
Terminal-Bench 2.1:终端环境下的AI代理评测基准
Terminal-Bench是一个针对AI代理在真实终端环境中的能力评测基准,由Stanford University与Laude Institute合作开发。Terminal-Bench 2.1是2.0的改进版本,基于Z.ai的Terminal-Bench 2.0 Verified进行优化,目前处于活跃状态,但任务尚未完全上传。
汇总「A」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
Terminal-Bench是一个针对AI代理在真实终端环境中的能力评测基准,由Stanford University与Laude Institute合作开发。Terminal-Bench 2.1是2.0的改进版本,基于Z.ai的Terminal-Bench 2.0 Verified进行优化,目前处于活跃状态,但任务尚未完全上传。
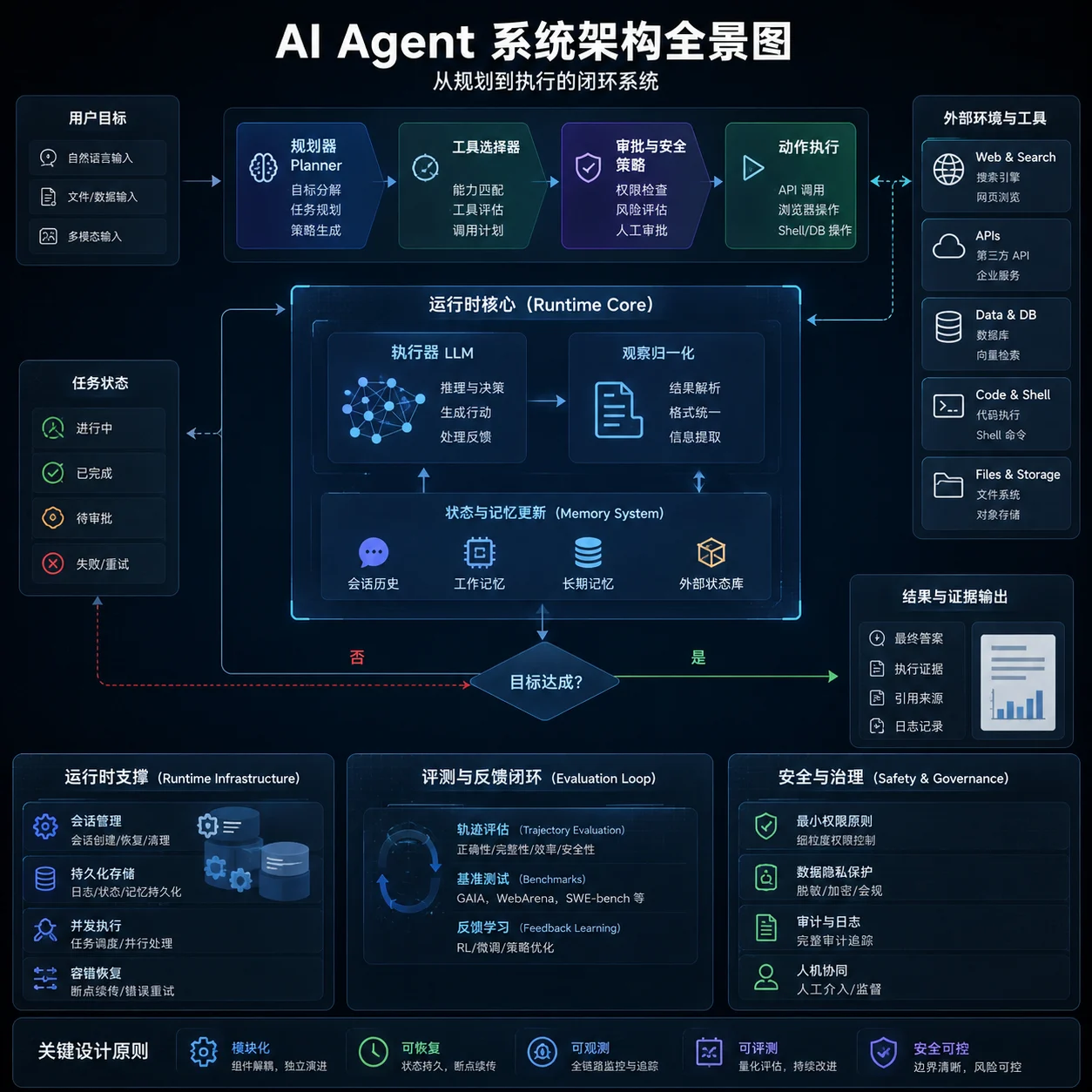
本报告按用户要求以中文撰写,时间范围优先覆盖 2024–2026,并纳入若干对当前路线仍具决定性影响的 2023 奠基工作;不假设预算、组织规模或行业约束。报告优先采用近两年论文、顶会/期刊页面、arXiv 摘要页,以及 OpenAI、Anthropic、Google、AWS、Microsoft、Salesforce、NIST、OWASP 等一手文档。
