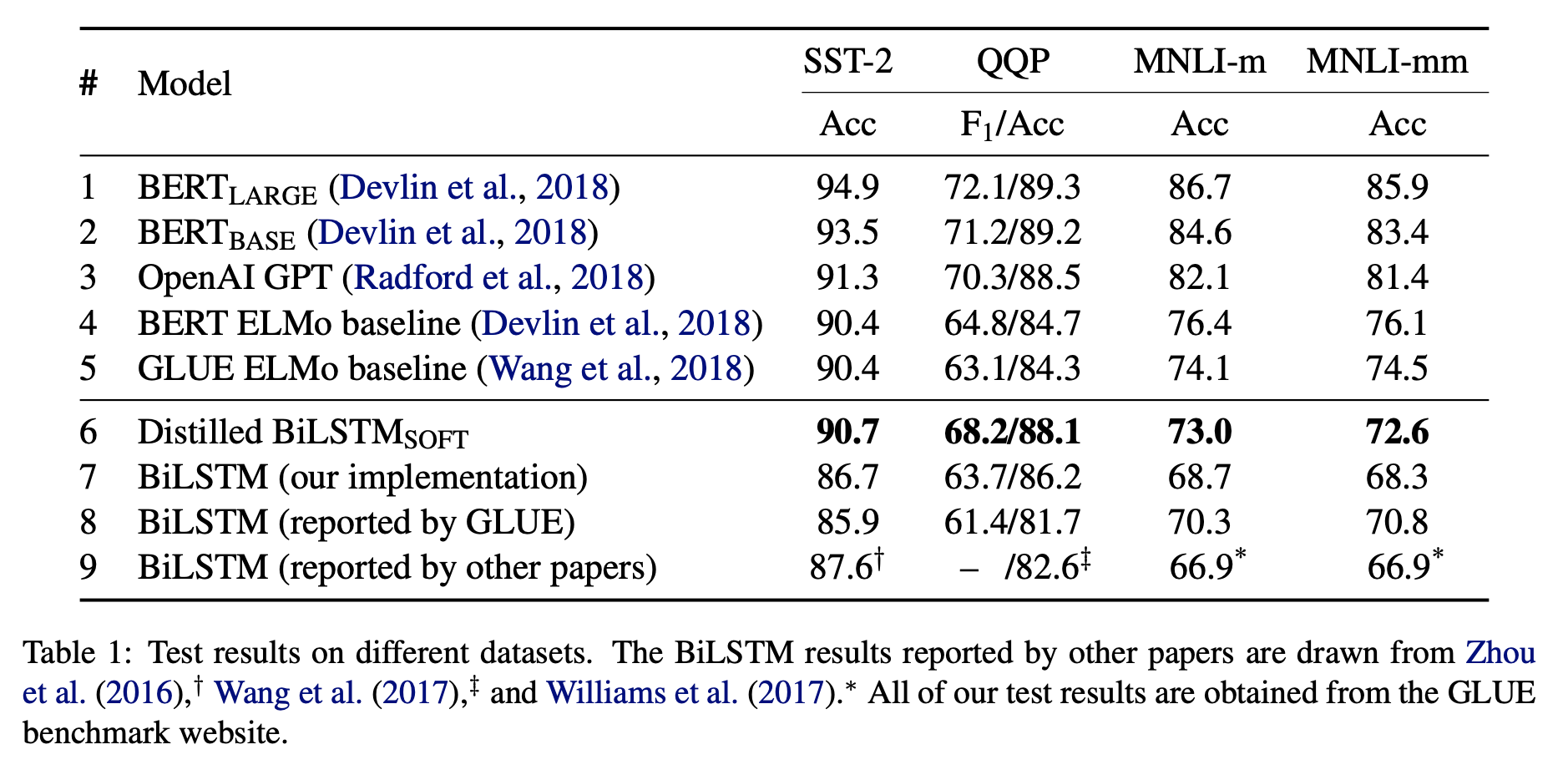
提炼BERT——将BERT转成小模型(Distilling BERT — How to achieve BERT performance using Logistic Regression)
BERT是很好的模型,但是它的参数太大,网络结构太复杂。在很多没有GPU的环境下都无法部署。本文讲的是如何利用BERT构造更好的小的逻辑回归模型来代替原始BERT模型,可以放入生产环境中,以节约资源。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
BERT是很好的模型,但是它的参数太大,网络结构太复杂。在很多没有GPU的环境下都无法部署。本文讲的是如何利用BERT构造更好的小的逻辑回归模型来代替原始BERT模型,可以放入生产环境中,以节约资源。
