准备迎接超级人工智能系统,OpenAI宣布RLHF即将终结!超级对齐技术将接任RLHF,保证超级人工智能系统遵循人类的意志
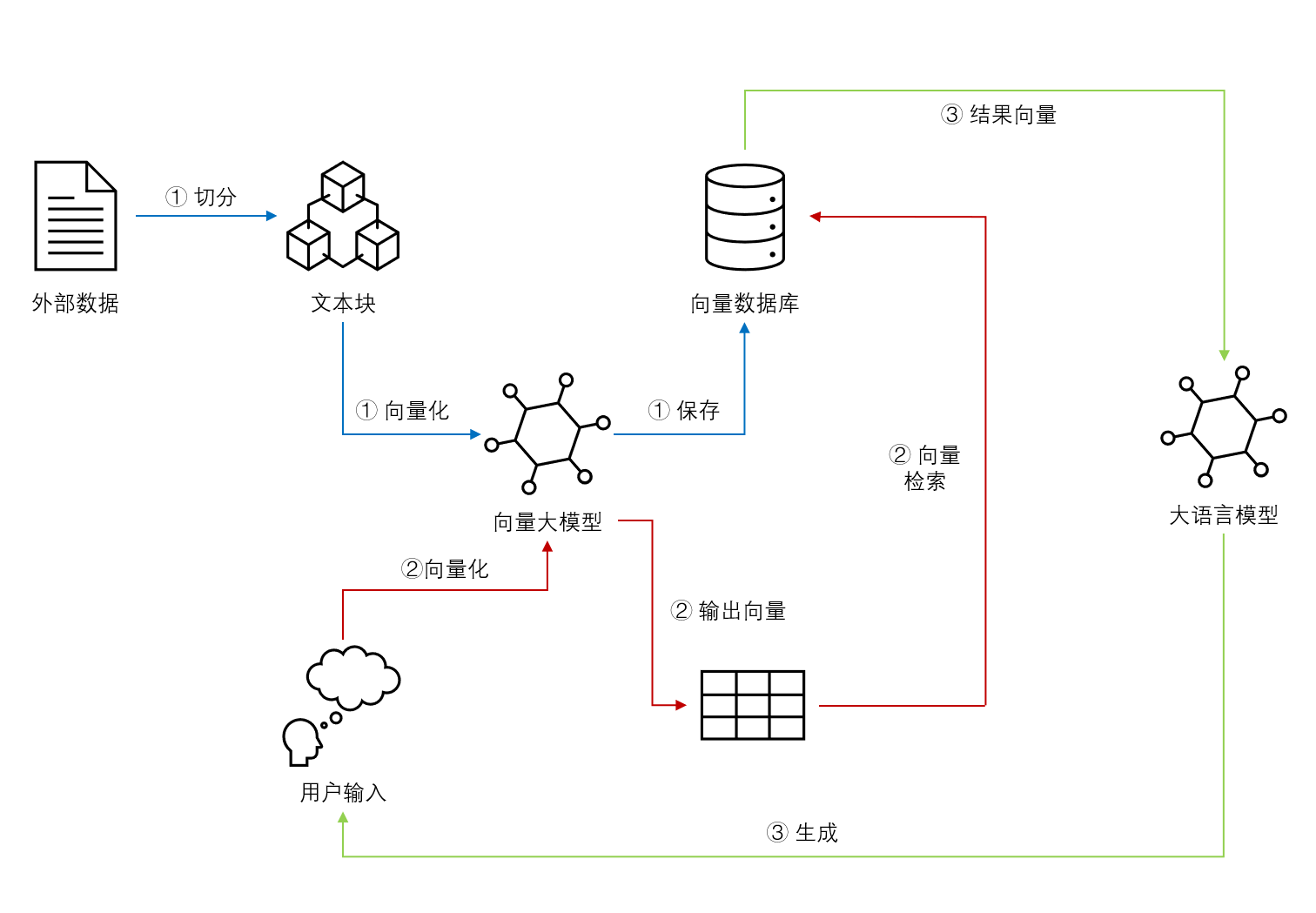
今天,OpenAI在其官网上发布了一个全新的研究成果:一个利用较弱的模型来引导对齐更强模型的能力的技术,称为由弱到强的泛化。OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。因为彼时,人类的水平不如AI系统,所以可能无法再对模型输出的内容评估好坏。为此,OpenAI提出这种超级对齐技术,希望可以用较弱的模型来对齐较强的模型。这样可以在出现比人类更强的AI系统之后可以继续让AI模型可以遵循人类的意志、偏好和价值观。