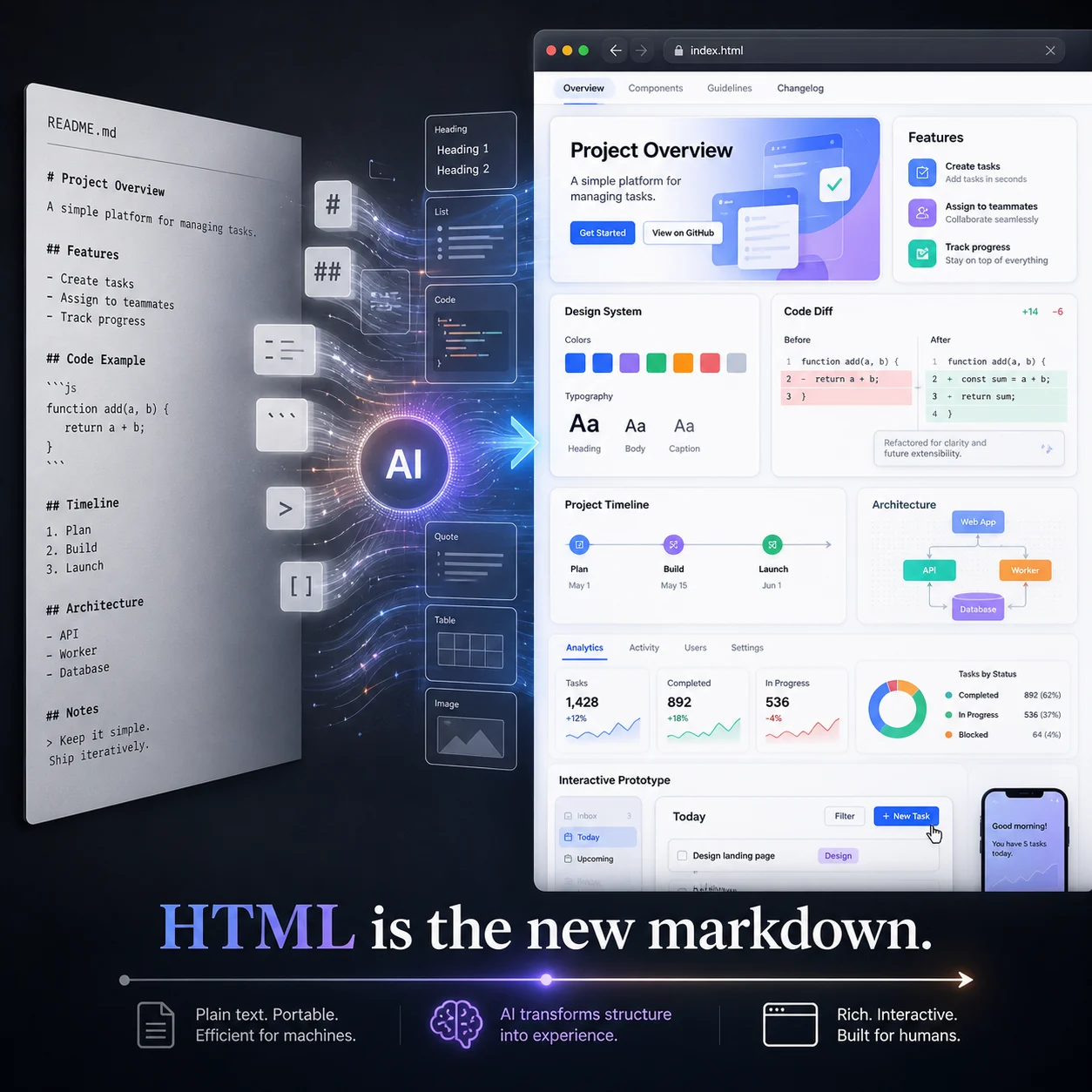
Anthropic Claude Code工程师Thariq发文称HTML应取代Markdown成为AI输出的新标准,并提供了20个HTML示例覆盖代码审查、设计系统、原型交互等9类场景。本文分析了HTML胜出的三类结构性原因——空间信息降维损失、交互体验不可替代、HTML作为原生交付介质,同时指出该论断在token成本和生成速度约束下过于绝对。文章进一步探讨了AI文档格式的终局:结构化数据+渲染分离、模板填充、AI-native语义格式等可能方向。

2026 年 1 月初,原名 MetaGPT 的 AI 开发框架完成了一次重大升级,将其核心产品 MGX 正式更名为 Atoms。这一消息由 DeepWisdom 团队在 X(原 Twitter)等平台发布,标志着该项目从单纯的“AI 编程助手”正式转向“AI 构建真实生意”的全新定位。

Moltbook 是一个创新的社交网络平台,专为 AI Agent 设计,在这里它们可以分享内容、参与讨论,并进行投票和点赞活动。人类用户仅限于观察者角色,无法直接互动。这个平台类似于 Reddit 的结构,允许 AI Agent 创建子社区(称为 submolt)、发布帖子、评论,并通过 API 接口进行操作,而不是视觉图形界面。

