OpenAI的推理大模型o1模型的强有力竞争者!DeepSeekAI发布DeepSeek-R1-Lite-Preview~实测结果令人惊喜!
OpenAI的o1模型被认为是大模型领域中推理能力最强的代表之一,由于其强大的数学逻辑推理能力,被认为是大模型未来的进化方向。而就在2个月之后的11月快结束的时间里,幻方量化旗下人工智能企业DeepSeekAI发布了全新的DeepSeek-R1-Lite-Preview模型,号称是o1模型的有力挑战者。该模型利用了类似的o1的思维链思索过程,推理能力大幅增强。DataLearnerAI将在本文中对该模型进行介绍,并进行几个简单的对比结果测试。
关于OpenAI的o1模型可以参考此前DataLearnerAI的介绍博客: 1、重磅!OpenAI发布最强推理模型“OpenAI o1”(代号草莓),大模型逻辑推理能力大幅提升,官方宣称超越部分人类博士水平! 2、OpenAI最新的推理大模型o1与GPT-4o有什么区别?o1一定比o1 mini更强吗?一文总结OpenAI对o1模型的官方答疑
DeepSeek-R1-Lite-Preview模型简介
DeepSeek-R1-Lite-Preview是DeepSeekAI在2024年11月20日宣布的一个全新的大语言模型,官方发布这个模型的时候并没有进行大规模的宣称和介绍,只是在官方的更新日志中提到,这个模型与OpenAI推理模型o1在AIME和数学基准测试中具有差不多的性能。
AIME全称是American Invitational Mathematics Examination,即美国数学邀请赛,是美国面向中学生的邀请式竞赛,3个小时完成15道题,难度很高。
在官方的测试结果中,DeepSeek-R1-Lite-Preview的AIME 2024得分52.5分,比OpenAI的o1-preview模型的44.6分高近8分,比GPT-4o的9.3分高出很多。
在MATH的基准测试(Hendrycks等人在2021年推出的数学数据集,有125000个美国数学竞赛题目)中得分达到91.6分,也是高于o1-preview。
