HuggingFace开源语音识别模型Distil-Whisper,基于OpenAI的Whisper-V2模型蒸馏,速度快6倍,参数小49%!
语音识别在实际应用中有非常多的应用。早先,OpenAI发布的Whisper模型是目前语音识别模型中最受关注的一类,也很可能是目前ChatGPT客户端语音识别背后的模型。HuggingFace基于Whisper训练并开源了一个全新的Distil-Whisper,它比Whisper-v2速度快6倍,参数小49%,而实际效果几乎没有区别。
Distil-Whisper的实际测试识别速度大概是每秒的音频需要0.0251秒完成解析,而Whisper-V2需要0.1372秒。这意味着,Distil-Whisper每秒可以处理39.84秒音频左右!
OpenAI的Whisper模型简介
OpenAI的Whisper是一个通用目的的语音识别模型,基于多种语料训练的可以识别多种语言的模型。按照官方的宣传,Whisper在英语语音识别方面的鲁棒性和准确性接近人类水平:
According to OpenAI, Whisper approaches “human-level robustness and accuracy” for English speech recognition.
Whisper模型引起这么多的关注主要包括如下原因:
- 在不同背景噪音、口音等方面Whisper都有较好的鲁棒性;
- 一个模型可以识别多种语言;
- 基于68万小时的多语言数据集训练;
此外,Whisper是OpenAI最近几年较少的开源模型,2022年9月首次发布,包含不同的版本。在2022年12月发布了V2版本。其中最大的模型约15.5亿参数。这些具体的Whisper模型版本参考:
Whisper模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/Whisper Whisper V2模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/Whisper-V2
不过,Whisper模型的速度一般,根据测试,原始的Whisper-V2模型在NVIDIA V100S上,对13分钟的语音识别的转换时间要4分钟30秒。
此次,HuggingFace发布的Distil-Whisper模型速度上比原始的Whisper-V2快6倍!
HuggingFace发布的Distil-Whisper模型
Distil-Whisper模型是才发布的,HuggingFace官方说会在2023年11月2日开源。
Distil-Whisper是一个通过伪标签(Pseudo-Label)技术和知识蒸馏(Knowledge Distillation)方法从原始的 Whisper 模型中蒸馏得到的语音识别模型。目的是在不损失太多性能的情况下,创建一个更小、更快的模型,能够在低延迟或资源受限的环境中运行。
为此,HuggingFace首先使用 Whisper 模型为大量未标记数据生成伪标签,然后利用这些伪标签数据和知识蒸馏技术来训练 Distil-Whisper。