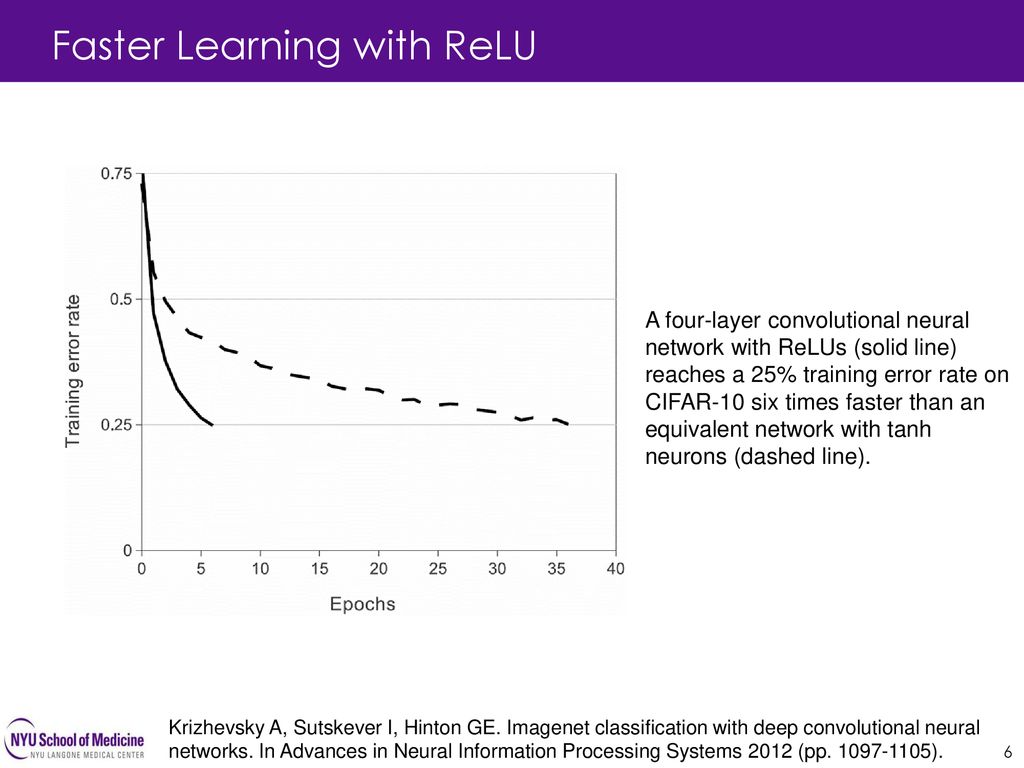
2012年发表的AlexNet可以算是开启本轮深度学习浪潮的开山之作了。由于AlexNet在ImageNet LSVRC-2012(Large Scale Visual Recognition Competition)赢得第一名,并且错误率只有15.3%(第二名是26.2%),引起了巨大的反响。相比较之前的深度学习网络结构,AlexNet主要的变化在于激活函数采用了Relu、使用Dropout代替正则降低过拟合等。本篇博客将根据其论文,详细讲述AlexNet的网络结构及其特点。

反向传播算法是深度学习求解最重要的方法。这里我们手动推导一下。
深度学习是目前最火的算法领域。他在诸多任务中取得的骄人成绩使得其进化越来越好。本文收集深度学习中的经典算法,以及相关的解释和代码实现。
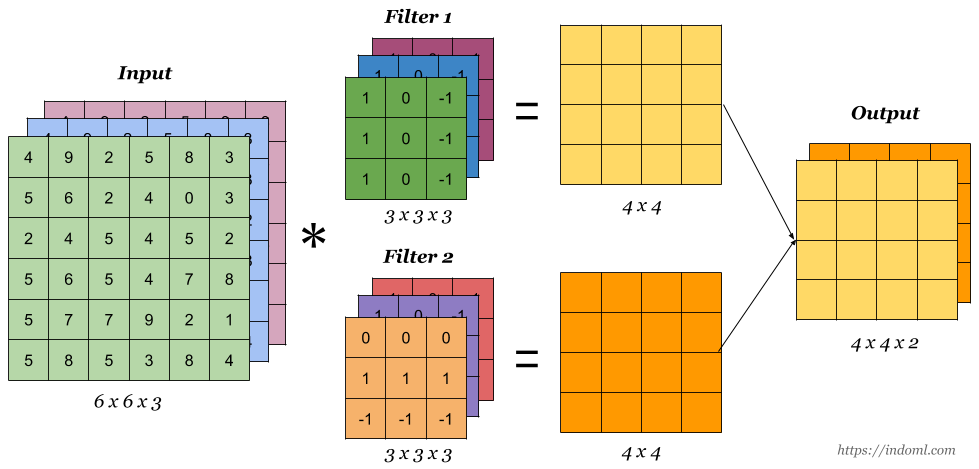