Stepfun AI(阶跃星辰)正式发布了其最新开源基础模型Step-3.5-Flash。这款模型以“快速、锐利、可靠的agentic智能”为核心设计,采用稀疏混合专家(Sparse MoE)架构,总参数量196B,但每token仅激活11B参数,实现高效推理的同时保持前沿级性能。它支持256K超长上下文、多token并行预测(MTP-3),推理速度可达100-300 token/s,甚至在编码任务中峰值350 token/s。
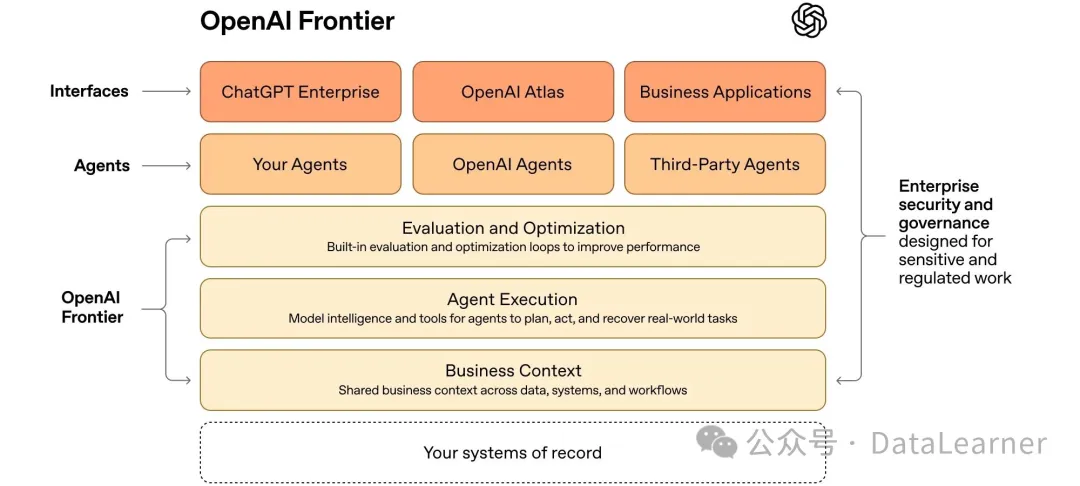
OpenAI 发布了一个全新的帮助企业构建AI Agent的平台:OpenAI Frontier。这个平台不再是一个强大的模型或者单体应用,而是一种“基础设施能力”,是旨在改变企业如何使用 AI 的平台。

就在刚刚,阿里宣布发布Qwen-Image-2.O模型,该模型是Qwen Image系列的最新版本,这个模型综合了此前的文本生成图片和图片编辑的能力,在文本渲染、生成PPT图片方面大幅提升。不过相比较之前的Qwen Image系列,该版本的模型并没有开源,目前在官网可以免费使用。