具体来说,Distil-Whisper模型包含如下几个特点:
-
高效且轻量:Distil-Whisper 是原始 Whisper 模型的轻量级版本,具有 51% 更少的参数,但在性能上与原始模型相当。
-
大规模伪标签训练:通过利用大量未标记数据的伪标签,模型实现了大规模的训练,从而提高了其鲁棒性和性能。
-
保持鲁棒性:尽管模型经过蒸馏和减小,但它仍然保持了对复杂声学条件的鲁棒性,这在原始 Whisper 模型中是一个重要的特点。
-
快速推理:Distil-Whisper 比原始模型快 5.8 倍,使其非常适合需要快速响应的应用。
-
质量控制:采用了基于词错误率的启发式方法,确保只使用最高质量的伪标签进行训练,从而保证了模型的高质量输出。
以上就是 Distil-Whisper 模型的主要特点。这些特点使其在语音识别领域中具有很高的竞争力,尤其是在需要轻量级、高性能模型的场景中。
Distil-Whisper的训练细节
Distil-Whisper模型的方案和训练细节主要包含2个方面,一个是利用新的数据集,基于Whisper模型生成伪标签,用于后续训练;第二个是提出了基于Whisper的知识蒸馏模型方案,用以训练Distil-Whisper模型。
Distill-Whisper模型使用的训练数据
为了训练Distill-Whisper模型,HuggingFace收集了9个公开语音数据集,包含18260个演讲者的10个领域的21170个小时的语音数据集。总结如下:
利用Whisper生成数据集的伪标签
上述数据集量很大,且大多数无标签的数据集,为了得到蒸馏后的Whisper模型,HuggingFace使用了原始的Whisper模型来对这些数据集进行标注。
基于知识蒸馏架构的Distll-Whisper模型
Distil-Whisper模型的架构图如下:
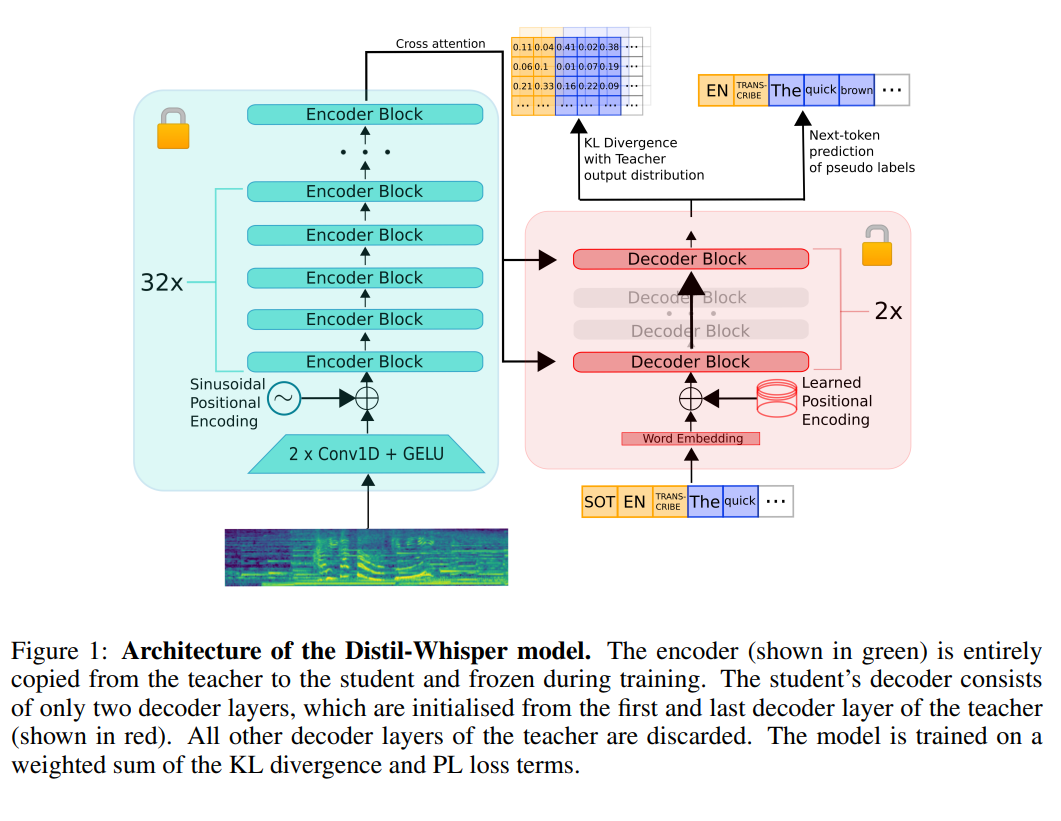
如上图所示,作者保留了原始的Whisper模型的encoder部分,在decoder部分保留了第一层和最后一层,然后中间层全部放弃,重新训练。进行知识蒸馏的训练。
Distil-Whisper效果评估
最终,Distil-Whisper测试结果很好,主要总结如下:
- 蒸馏后的模型 Distil-Whisper 比原始 Whisper 模型快 5.8 倍,参数减少了 51%。
- 在零次转移设置的分布外测试数据上,Distil-Whisper 的 WER 与原始 Whisper 模型相差不到 1%。
- Distil-Whisper 保持了 Whisper 模型对困难声学条件的鲁棒性。
Distil-Whisper模型的信息卡和开源
Distil-Whisper模型开源地址包括GitHub、HuggingFace地址参考DataLearner-Whisper的Distil模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/Distil-Whisper
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
