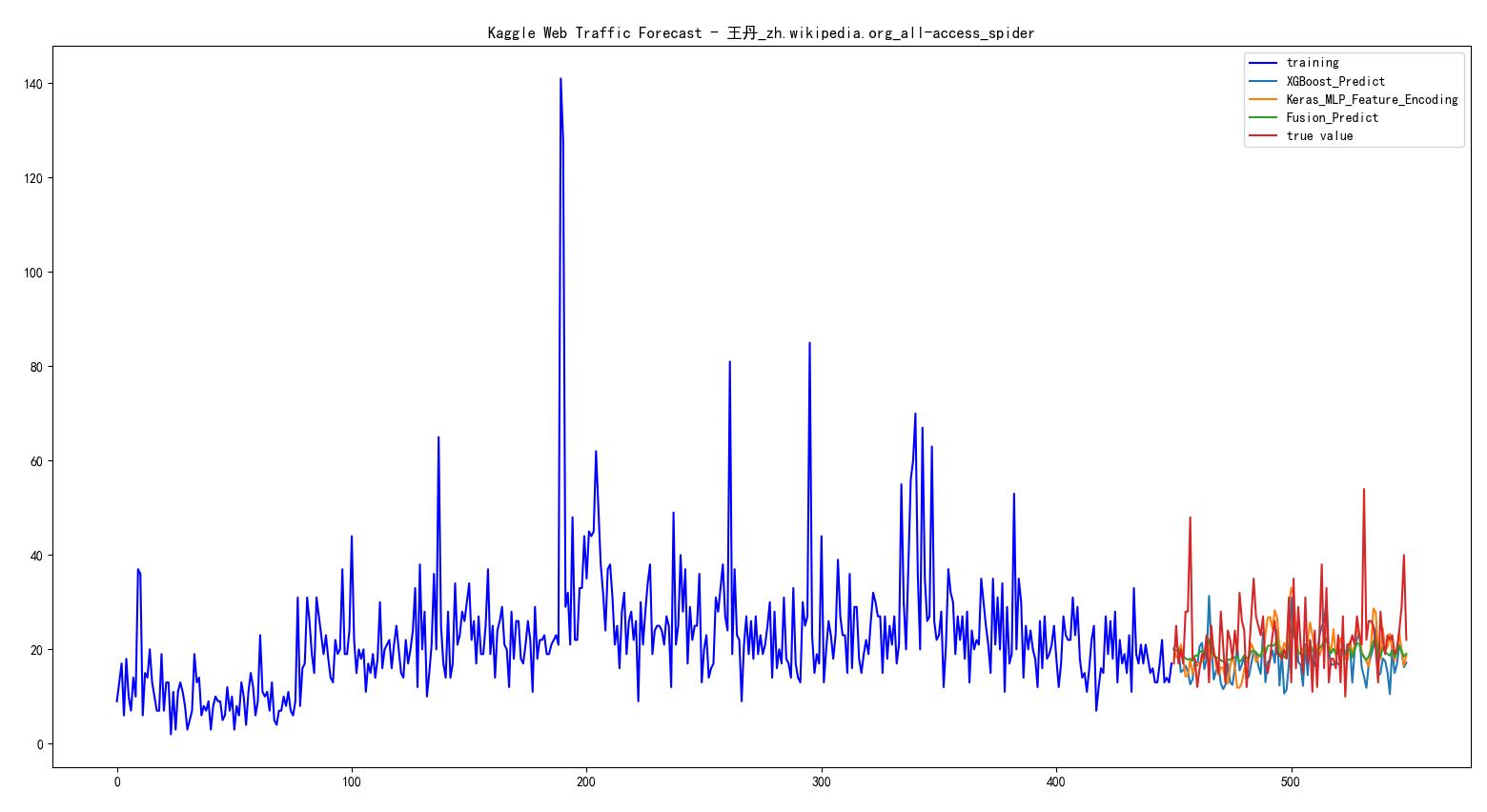
TensorFlow中常见的错误解释及解决方法

在Java中,自增是一种非常常见的操作,在自增中,有两种写法,一种是前缀自增(++i),一种是后缀自增(i++)。这里主要简单介绍两种自增的差别。
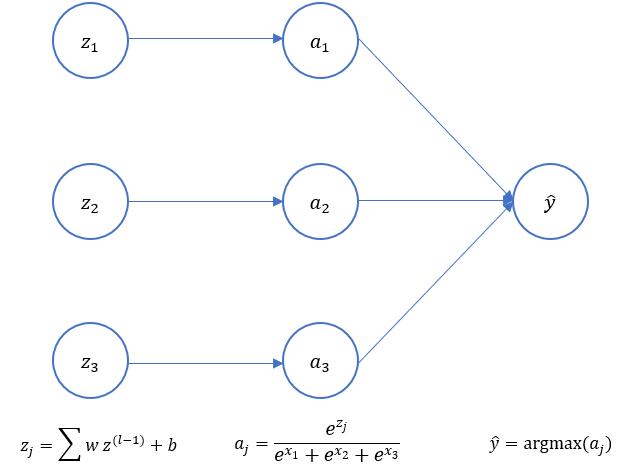
softmax作为多标签分类中最常用的激活函数,常常作为最后一层存在,并经常和交叉熵损失函数一起搭配使用。这里描述如何推导交叉熵损失函数的推导问题。
Batch Normalization是深度学习中最重要的技巧之一。是由Sergey Ioffe和Christian Szeged创建的。Batch Normalization使超参数的搜索更加快速便捷,也使得神经网络鲁棒性更好。本篇博客将简要介绍相关概念和原理。
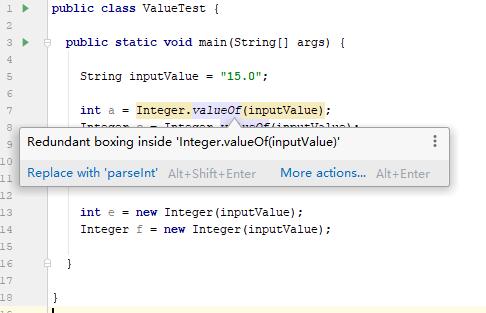
在Java的类型转换中,我们经常会使用valueOf或者parseInt(parseFloat/parseDouble等)来转换。这二者有什么区别呢?这里简要介绍一下。