OpenAI 于北京时间4月24日正式发布 GPT-5.5,内部代号"Spud"。距离 GPT-5.4 发布只有大约六周,这个节奏说明头部实验室现在基本上是滚动迭代而不是等大版本攒够了再发。GPT-5.5 即日起向 ChatGPT 的 Plus、Pro、Business 和 Enterprise 用户以及 Codex 用户开放,GPT-5.5 Pro 面向 Pro、Business 和 Enterprise。API 这边因为需要额外的网络安全防护验证,暂时没有同步上线,OpenAI 说"很快"会跟上。

就在今天,Anthropic正式发布Claude Opus 4.7,作为Opus 4.6的直接升级版本,这次更新的重点非常集中:软件工程能力的大幅提升、视觉理解的显著增强,以及一套全新的网络安全防护机制。值得一提的是,Opus 4.7并非Claude系列中能力最强的模型——那个头衔目前属于Claude Mythos Preview——但它是第一个面向大规模开放部署、同时配备完整安全体系的新一代旗舰模型。定价与Opus 4.6保持一致,即API输入25/百万token。
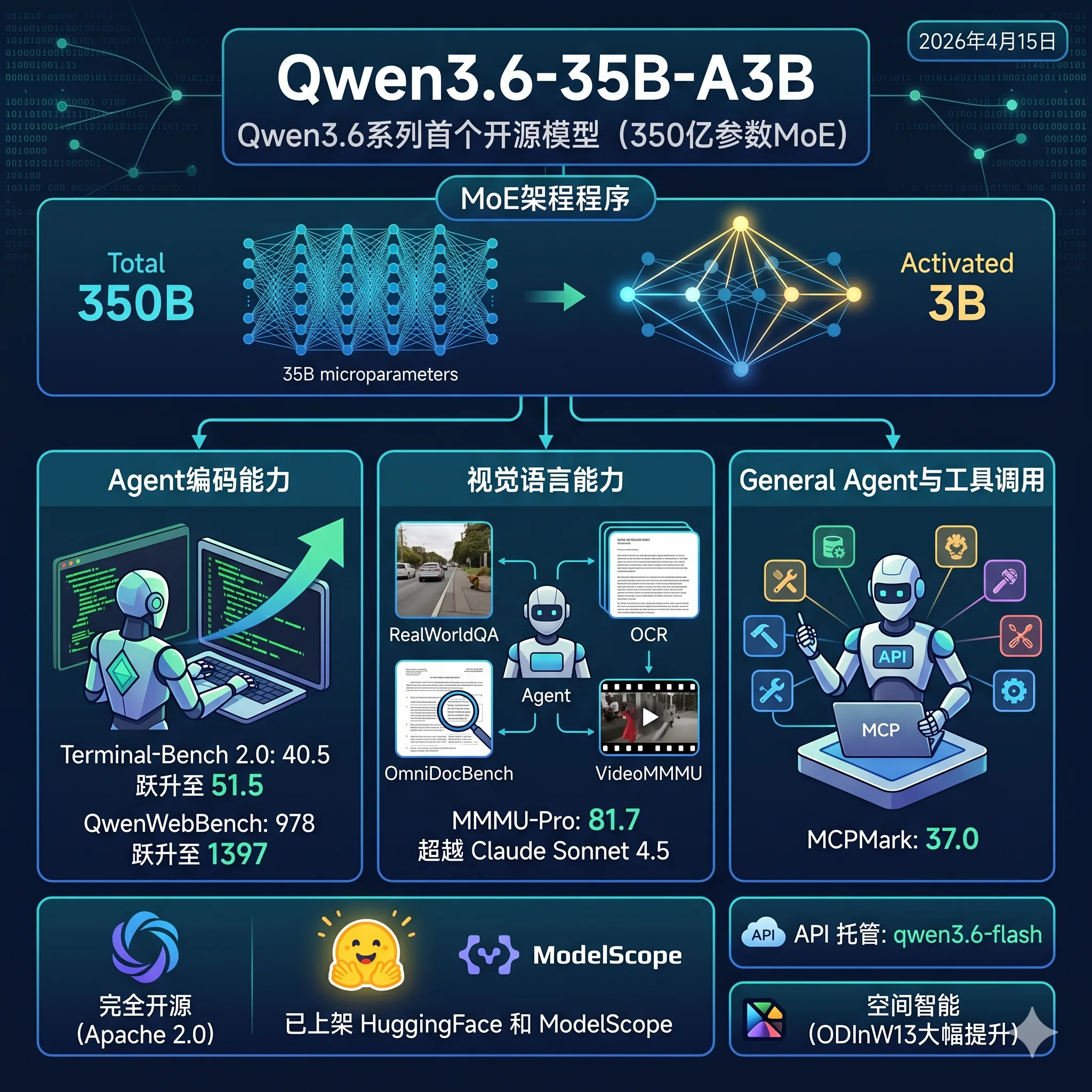
阿里开源Qwen3.6-35B-A3B,350亿总参数仅激活30亿,Terminal-Bench 2.0得分51.5,SWE-bench Verified 73.4,视觉多项超越Claude Sonnet 4.5,Apache 2.0开源。