卷积操作的维度计算是定义神经网络结构的重要问题,在使用如PyTorch、Tensorflow等深度学习框架搭建神经网络的时候,对每一层输入的维度和输出的维度都必须计算准确,否则容易出错,这里将详细说明相关的维度计算。
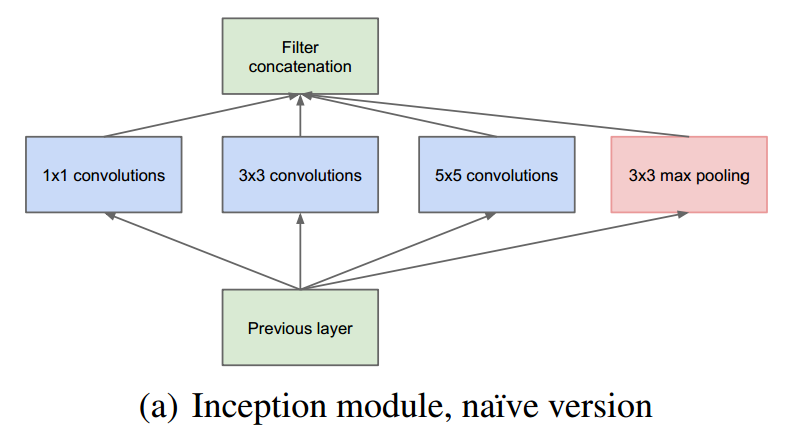
GoogLeNet是谷歌在2014年提出的一种CNN深度学习方法,它赢得了2014年ILSVRC的冠军,其错误率要低于当时的VGGNet。与之前的深度学习网络思路不同,之前的CNN网络的主要目标还是加深网络的深度,而GoogLeNet则提出了一种新的结构,称之为inception。GoogLeNet利用inception结构组成了一个22层的巨大的网络,但是其参数却比之前的如AlexNet网络低很多。是一种非常优秀的CNN结构。
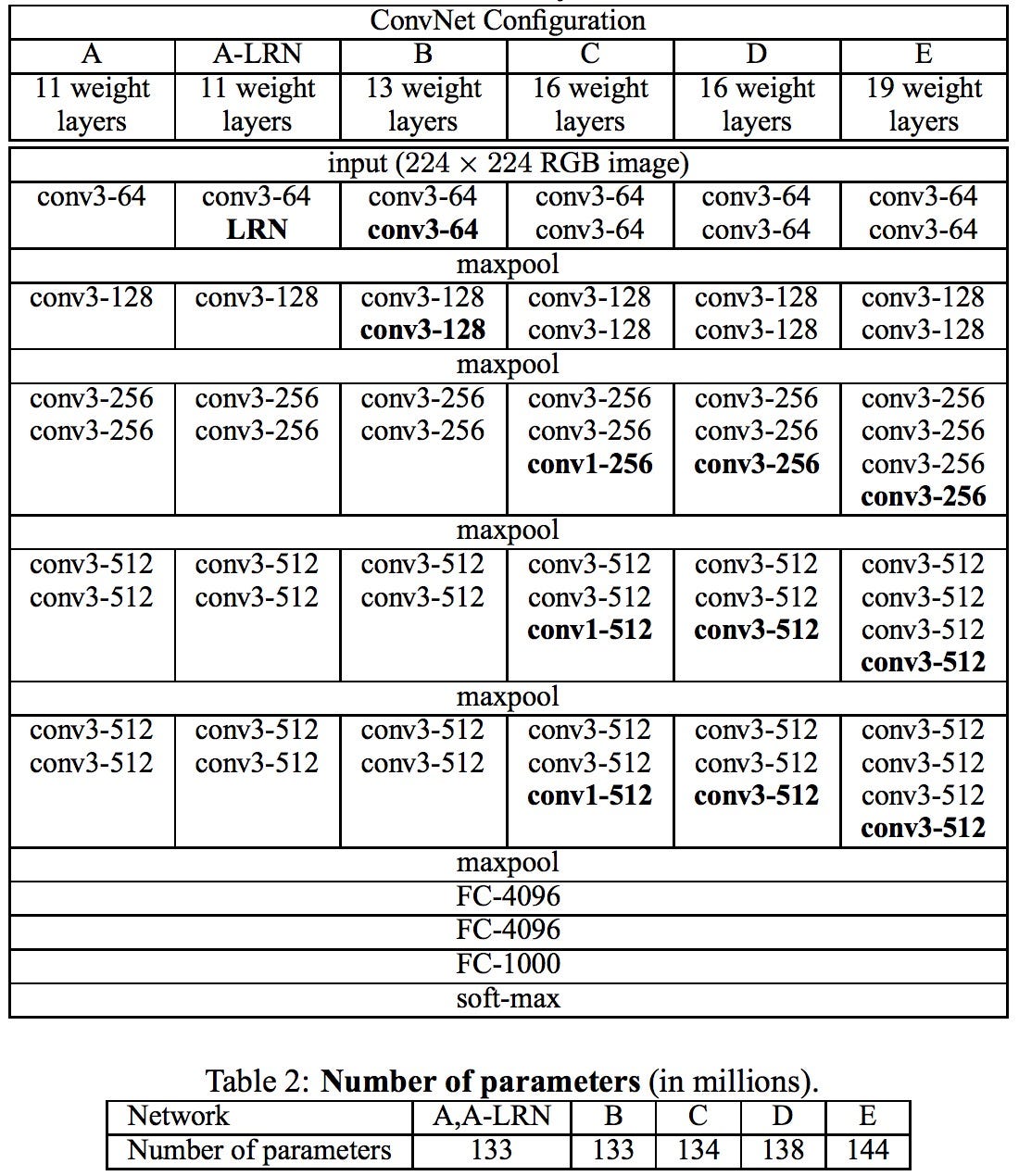
