标签
「监督学习」相关文章
汇总「监督学习」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
标签:#监督学习
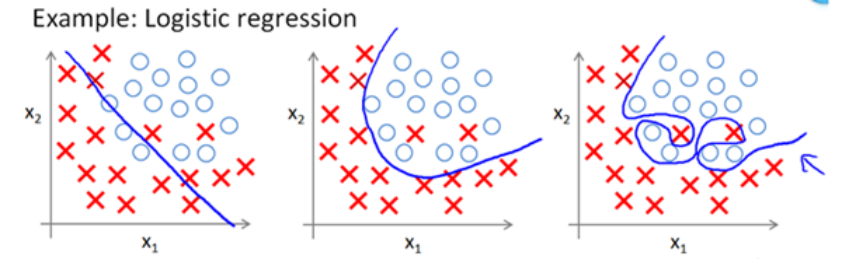
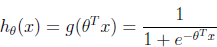
分类和Logistic回归
监督学习中的分类问题和Logistic回归常常被用于推荐问题中关于BPR的研究,但是为什么一定要用Logistic函数来建模和优化呢?本篇博客将带你揭晓奥秘~
汇总「监督学习」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
监督学习中的分类问题和Logistic回归常常被用于推荐问题中关于BPR的研究,但是为什么一定要用Logistic函数来建模和优化呢?本篇博客将带你揭晓奥秘~