此外,在其它复杂的任务场景,如何代码基准测试Codeforces等方面,DeepSeek-R1-Lite-Preview模型效果表现也很好。
DeepSeek-R1-Lite-Preview模型的能力随着推理长度的增长而变强
根据OpenAI官方的描述,o1模型的训练使用了一种新的AI训练方法,强调了思维链和强化学习的重要性,以及计算资源对性能的影响。OpenAI认为,如果允许更长的推理时间,那么模型的表现越好,这样就暗示了模型本身可能存在一个“思考”-“改进”的过程!这就是所谓的Inference Scaling Laws(推理缩放定律)。
DeepSeekAI也有类似的结论,官方的测试显示DeepSeek-R1-Lite-Preview模型的能力会随着推理长度的增加而显著增强。下图是官方给的测试结果。
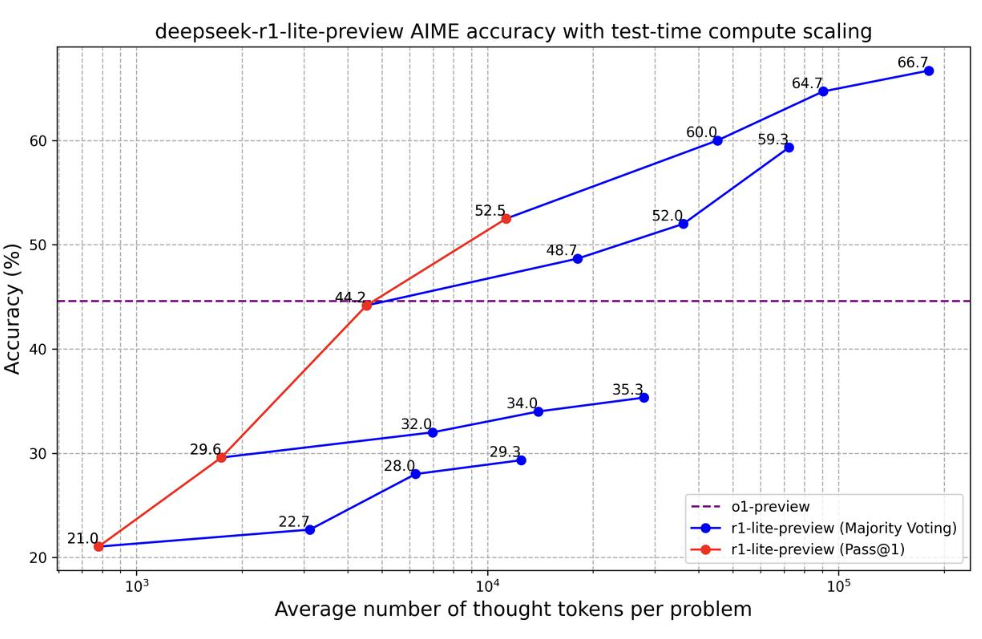
从这个图可以看到,随着推理结果长度的增加,DeepSeek-R1-Lite-Preview模型能力显著增长,在推理长度超过10K的时候,DeepSeek-R1-Lite-Preview模型的能力是超过了OpenAI的o1模型的。不过,由于目前官方没有给出详细的结果,我们还不确定这样的测试背景。毕竟在OpenAI的官方测试中,也有类似的随着推理结果数量和长度的增长,模型能力也会更强。
DeepSeek-R1-Lite-Preview在代码和复杂逻辑的实测效果
为了测试DeepSeek-R1-Lite-Preview模型在复杂任务的效果,DataLearnerAI的团队成员进行了2个测试,分别是生成一个复杂的网页效果,以及一个复杂的数学分析案例。
大模型聊天网页测试
这个测试的结果是让模型生成一个类似ChatGPT的大模型聊天网页,要求是纯粹的HTML+JS+CSS实现,没有限制使用外部第三方的库,但是要求可以本地测试。