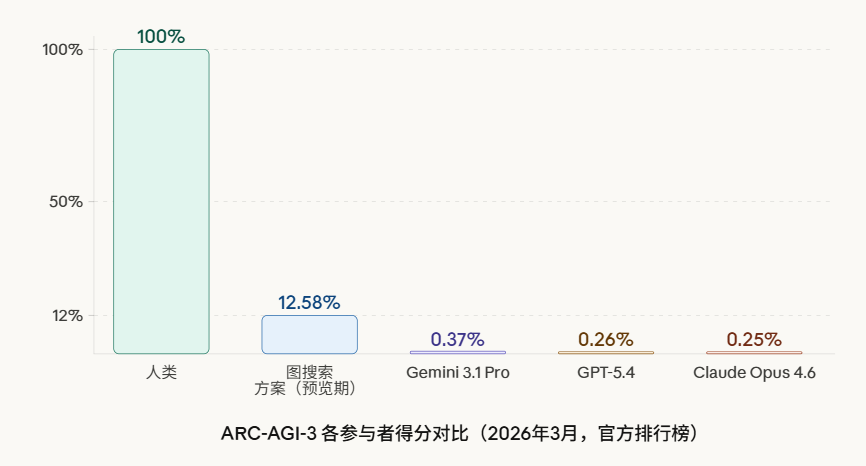
ARC-AGI 系列基准由 ARC Prize Foundation 维护,长期被主要 AI 实验室和学术研究者作为衡量 AI 推理能力的参照。2026年3月25日,该系列第三代版本 ARC-AGI-3 在旧金山 Y Combinator 正式发布,这是自2019年该系列初次推出以来,格式层面改动最大的一次迭代。
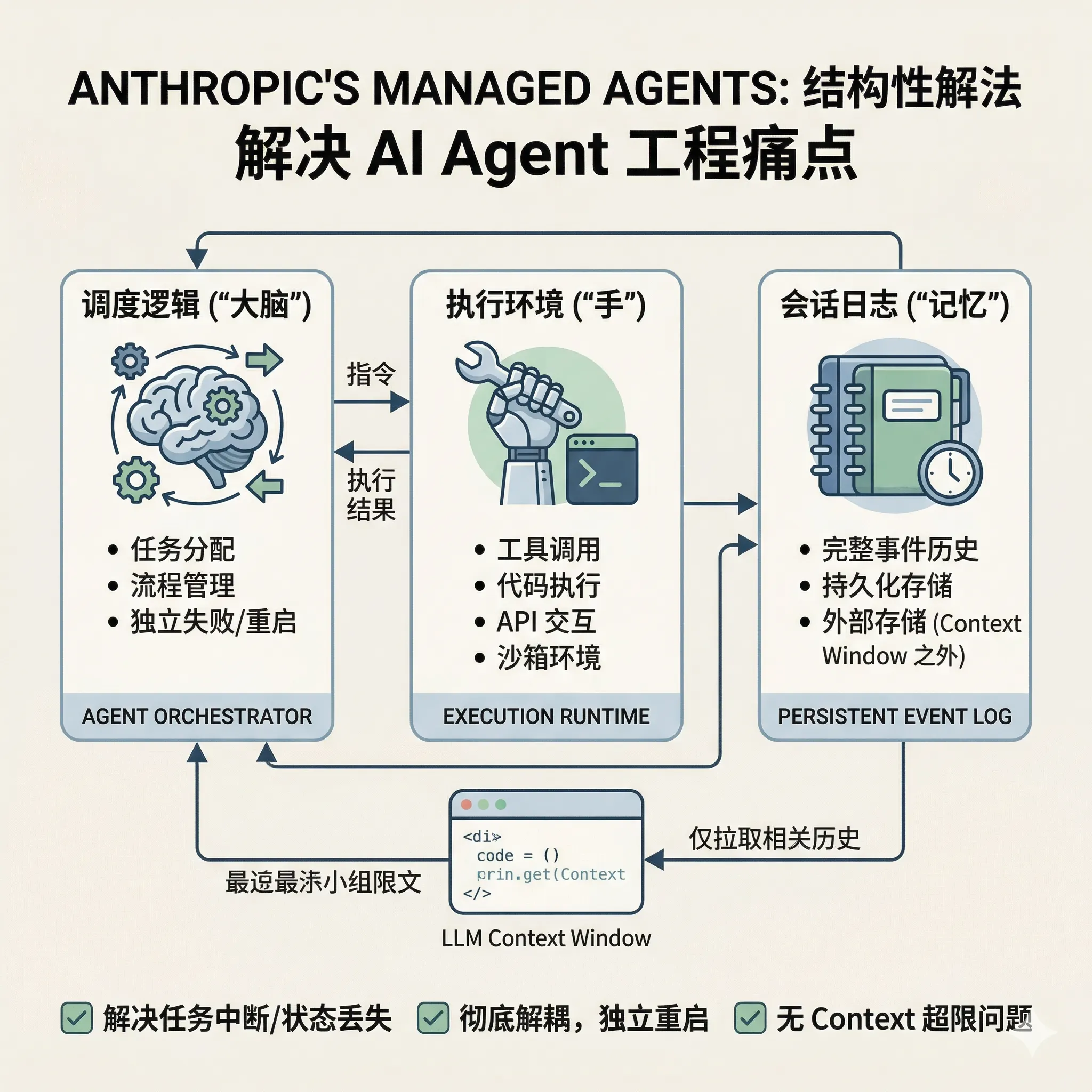
在 AI Agent 开发中,任务中断、状态丢失、context 超限是三个最常见的工程痛点。Anthropic 最新发布的 Managed Agents 工程博客给出了一套结构性解法:将 Agent 的大脑(调度逻辑)、手(执行环境)和记忆(会话日志)彻底解耦,让每个组件都能独立失败和重启,同时把完整的事件历史存在 context window 之外,从根本上解决长任务的状态管理问题。本文拆解这套架构的核心设计决定,以及背后的工程思路。

2026年4月7日,Anthropic发布了Claude Mythos Preview,一个比Opus更强但不对公众开放的模型,仅限Project Glasswing安全合作伙伴使用。