开源大语言模型再次大幅进步:微软团队开源的第二代WizardLM2系列在MT-Bench得分上超过一众闭源模型,得分仅次于GPT-4最新版
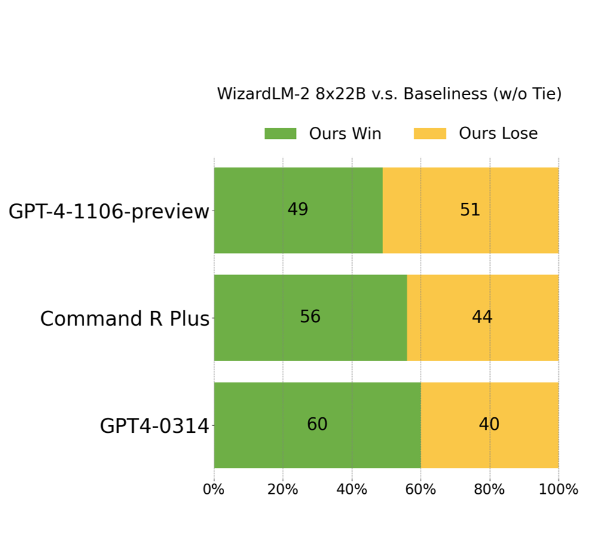
开源大模型是促进大模型技术发展最重要的技术力量之一。此次,微软以Apache 2.0开源协议开源了一个在ChatArena匿名投票评测上打败GPT-4早期版本的模型,即WizardLM-2。这是一系列模型,其中最大的版本是基于Mixtral-8×22B开源模型进行后训练得到的模型。MT-Bench得分8.96,超过了GPT-4-0314。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
开源大模型是促进大模型技术发展最重要的技术力量之一。此次,微软以Apache 2.0开源协议开源了一个在ChatArena匿名投票评测上打败GPT-4早期版本的模型,即WizardLM-2。这是一系列模型,其中最大的版本是基于Mixtral-8×22B开源模型进行后训练得到的模型。MT-Bench得分8.96,超过了GPT-4-0314。
WizardLM是微软联合北京大学开源的一个大语言模型。此前,发布的WizardLM和WizardCoder都是业界开源领域最强的大模型。其中,前者是针对指令优化的大模型,而后者则是针对编程优化的大模型。而此次WizardMath则是他们发布的第三个大模型系列,主要是针对数学推理优化的大模型。在GSM8K的评测上,WizardMath得分超过了ChatGPT-3.5、Claude Instant-1等闭源商业模型,得分十分逆天!