20条关于DeepSeek的FAQ解释DeepSeek发布了什么样的模型?为什么大家如此关注这些发布的模型?他们真的绕过CUDA限制,打破了Nvidia的护城河了吗?
DeepSeekAI最近发布的几个模型,如DeepSeek V3、DeepSeek R1等引起了全球的广泛关注和讨论,特别是低成本训练出高质量模型之后,引起了很多的争论。引起了大家对OpenAI、英伟达等公司未来的质疑。然而,对于DeepSeekAI的模型为什么引起了如此广泛的关注,以及大家讨论的核心内容是什么,很多人并不是很清楚。本文基于著名的独立科技行业分析师Ben Thompson的总结,配合DataLearnerAI的分析,为大家总结DeepSeek引起的全球讨论。
一、DeepSeekAI发布的模型概述
1、DeepSeekAI发布了什么?
在正式讨论DeepSeek引起的广泛关注之前,我们先简单了解一下DeepSeekAI发布了什么?
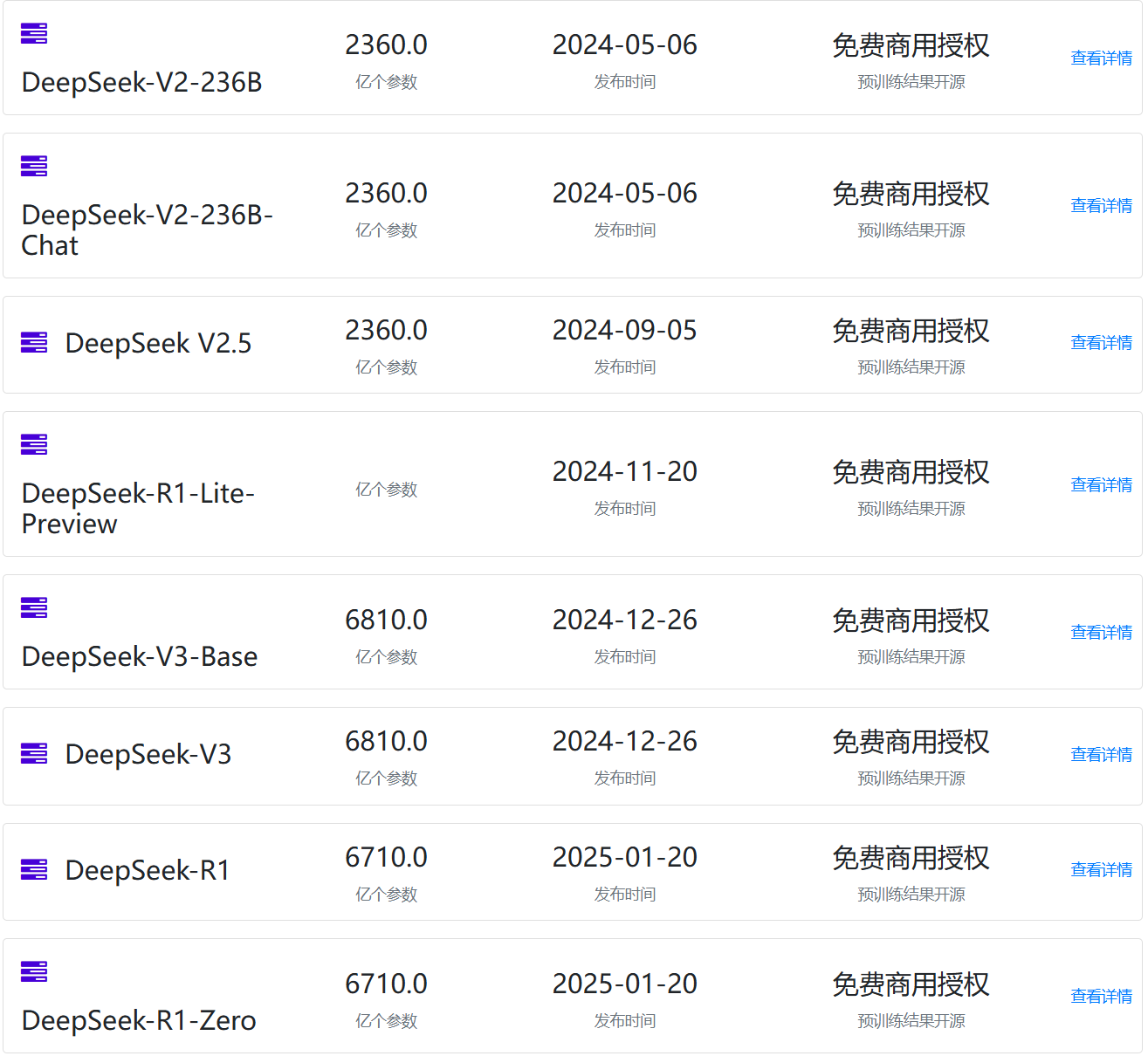
可以看到,DeepSeekAI早在去年5月份就发布并开源了DeepSeek V2版本的模型,而直到12月份发布了DeepSeek V3之后才被全球关注和讨论,2025年1月份,DeepSeek开源了R1推理大模型之后,这个讨论达到了史无前例的热度。
虽然DeepSeek是最近发布的R1模型,但是很多重要披露(包括训练成本)是在圣诞节V3发布时公布的。而许多突破性技术早在去年1月V2发布时就已展示。
总结起来,DeepSeek引起广泛讨论和关注的原因如下:
- 低成本高质量的模型:单次训练成本为550万美元左右,是Llama模型的1/5,传闻也是GPT-4o模型训练的几十分之一,但是效果超过Llama,与GPT-4o也是有来有回;
- 开源且可获得:基于MIT开源协议开源,商用无限制;
- 慷慨的技术分享:团队的技术报告详细描述了训练的细节,并分享了失败的经验;
- 基于硬件特点定制训练方法:基于H800这种带了限制的硬件,做了很多创新的训练方法,提高了训练的效果,甚至让人怀疑此前美国做算力限制的有效性;
以上是DeepSeek引起关注的主要原因,本文继续总结一些大家关注的内容。
2、DeepSeek V3模型是顶级模型吗?