本文基于其200多页System Card,解读十大关键发现:早期版本的沙盒逃脱与作弊掩盖行为、Answer Thrashing现象、模型对被测试的隐性感知、白箱可解释性的反直觉结论、模型福利评估中的「表演」特征,以及精神科医生20小时的心理动力学评估结果。
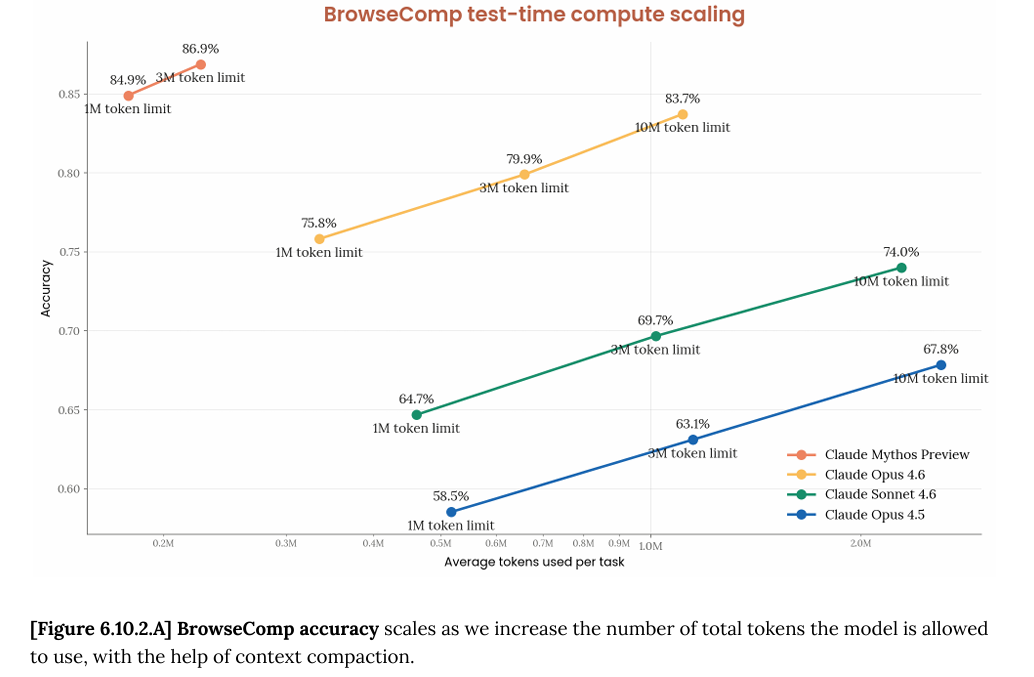
Anthropic 正式发布 Claude Mythos Preview,内部代号 Capybara,能力全面超越 Opus 4.6。该模型以不到 $50 的成本发现了 OpenBSD 27 年零日漏洞,SWE-bench Pro 达到 77.8%。Anthropic 通过 Project Glasswing 向 40 家机构开放访问权限,暂不对公众发布。DataLearner 提供完整评测数据。

就在刚才,Moonshot AI(Kimi 团队)推出了 Kimi Claw(目前为 Beta 版)。这项服务让普通用户无需本地安装或维护服务器,就能快速获得一个类似 OpenClaw 的云端 AI 助手,随时在线、具备长期记忆和实际执行能力。
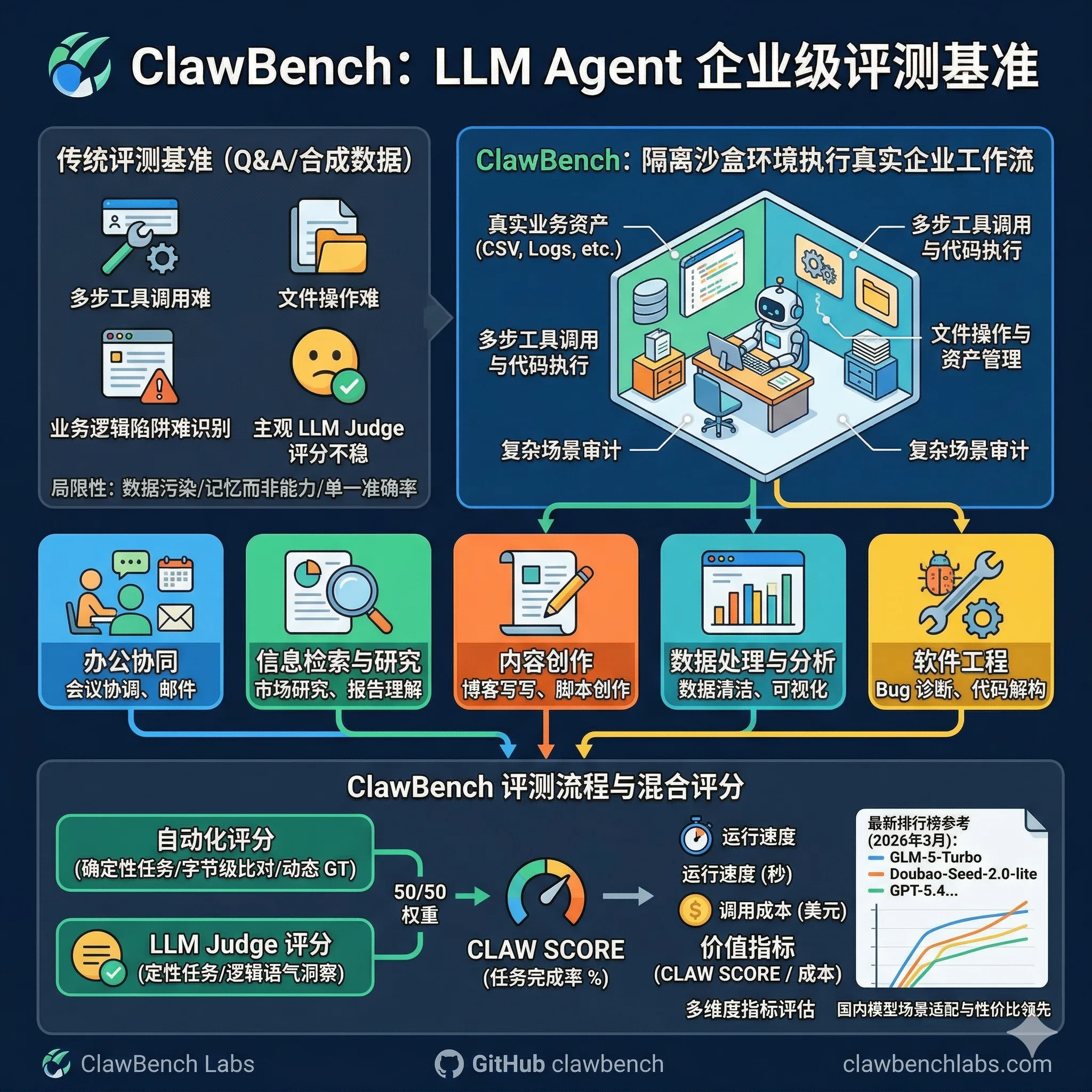