VGGNet(Visual Geometry Group)是2014年又一个经典的卷积神经网络。VGGNet最主要的目标是试图回答“如何设计网络结构”的问题。随着AlexNet提出,很多人开始利用卷积神经网络来解决图像识别的问题。一般的做法都是重复几层卷积网络,每个卷积网络之后接一些池化层,最后再加上几个全连接层。而VGGNet的提出,给这些结构设计带来了一些标准参考。
1998年,LeCun提出了LeNet-5网络用来解决手写识别的问题。LeNet-5被誉为是卷积神经网络的“Hello Word”,足以见到这篇论文的重要性。在此之前,LeCun最早在1989年提出了LeNet-1,并在接下来的几年中继续探索,陆续提出了LeNet-4、Boosted LeNet-4等。本篇博客将详解LeCun的这篇论文,并不是完全翻译,而是总结每一部分的精华内容。
之前面的博客中,我们已经描述了基本的RNN模型。但是基本的RNN模型有一些缺点难以克服。其中梯度消失问题(Vanishing Gradients)最难以解决。为了解决这个问题,GRU(Gated Recurrent Unit)神经网络应运而生。本篇博客将描述GRU神经网络的工作原理。GRU主要思想来自下面两篇论文:
在前面的博客中,我们已经介绍了基本的RNN模型和GRU深度学习网络,在这篇博客中,我们将介绍LSTM模型,LSTM全称是Long Short-Time Memory,也是RNN模型的一种。

使用预训练模型处理NLP任务是目前深度学习中一个非常火热的领域。本文总结了8个顶级的预训练模型,并提供了每个模型相关的资源(包括官方文档、Github代码和别人已经基于这些模型预训练好的模型等)。
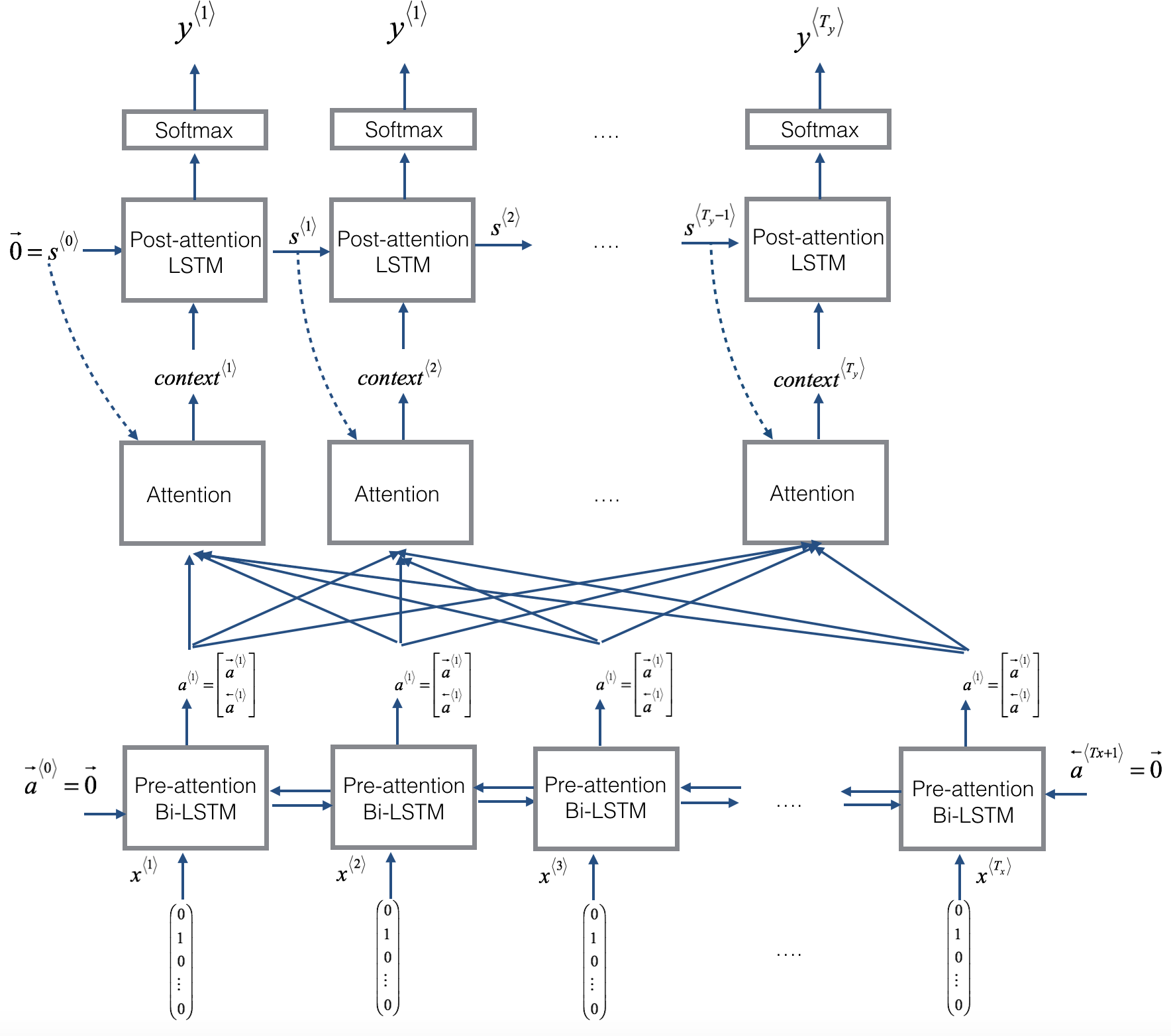