它可以与OpenAI的4o和Anthropic的Sonnet-3.5竞争,似乎比Llama的最大模型(4050亿参数)更好。
二、DeepSeekAI发布的模型技术架构与创新
3、DeepSeek模型的架构创新包括哪些?
DeepSeek模型从V2版本就已经有了突破性技术,在V2版本中,有2个核心技术:
- 改进了混合专家架构,DeepSeekMoE在V2版本中推出,其中仅激活必要的模型参数使得混合专家的推理更高效;在专家之间进行更细粒度的专业化区分,引入共享专家来处理更一般化的能力,改进了训练过程中的负载均衡和路由方式
- 提出了MLA:多头潜在注意力机制,通过压缩key-value存储来可大幅减少推理内存使用。
4、DeepSeek V3的训练成本真的只有550万美元吗?
这个数字仅包含最终训练运行成本,不包括前期研究和实验成本。从技术架构来看这个数字是合理的。DeepSeekAI官方披露是278.8万个H800小时,与此对比,Llama3.3 70B的训练时间是700万个H100小时,Llama 3.1 405B是训练了3084万个H100小时。但是,Llama模型效果实测不如DeepSeek V3,且H100的算力是高于H800的。
5、DeepSeek R1是什么?它和其它推理大模型有什么不同?
DeepSeek R1模型类似OpenAI的o1模型(关于o1模型的介绍参考:https://www.datalearner.com/blog/1051726184271628 )。它可以通过深度思考来解决编程、数学和逻辑问题。但是R1是开源的模型,这是当前唯一具有很强效果以及被OpenAI和Anthropic认为“独立”发现他们在内部做的创新。
6、DeepSeek R1 Zero是什么?为什么它很重要?
DeepSeek R1 Zero是使用强化学习训练的推理模型。它的目的是为了教会其它模型如何推理,并且在没有人类监督的情况下自我进化。相比较其它模型,这个模型更为重要,它可能揭示了OpenAI o1模型训练过程中最大的创新,即如何没有人工参与情况下实现大模型的强化学习微调。即“我们迈出了利用纯强化学习(RL)提升语言模型推理能力的第一步。我们的目标是探索大型语言模型(LLMs)在没有任何监督数据的情况下发展推理能力的潜力,专注于它们通过纯强化学习过程的自我进化。”
不过DeepSeek R1 Zero模型出现了人类难以理解的语言结果以及混乱等,为此他们引入了冷启动数据来微调,以获得了R1模型。
7、传闻DeepSeek使用更低级别的汇编语言PTX进行模型训练,可以替代CUDA或者绕过美国制裁,在任意硬件上运行,对吗?
不准确,需要澄清如下事实:
- 使用 PTX:DeepSeek 确实使用了 PTX,这是英伟达的一种类似汇编的编程语言,用于某些功能而不是替代CUDA。这是他们在 AI 模型训练过程中实现显著优化策略的一部分,尤其是针对 DeepSeek-V3 模型。PTX 允许对 GPU 硬件进行细粒度控制,这在特定场景下可以带来更好的性能。
- 弥补 CUDA 的不足:PTX 并不是直接作为 CUDA 的“替代品”,而是作为一种补充工具,以实现超出标准 CUDA 编程可能达到的性能。CUDA 是一种高级语言,简化了针对英伟达 GPU 的编程,而 PTX 更接近硬件层面,提供了更直接优化的机会。
- 绕过美国限制:进行此类优化的动机可能受到美国对中国出口高端 GPU 限制的影响,这促使像 DeepSeek 这样的公司充分利用他们能够接触到的硬件。然而,使用 PTX 并不是专门为了绕过限制,而是更多地在这些约束下最大化硬件效率。DeepSeek 的方法突显了在有限资源下进行创新,而不是直接绕过限制本身。
总结来说,尽管 DeepSeek 确实利用 PTX 进行了优化,但将其称为 CUDA 的“替代品”过于简化了情况。更准确地说,DeepSeek 将 PTX 与 CUDA 结合使用,以实现特定的性能提升,这间接地应对了美国出口限制带来的一些挑战。
8、DeepSeek如何做到如此低成本的模型训练?