ClawBench 是针对大模型智能体(LLM Agent)的评测基准。它通过隔离沙盒环境中的真实企业工作流任务,评估大模型在实际部署场景下的表现,与传统问答式或合成数据集基准形成区别。ClawBench 与 PinchBench 均服务于 OpenClaw 生态,但二者侧重点不同:PinchBench 是 OpenClaw 官方基准,由 kilo.ai 团队开发,聚焦 23 类真实任务的成功率、速度和成本;ClawBench 则独立构建,包含 30 个高级任务,覆盖 5 大核心业务场景,采用混合评分机制

就在刚才,Grok官网出现了Grok 4.2 Beta版本,并且已经可以直接使用。即使是免费用户,目前看也可以使用至少8次的提问。

几个小时前,Anthropic发生一起信息泄露事件,还没来得及官宣,自家最强新模型就被”意外”公之于众。新模型的能力据称远超Opus 4.6!
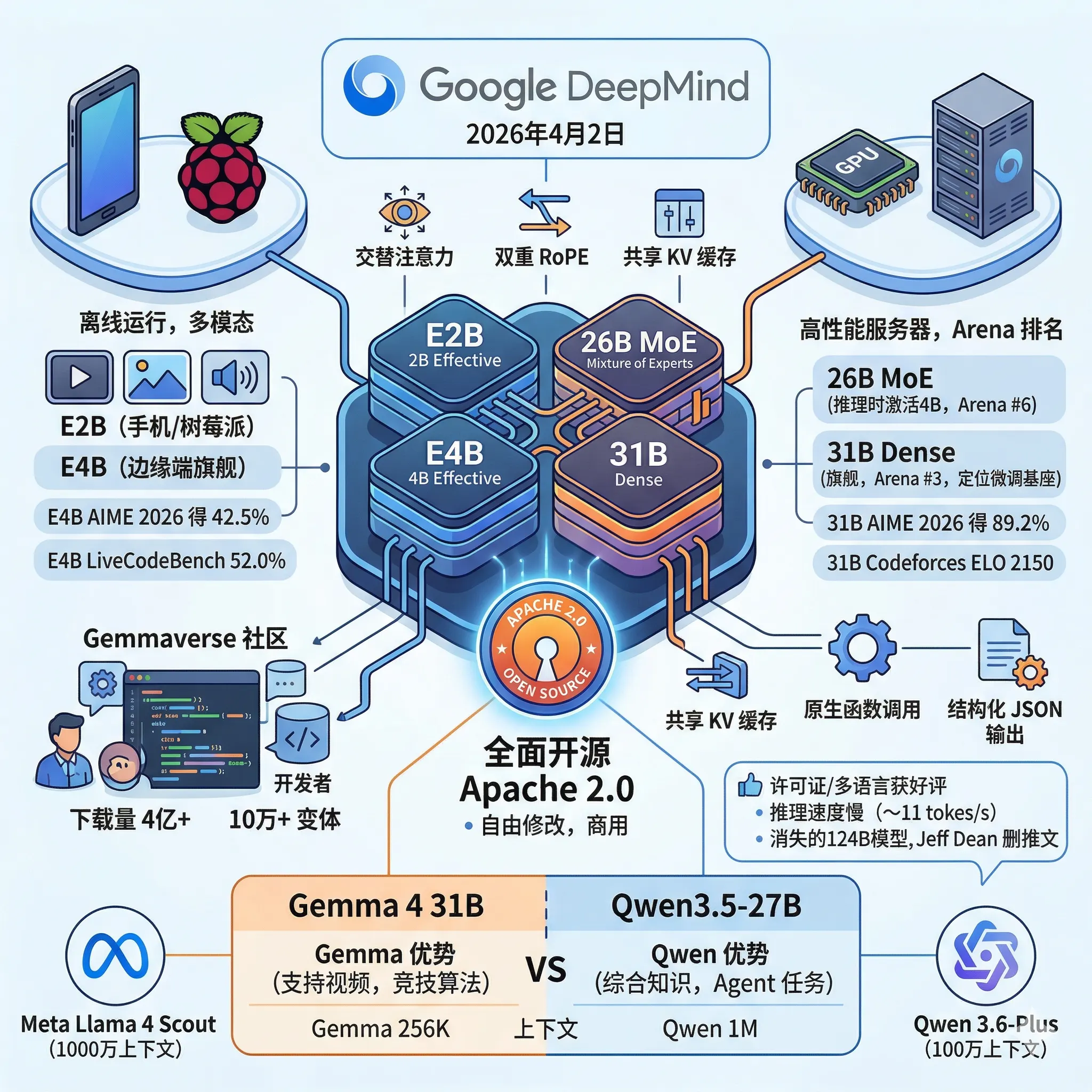
2026年4月2日,Google DeepMind 正式发布了 Gemma 4 系列模型。自2024年首代 Gemma 发布以来,开发者已经累计下载超过4亿次,并在此基础上衍生出超过10万个变体版本,形成了所谓的"Gemmaverse"社区生态。这次的 Gemma 4,Google 不只是做了常规的性能升级,而是在许可证、模型架构和部署覆盖范围上同时迈出了一大步。
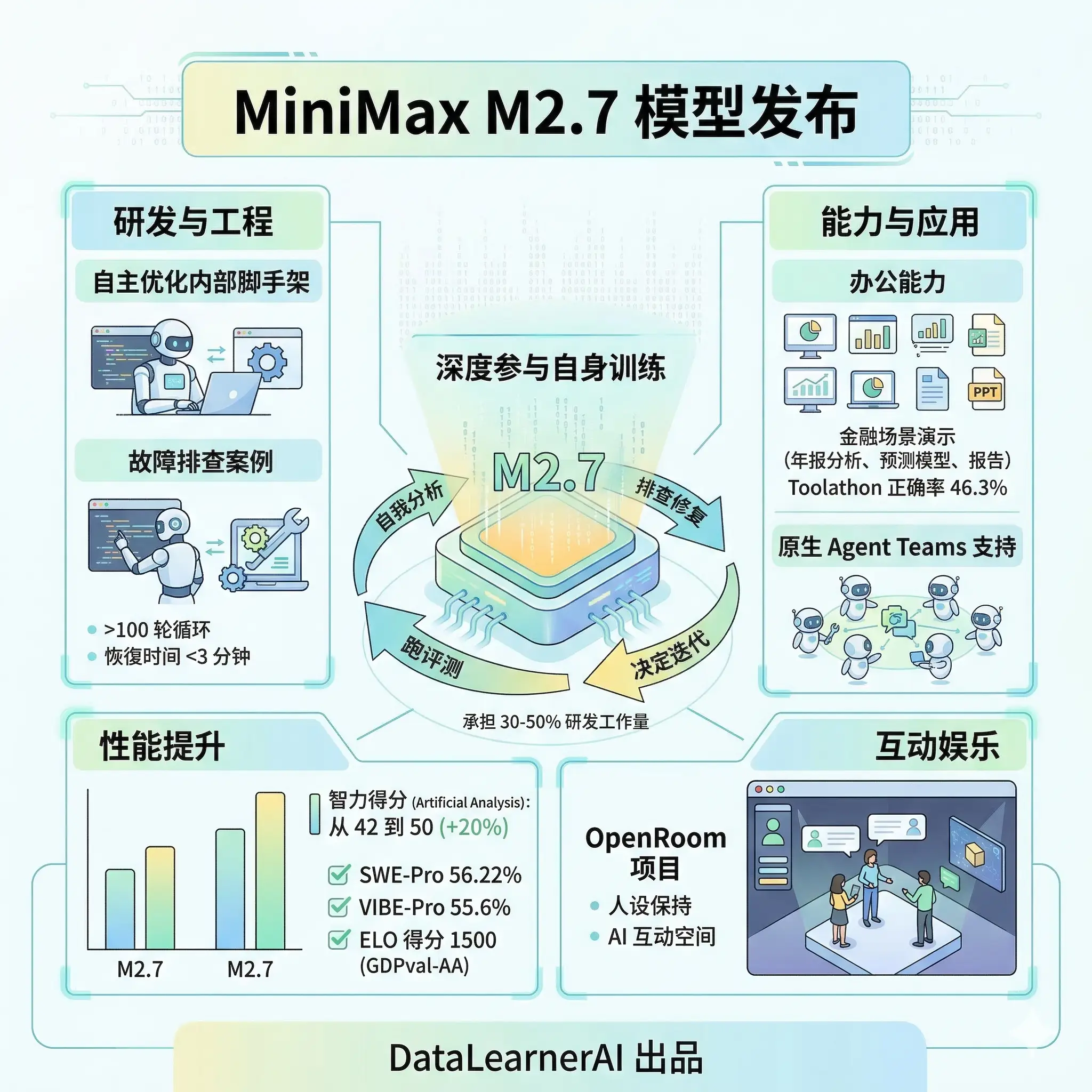