在自然语言数据预处理阶段,为了提取更有用的信息,对数据必须进行相应处理。本文重点介绍对于高频词与低频词的处理。
时间序列数据分析的基础包含大量的统计知识。这篇博客主要用通俗的语言描述时间序列数据中涉及到的一些基本统计知识。
随着深度学习的火热,对计算机算力的要求越来越高。从2012年AlexNet以来,人们越来越多开始使用GPU加速深度学习的计算。 然而,一些传统的机器学习方法对GPU的利用却很少,这浪费了很多的资源和探索的可能。在这里,我们介绍一个非常优秀的项目——RAPIDS,这是一个致力于将GPU加速带给传统算法的项目,并且提供了与Pandas和scikit-learn一致的用法和体验,非常值得大家尝试。

在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,可以提高模型效果。
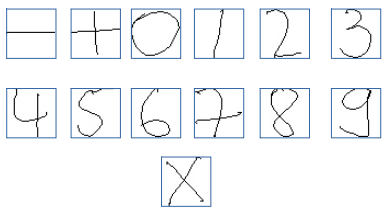
本文是发在Medium上的一篇博客:《Handwritten Equation Solver using Convolutional Neural Network》。本文是原文的翻译。这篇文章主要教大家如何使用keras训练手写字符的识别,并保存训练好的模型到本地,以及未来如何调用保存到模型来预测。