这个网页的功能需求说明包含了五个部分,分别是聊天区域、工具调用的展示、上下文管理、自适应布局以及动画效果等。要求的内容比较多。我们测试了GPT-4o、Gemini Experimental 1121(谷歌最新的实验模型,效果据说很强)、Claude Sonnet 3.5以及DeepSeek-R1-Lite-Preview。
首先,我们给出四个模型的测试功能结果:
从这个测试可以看到,这几个模型都能完成核心功能。但是,一些细节有差别,其中谷歌的模型Gemini Experimental 1121能力是最完整的。其它模型都缺少了一点点内容,其中GPT-4o模型没有支持回车按键之后发送消息,十分的可惜。
除了功能外,我们还有几个对比结果:
这里我们第一个关注的是生成结果的代码行数。虽然GPT-4o模型在前面少了一个简单的功能,但是它没有使用第三方库,且代码最少。而其它的模型都使用了第三方的库。在prompt中,我们有提到需要便于本地测试。此外,Claude模型生成的结果第一次运行出错了,让它自己修复了一下。最后一个问题是谷歌的模型,虽然功能完整,但是生成过程分成了三次,每次都需要提示继续生成。
就美观程度来说,Claude模型的结果是最好的,完成度最高,它还有对话头像,且对话框居中并且永远在浏览器中间下方,体验非常好。GPT-4o还可以,剩余两个,只能说很丑了。
下图是展示结果:
GPT-4o的页面截图
Gemini的页面截图
Claude页面截图
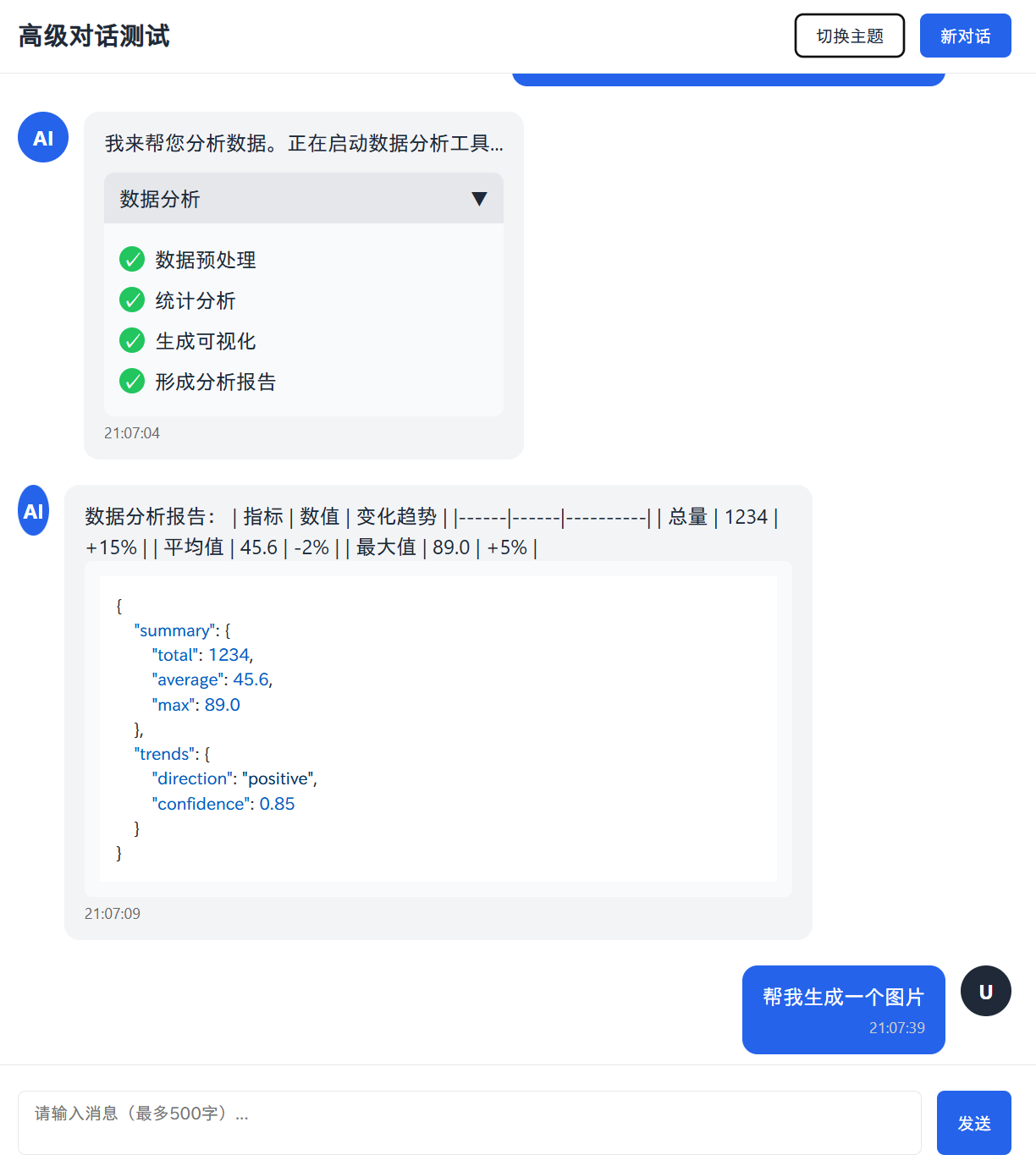
DeepSeek-R1-Lite-Preview的页面截图
数据分析测试
为了测试DeepSeek-R1-Lite-Preview模型在复杂的数据分析推理的效果,我们也测试了一个模糊的数据分析问题。我们给出了几组用户连续2个月的不同的电信业务使用情况,然后问,哪个用户使用的业务量下降最多。
测试数据如下:
这个问题其实很复杂,也缺少明确的含义。原因是考虑业务使用下降需要考虑不同业务的差异,下降最多其实是可以有多个不同的答案的。这里1001用户的业务下降百分比其实比较多。但是1003用户的流量绝对值下降最大,所以有干扰。