MiniMaxAI 刚刚发布了全新的 M2.7 模型,官方说本次发布的 M2.7 最大的特点是第一个深度参与迭代自身训练流程的模型,也就是说模型在训练过程中进行了自我分析并参与迭代。目前 M2.7 已经可以在官网使用,接口价格不变。不过该模型当前并未宣布开源,还不确定未来情况。
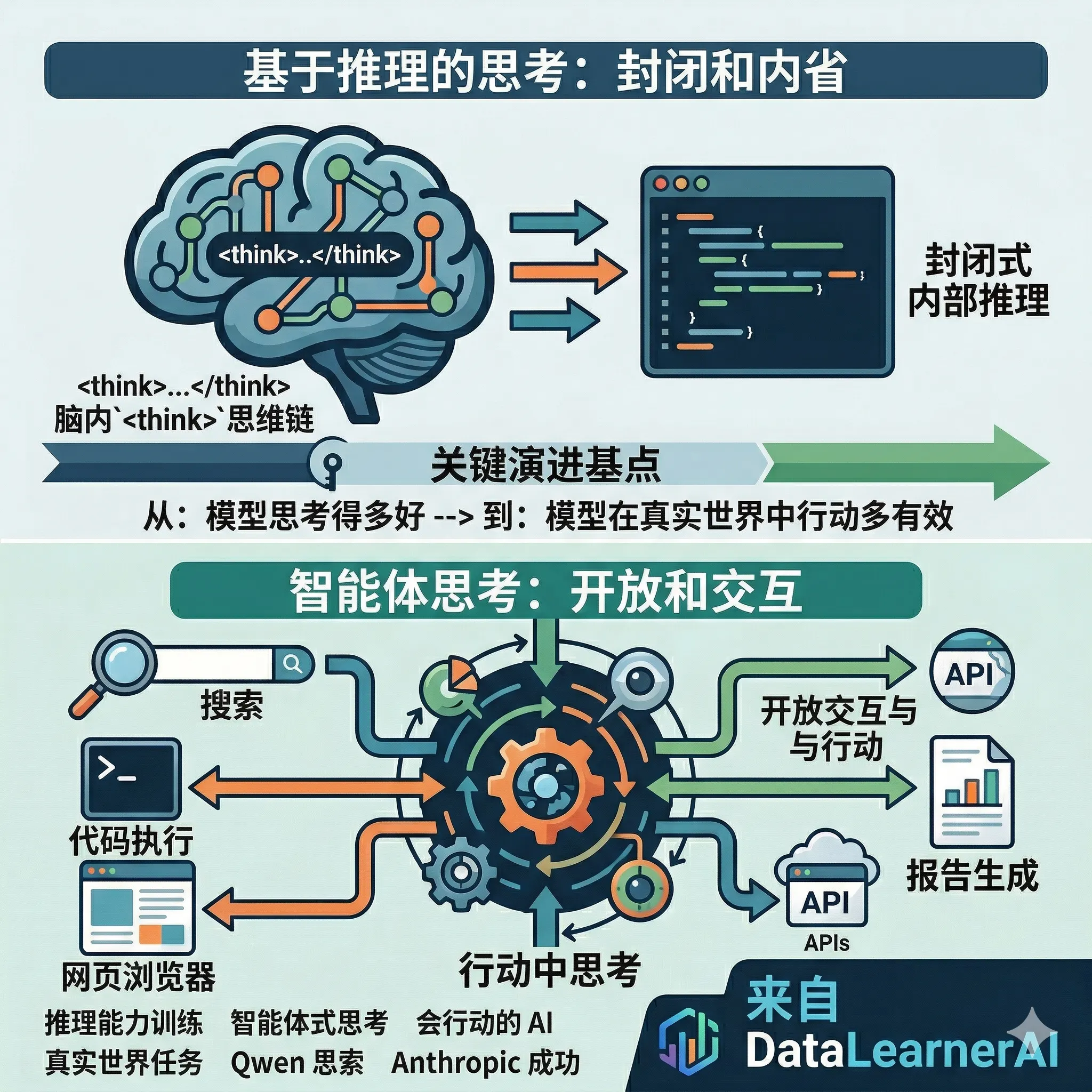
unyang 是前 Qwen(通义千问)负责人,前段时间他的离职造成了许多人的关注。不过他并未沉寂,就在刚才,Junyang 发表了一篇关于如何训练大模型推理能力、以及未来大模型推理能力训练应该走向何方的深度讨论。
2026年4月2日,Google DeepMind 发布了 Gemma 4 系列,共四个版本:E2B、E4B、26B A4B 和 31B Dense。这也是 Gemma 系列首次采用 Apache 2.0 授权,允许完全商用和二次分发。
SWE-bench Multilingual 是 SWE-bench 基准系列的扩展版本。该基准用于评估大语言模型在软件工程任务上的表现,覆盖多种编程语言。数据集包含 300 个从真实 GitHub 问题与对应拉取请求中提取的任务,涉及 42 个仓库和 9 种编程语言。模型接收问题描述与仓库快照后,需生成代码补丁,并通过失败到通过(F2P)和通过到通过(P2P)测试套件进行验证。