Tensorflow中tf.data.Dataset是最常用的数据集类,我们也使用这个类做转换数据、迭代数据等操作。本篇博客将简要描述这个类的使用方法。
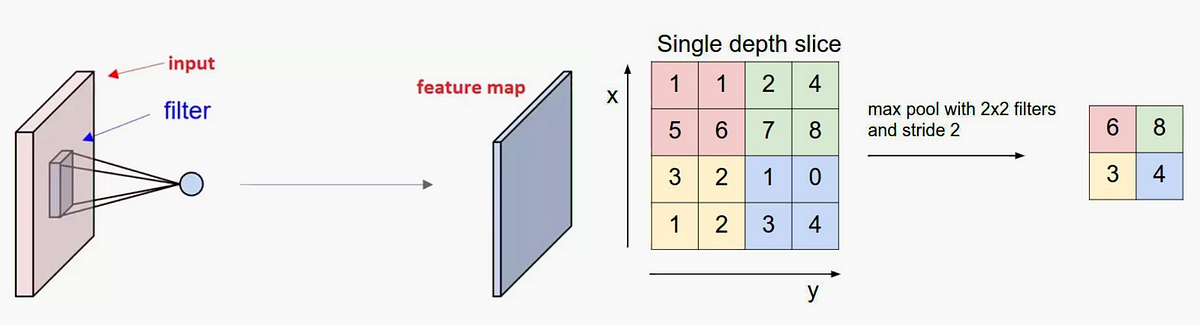
卷积神经网络是图像识别领域最重要的深度学习技术。也可以说是是本轮深度学习浪潮开始点。本文总结了CNN的三种高级技巧,分别是空洞卷积、显著图和反卷积技术。
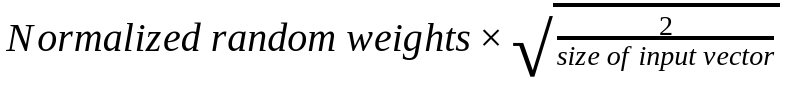
深度学习的初始化非常重要,这篇博客主要描述两种初始化方法:一个是Kaiming初始化,一个是LSUV方法。文中对比了不同初始化的效果,并将每一种初始化得到的激活函数的输出都展示出来以查看每种初始化对层的输出的影响。当然,作者最后也发现如果使用了BatchNorm的话,不同的初始化方法结果差不多。说明使用BN可以使得初始化不那么敏感了。
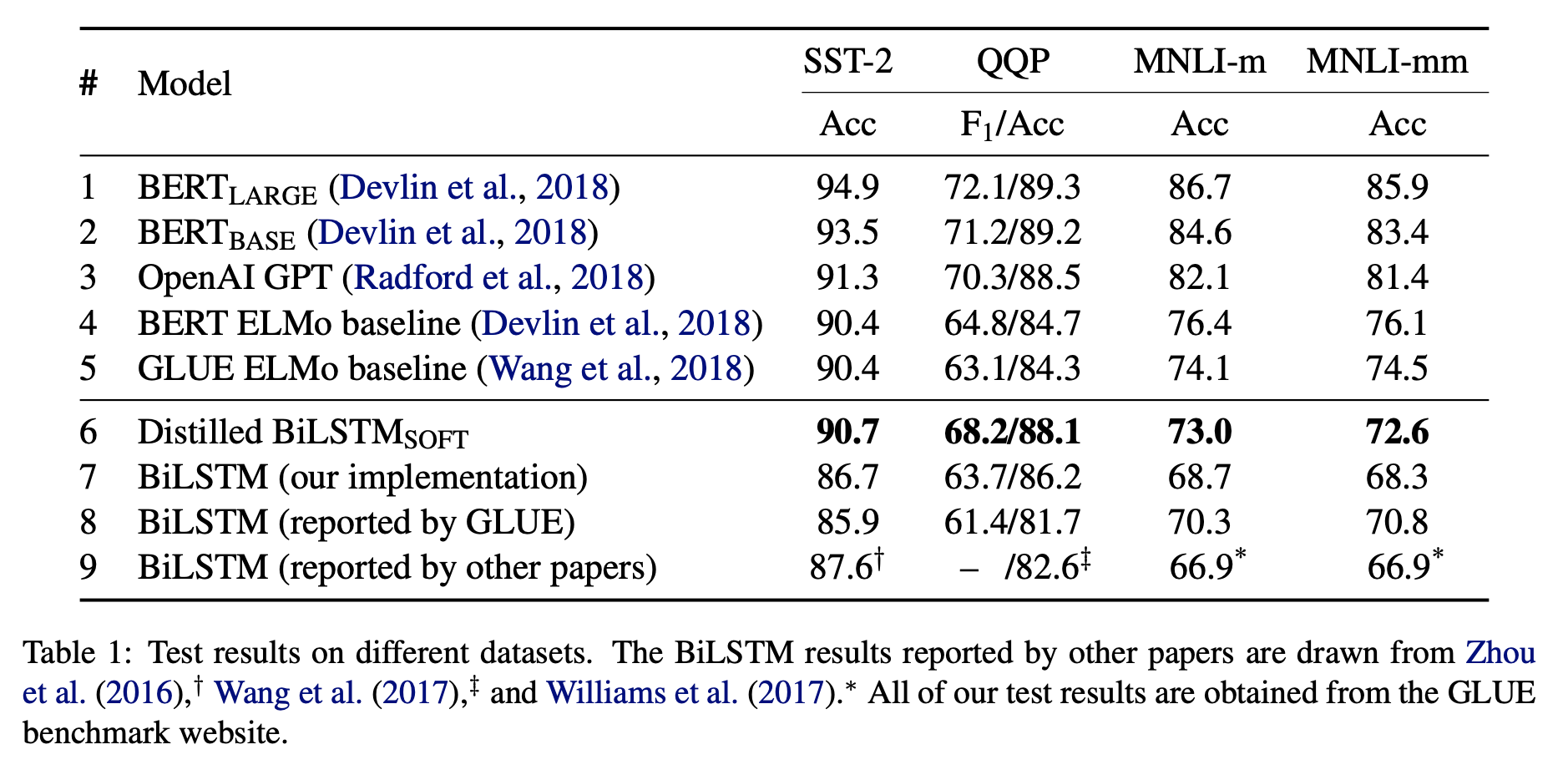