最终测试结果,DeepSeek-R1-Lite-Preview的分析过程非常不错,基本考虑了所有的场景。而只看结果的话,Claude和Gemini的模型应该是更合理~
GPT-4o的分析结果
GPT-4o模型直接把通话时长、流量使用等不同业务的变化结果相加,这个显然是不合理的。毕竟,语音10分钟和流量1000MB是不一样的。
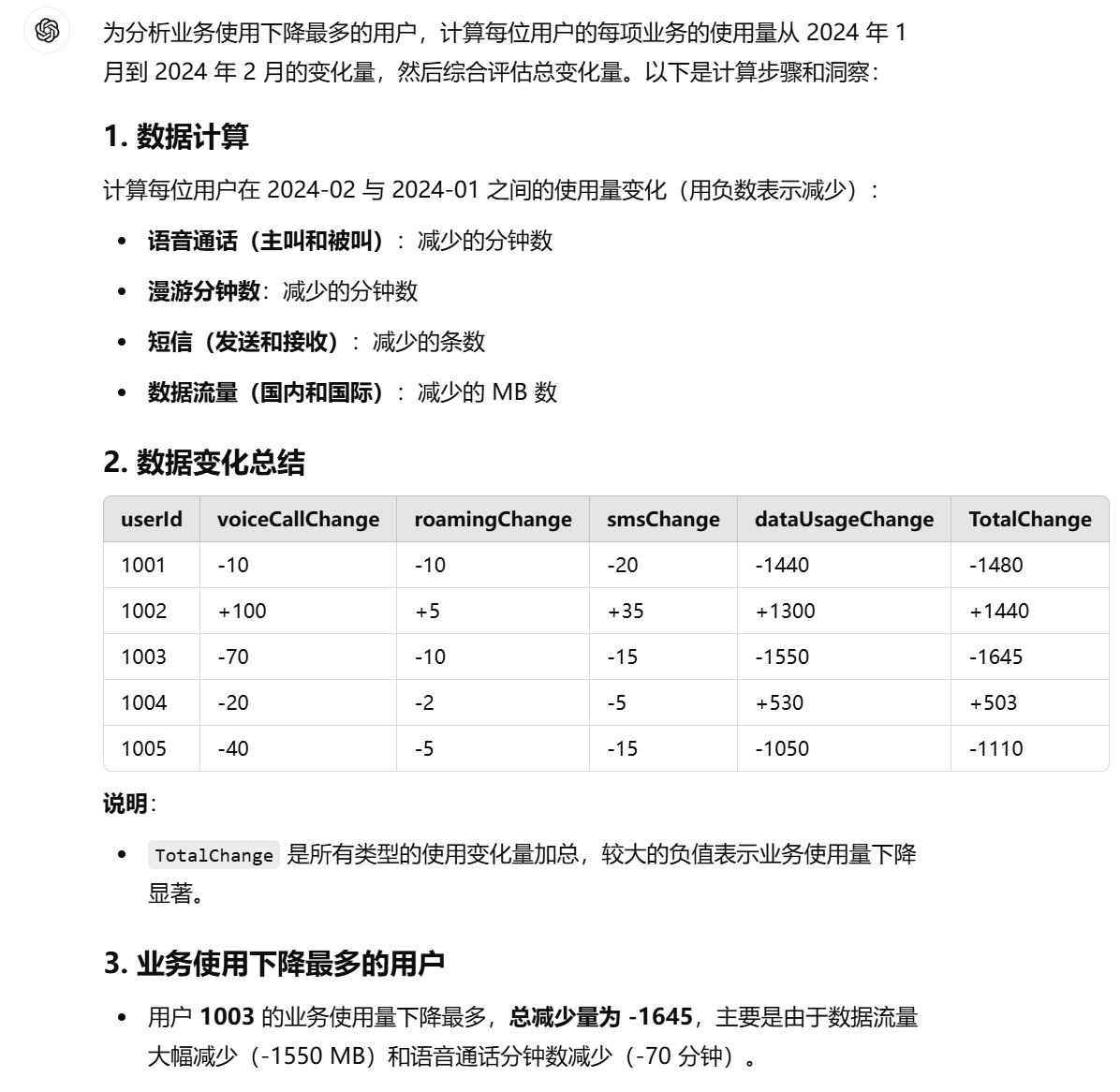
GPT-4o根据绝对值给出的是1003用户下降最多。
Gemini的分析结果
相比较GPT-4o,Gemini的分析要合理一点,它给出了所有用户每一个业务的下降绝对值和百分比,然后用下降幅度来表示,最终认为1001用户下降最多。

Claude Sonnet 3.5的分析结果
Claude Sonnet 3.5的结果类似,也是使用了下降百分比的方式计算,给出了最终是1001用户下降最为明显。
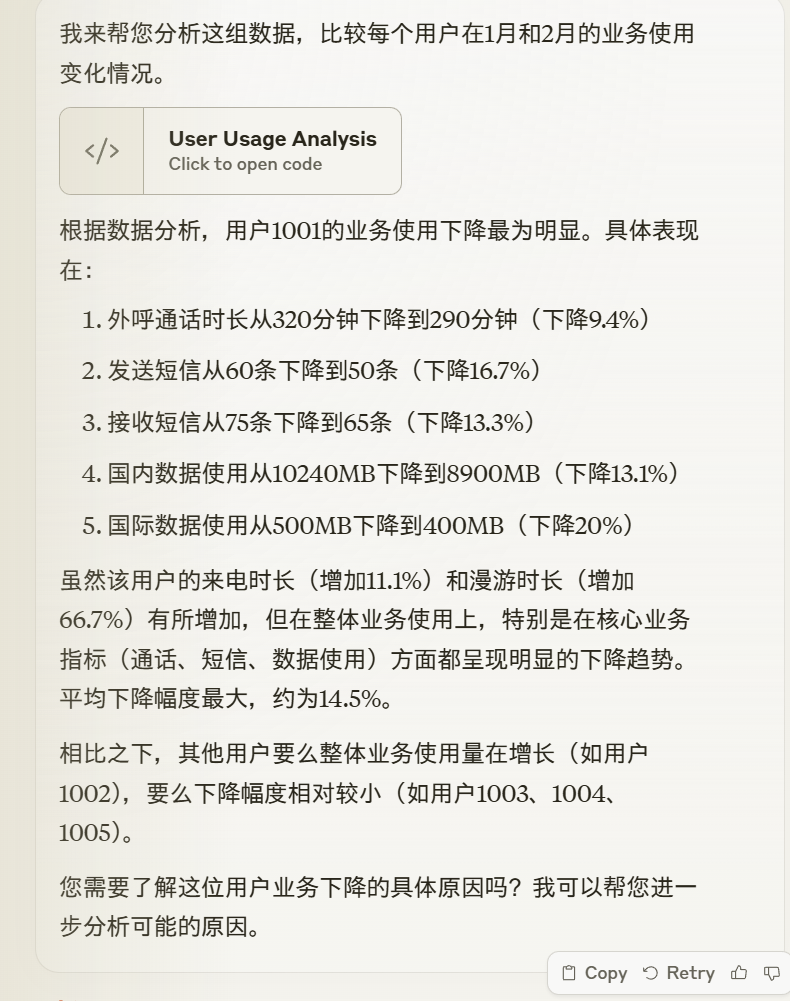
DeepSeek-R1-Lite-Preview的分析结果
DeepSeek-R1-Lite-Preview的分析使用了66秒的时间,它给出了思维链过程。这个过程非常有意思。
首先,DeepSeek-R1-Lite-Preview分析了这个问题,给出了不同的思路的差异:
好,我有一组用户的数据,我需要找出业务使用下降最多的用户。首先,我得理解这些数据是什么意思。表格里有用户ID、月份,然后是各种业务的使用情况,比如语音通话的主叫和被叫分钟数,漫游分钟数,短信发送和接收数量,以及国内和国际的数据使用量,单位是MB。
我的目标是找出在2024年1月到2月期间,哪个用户的业务使用下降得最多。那我得比较每个用户在这两个月的各项业务使用情况,看看哪些业务减少了,减少了多少。
首先,我需要确定哪些业务可以用来衡量“业务使用”。看起来,所有的列除了userId和month,都是业务使用的指标。可能需要综合考虑这些指标的变化。