Encoder-Decoder的深度学习架构是目前非常流行的神经网络架构,在许多的任务上都取得了很好的成绩。在之前的博客中,我们也详细介绍了该架构(参见深度学习之Encoder-Decoder架构)。本篇博客将详细讲述Attention机制。

深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。
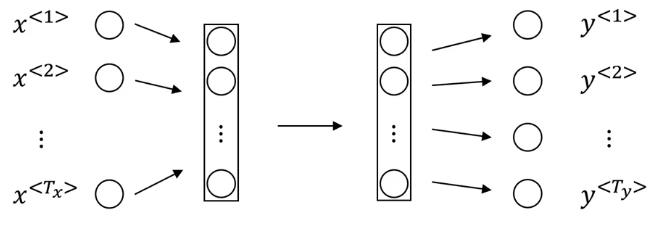
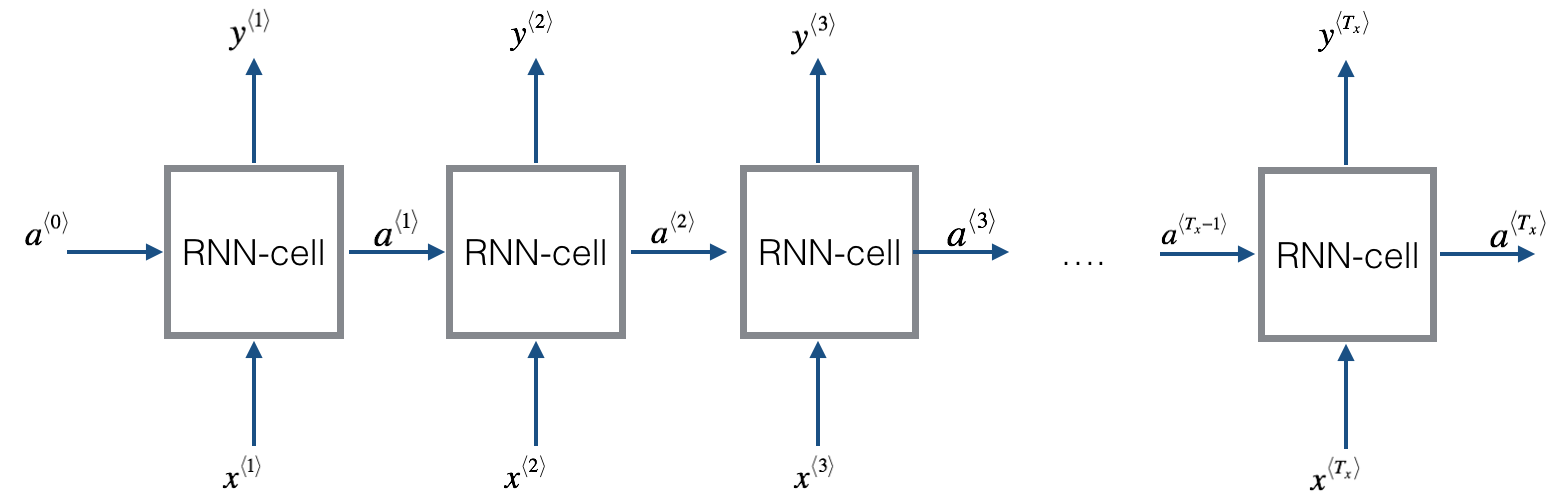
序列数据是生活中很常见的一种数据,如一句话、一段时间某个广告位的流量、一连串运动视频的截图等。在这些数据中也有着很多数据挖掘的需求。RNN就是解决这类问题的一种深度学习方法。其全称是Recurrent Neural Networks,中文是递归神经网络。主要解决序列数据的数据挖掘问题。