BERT是很好的模型,但是它的参数太大,网络结构太复杂。在很多没有GPU的环境下都无法部署。本文讲的是如何利用BERT构造更好的小的逻辑回归模型来代替原始BERT模型,可以放入生产环境中,以节约资源。
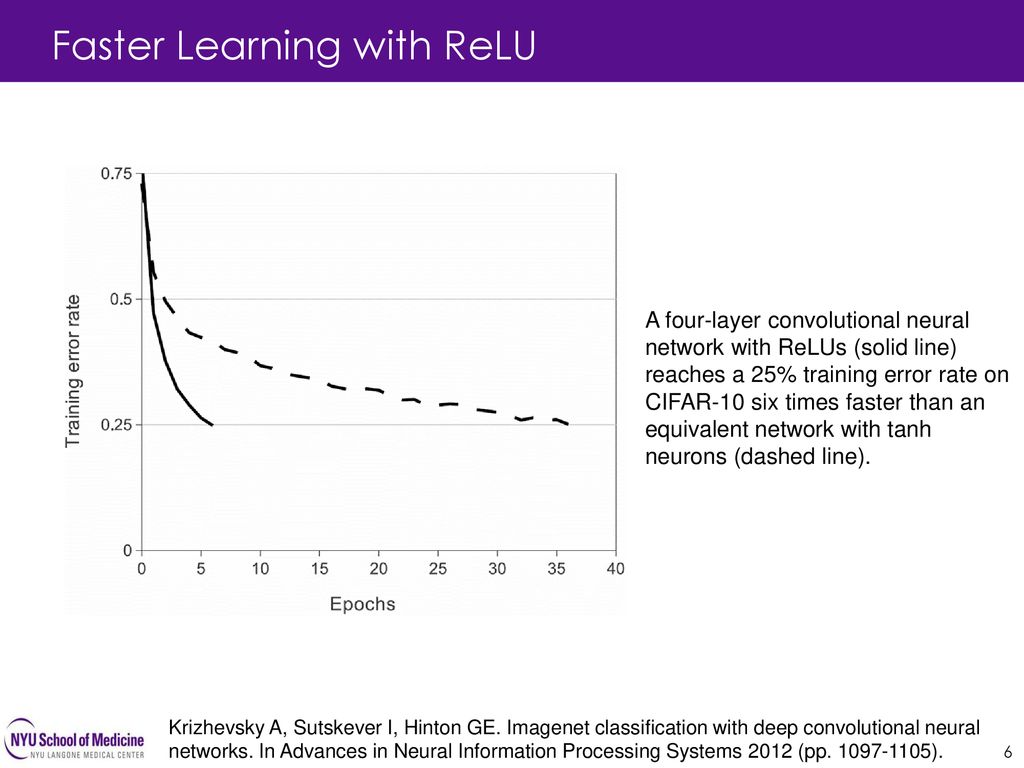
2012年发表的AlexNet可以算是开启本轮深度学习浪潮的开山之作了。由于AlexNet在ImageNet LSVRC-2012(Large Scale Visual Recognition Competition)赢得第一名,并且错误率只有15.3%(第二名是26.2%),引起了巨大的反响。相比较之前的深度学习网络结构,AlexNet主要的变化在于激活函数采用了Relu、使用Dropout代替正则降低过拟合等。本篇博客将根据其论文,详细讲述AlexNet的网络结构及其特点。
AdaBoost,全称是“Adaptive Boosting”,由Freund和Schapire在1995年首次提出,并在1996发布了一篇新的论文证明其在实际数据集中的效果。这篇博客主要解释AdaBoost的算法详情以及实现。它可以理解为是首个“boosting”方式的集成算法。是一个关注二分类的集成算法。