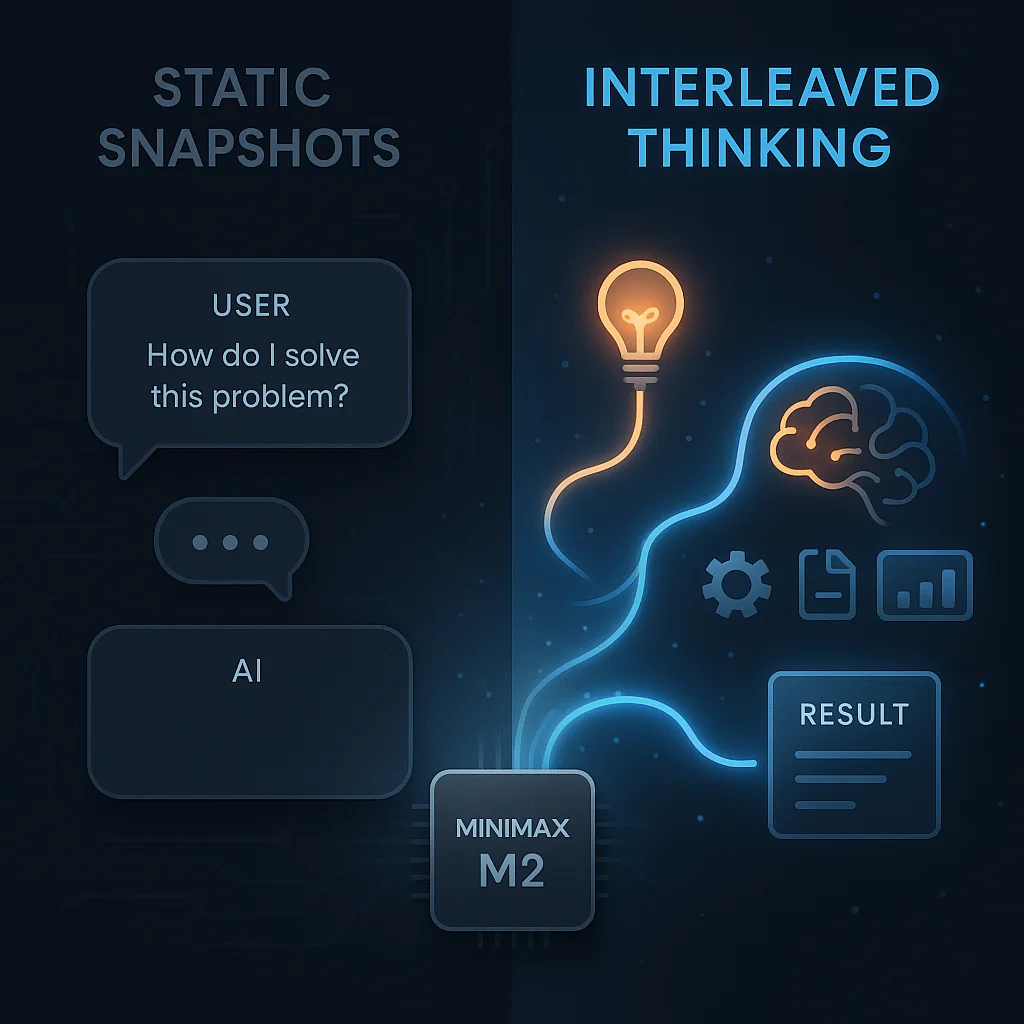
你的MiniMax M2模型效果为什么不好?可能是用错了,官方建议正确使用Interleaved Thinking,模型效果最多可提升35%的效果
MiniMax M2发布2周后已经成为OpenRouter上模型tokens使用最多的模型之一。已经成为另一个DeepSeek现象的大模型了。然而,实际使用中,很多人反馈说模型效果并不好。而此时,官方也下场了,说当前大家使用MiniMax M2效果不好的一个很重要的原因是没有正确使用Interleaved Thinking。正确使用Interleaved thinking模式,可以让MiniMax M2模型的效果最多可以提升35%!本文我们主要简单聊聊这个Interleaved thinking。