
DeepSeek V4没有等到,但是DeepSeekAI把DeepSeek V3升级到DeepSeek V3.1了,小幅更新,但核心架构和参数不变
就在几个小时前,DeepSeekAI宣布官方的聊天模型从DeepSeek-V3升级到了DeepSeek-V3.1,上下文拓展至128K。虽然,官方目前没有给出这个模型的详细信息,DataLearnerAI已经搜集到很多信息供大家参考。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
就在几个小时前,DeepSeekAI宣布官方的聊天模型从DeepSeek-V3升级到了DeepSeek-V3.1,上下文拓展至128K。虽然,官方目前没有给出这个模型的详细信息,DataLearnerAI已经搜集到很多信息供大家参考。
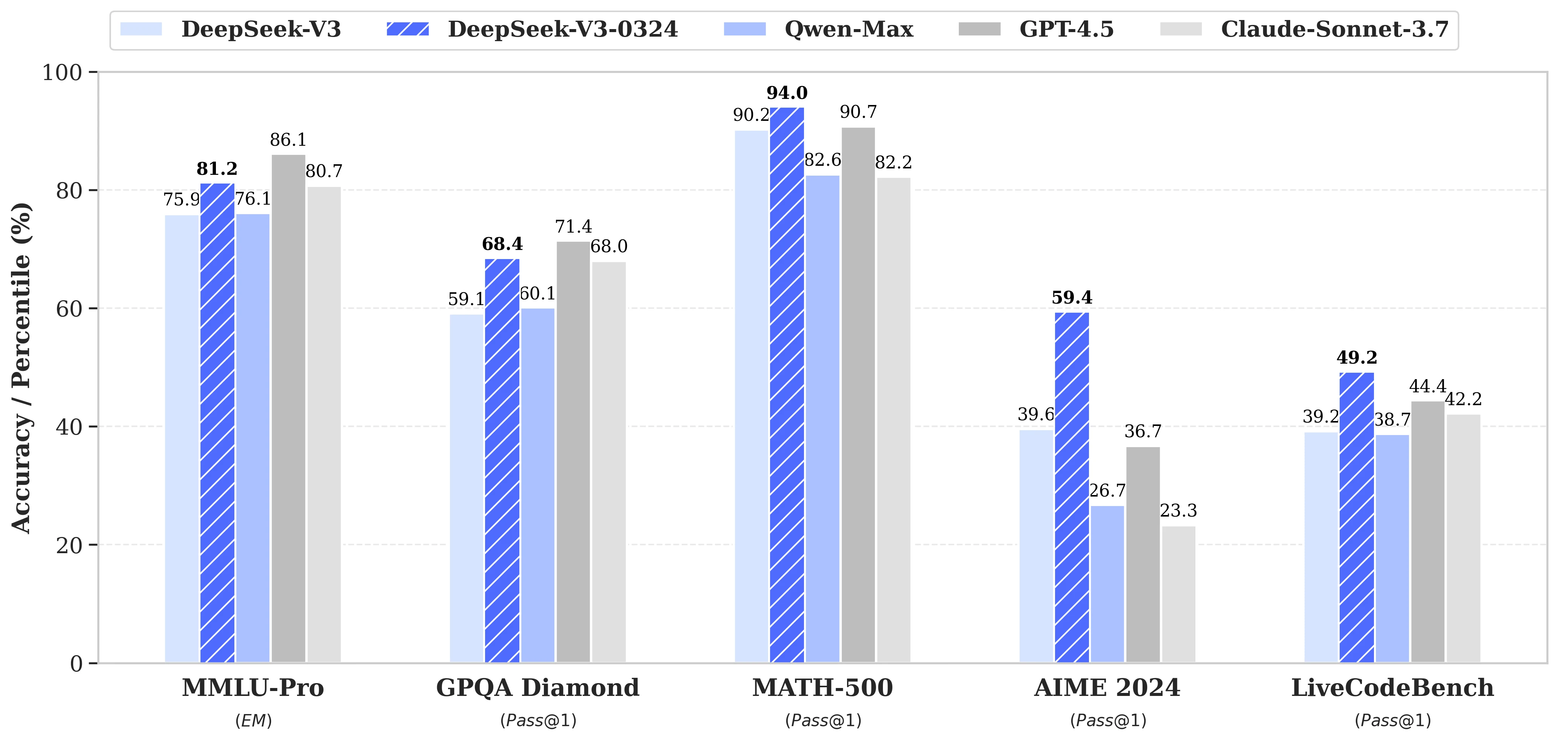
2025年3月25日,DeepSeekAI低调开源了DeepSeek-V3-0324大模型。作为DeepSeek-V3的重要升级版本,该模型在推理能力、中文写作、前端开发以及功能调用等多个关键领域实现了显著提升。在MMLU Pro等评测上,已经成为了非推理大模型中最强的模型,部分评测结果超过GPT-4.5模型。
DeepSeekAI最近发布的几个模型,如DeepSeek V3、DeepSeek R1等引起了全球的广泛关注和讨论,特别是低成本训练出高质量模型之后,引起了很多的争论。引起了大家对OpenAI、英伟达等公司未来的质疑。然而,对于DeepSeekAI的模型为什么引起了如此广泛的关注,以及大家讨论的核心内容是什么,很多人并不是很清楚。本文基于著名的独立科技行业分析师Ben Thompson的总结,配合DataLearnerAI的分析,为大家总结DeepSeek引起的全球讨论。