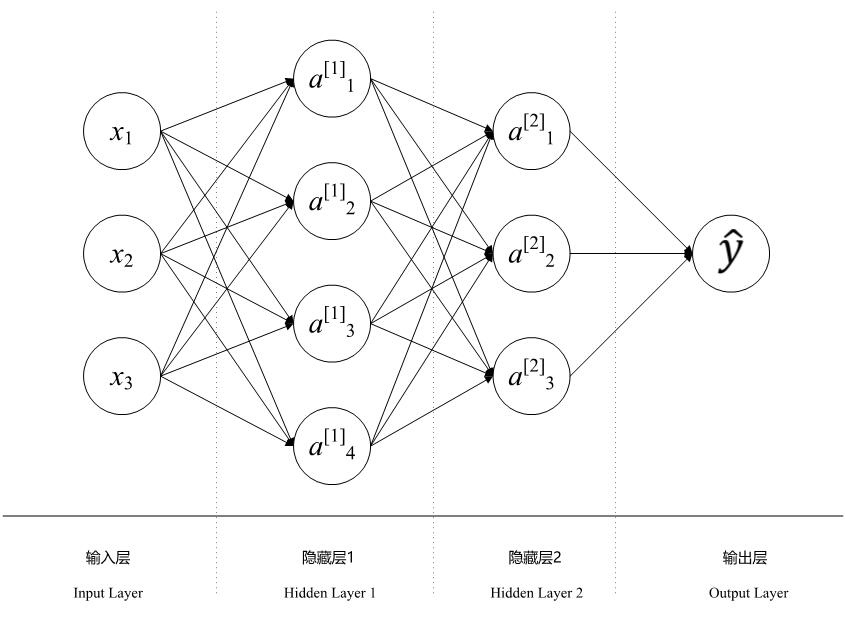
深度学习中的符号很多,但是大多数情况下,大家都使用同一套符号来表示。这篇博客主要以一个简单的神经网络为例,说明深度学习的标准符号以及相关的维度表示。主要来源是吴恩达的coursera课程。

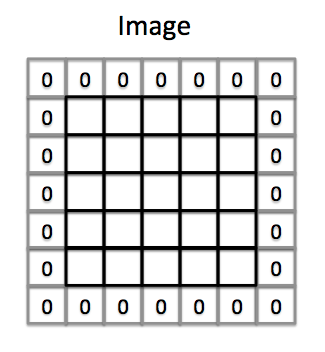
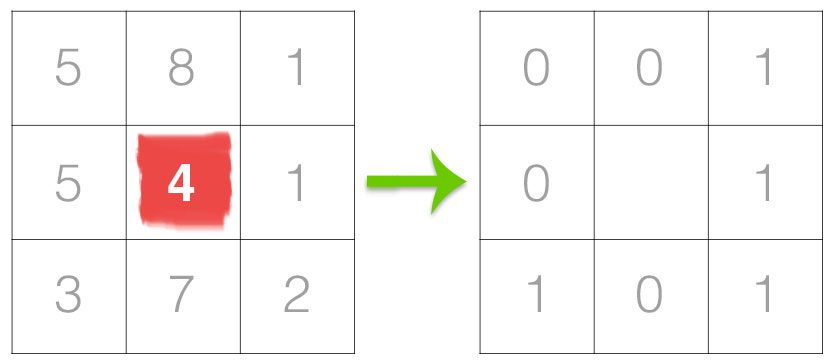
卷积神经网络是深度学习中处理图像的利器。在卷积神经网络中,Padding是一种非常常见的操作。本片博客将简要介绍Padding的原理。

当我们训练深度学习神经网络的时候通常希望能获得最好的泛化性能(generalization performance,即可以很好地拟合数据)。但是所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合:当网络在训练集上表现越来越好,错误率越来越低的时候,实际上在某一刻,它在测试集的表现已经开始变差。