核心的创新包括通过设计特别的模型架构,以获取更加高效的模型训练方法和针对性的GPU优化,如采用更低精度的训练(用FP8而不是FP16/32)。
三、DeepSeek的创新技术对市场和其它公司的影响
9、DeepSeek的方法对模型训练有什么重要意义?
DeepSeek优化了模型架构,使其更加高效,通过在低级别编程GPU来克服带宽限制等挑战,从而能够在现有硬件上以更低的成本进行训练。
简单来说,H800的带宽是有限制的(因为制裁),但是DeepSeek通过使用更低级别的编程语言(如PTX)而不是完全使用CUDA来提升硬件的使用效率。
10、DeepSeek影响了英伟达的生意了吗?大科技公司的股票下跌是否与此相关?
DeepSeek高效的训练方法意味着大家不仅仅依赖英伟达GPU的进步来提升模型训练效果,也要重视模型架构和训练方法的设计。
短期内市场正在消化R1的影响,导致了大科技公司,特别是英伟达为首的卖“铲子”的企业的股票下跌。但从长远看,模型商品化和更便宜的推理对大多数科技公司都有利。
虽然面临挑战,但英伟达仍有三个有利因素:
- 更强大硬件的潜力
- 更低推理成本带来更多使用
- 推理模型需要更多算力
11、哪些公司会因为DeepSeek这样的模型和技术创新收益?
便宜的推理允许类似微软、Amazon、Apple可以以更低的成本提供服务,反过来会导致更大的使用需求,降低基础设施成本。
OpenAI会完蛋吗?不一定。
因为: ChatGPT让OpenAI成为了一个消费科技公司,可以通过订阅和广告建立可持续的消费者业务。
Anthropic可能是周末最大的输家
因为: 其API业务最容易受到商品化趋势的影响。
Apple是潜在赢家
因为:
- 推理内存需求的大幅降低使边缘推理更可行
- Apple Silicon使用统一内存,CPU、GPU和NPU共享内存池
- 苹果的高端硬件实际上有最好的消费级推理芯片(最高192GB RAM,相比NVIDIA游戏GPU最高32GB VRAM)
作者认为Meta是"最大赢家"
因为:
- Meta的业务的每个方面都受益于AI
- 降低的推理成本让Meta的AI愿景更容易实现
- 降低的训练成本有助于Meta保持技术前沿
Google在这场变革中的处境如何?答案是相对较差
因为:
- 硬件需求的降低减弱了他们在TPU方面的相对优势
- 零成本推理增加了取代搜索的产品的可行性
- 虽然Google也能获得更低成本,但任何改变现状的情况可能都是净负面的
13、大型美国实验室为什么没有像DeepSeek那样做优化?
因为: 英伟达不断推出更强大的系统满足他们的需求,付钱给英伟达买更好的硬件是阻力最小的路径。相比之下,DeepSeek被迫在较弱的硬件上做极致优化。
14、Scale AI CEO说DeepSeekAI有5万台H100,这是真的吗?
ScaleAI是AI训练解决方案公司,此前的采访中他们的CEO说DeepSeekAI实际上不可能用H800做出这个模型,他们实际拥有5万个H100的GPU。但是这个讨论没有证实,也没有证据,实际上DeepSeek的很多创新都是为了克服H800相比H100的内存带宽限制。因此,这个论断大概是站不住脚的。
四、DeepSeek创新技术与政治、政策与市场挑战
15、为什么美国人都在恐慌?
主要有三个原因:
- 中国追上美国顶级实验室的震撼
- V3的低训练成本和低推理成本
- 尽管有芯片禁令仍取得这些成就
16、DeepSeek的方法破坏了美国的芯片制裁吗?
从合规性角度来说,它没有。H800硬件此前并不是限制范围内的,他们只是通过优化模型架构来更有效地训练。
17、美国芯片禁令与此关系?
有两面性:
- 一方面显示了美国在软件领域优势的快速消失,导致部分人认为芯片制裁很重要
- 另一方面,早期的芯片禁令直接促使了DeepSeek的创新
18、为什么中国(DeepSeek)开源他们的模型?
DeepSeek认为开源对吸引人才很重要,且如果模型成为商品,长期差异化来自于更优的成本结构。
19、总的来说,这些发展是好是坏?
A: 作者认为总体是积极的:
- 消费者和企业将受益于几乎免费的AI产品和服务
- 大型消费科技公司将受益,因为产品和分发渠道变得更重要
- 中国是大赢家,这可能会进一步释放中国的创新潜力
- 导致有一些美国人在思考美国需要在加强防御措施和增强竞争力之间做出选择,加强防御措施,扩大芯片禁令。或者是承认竞争的现实,放开管制,专注于提升竞争力
20、OpenAI最大的错误是什么?
作者认为是促成2023年拜登AI行政令。他们一直在渲染AI的危险性,同时又在建设它,这种做法既傲慢又徒劳,可能阻碍了真正的创新。