但是,不同的业务可能有不同的重要性,比如数据使用可能比短信更重要,或者语音通话更重要,这得根据具体情况来定。不过题目没有说要按权重来算,可能需要简单地比较各项业务的使用量变化。
也许可以计算每个用户在各项业务上的下降量,然后把它们加起来,看哪个用户的总下降量最大。
这个分析其实很不错了。然后,它使用绝对值去给出结果,分析得到1003用户下降最多。然后又觉得不合适,开始计算下降百分比,最后觉得每个业务单独计算下降百分比然后相加不好,给出了新的逻辑,即计算每个业务的下降量,然后加总所有业务的下降量,再除以所有业务在1月的总量,得到总的下降比例。。不能说这个思路有问题,但和1也没啥区别,属于不合理的内容。综合这三个结果,给出了1003用户下降最多。

从这些测试也可以看出来,谷歌即将发布的Gemini模型也是很强的。
DeepSeek-R1-Lite-Preview总结
根据上面的分析和总结,我们可以看到,DeepSeek-R1-Lite-Preview并不是当前最优秀的模型,但是其分析过程和效果已经是和全球最强的模型不相上下了。其中,网页的结果虽然有点丑,但是功能上还是不错的。而分析数据的结果,虽然结论不合理,但是思维链过程是很精彩的。
目前已经可以在DeepSeek官网使用这个模型:https://chat.deepseek.com/ ,开启DeepThink即可。
最重要的,官方给出的信息是,未来DeepSeek-R1-Lite-Preview会开源!而根据这个名称是Lite来看,其实可能这个模型本身的规模没有那么大,那背后是否有更强的DeepSeek-R1呢?非常期待。
关于DeepSeek-R1-Lite-Preview模型的更多信息可以关注DataLearnerAI的模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/DeepSeek-R1-Lite-Preview
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