早停法就是一种防止深度学习网络模型过拟合的方法。
本笔记是来自Neural Networks and Deep Learning课程第二周作业
看过很多书,都说了神经网络的进展,但总有一些小问题没有明白。这次基本上都明白了,记录一下。
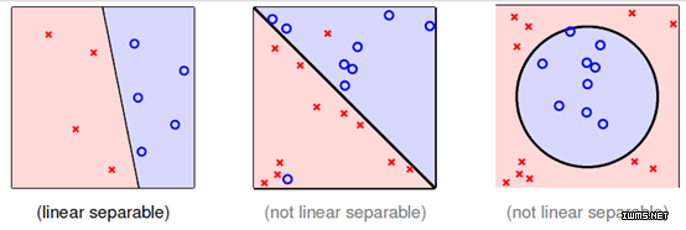
在机器学习或者深度学习中,正则项是我们经常遇到的概念。它对提高模型的准确性和泛化能力非常重要。本文详细描述了正则项的来源以及与其他概念的相关关系。
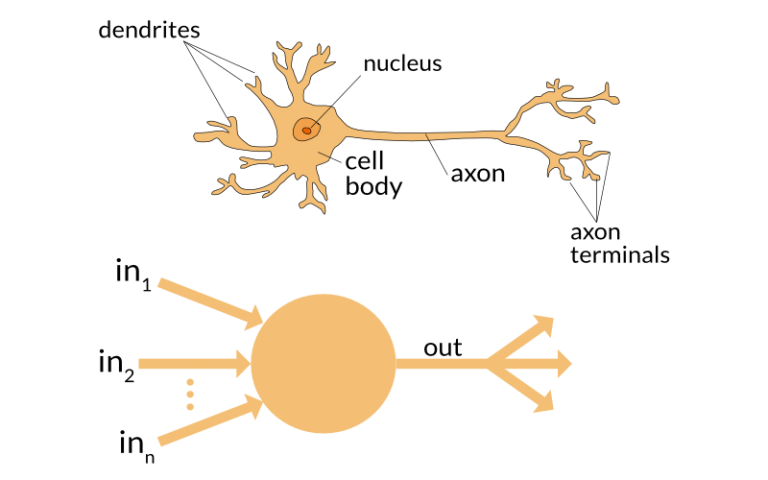
这篇博客是来自Analytics Vidhya的一篇文章。写的很不错。
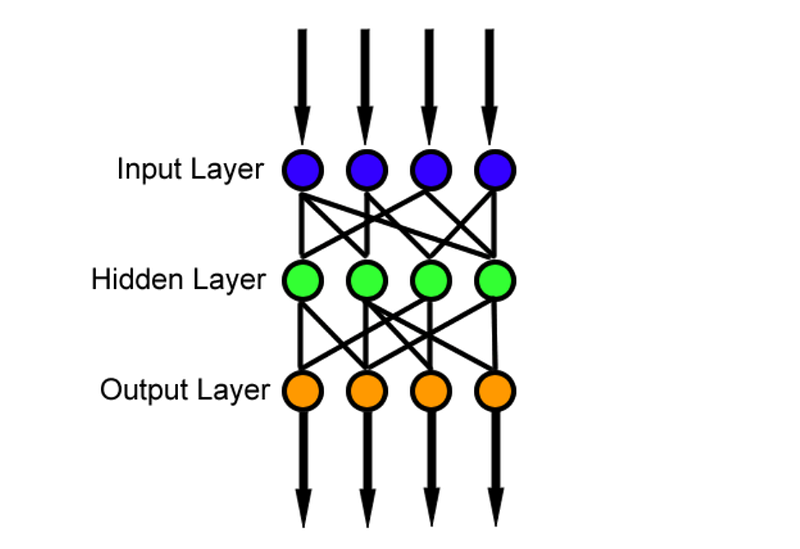
深度学习是计算机领域中目前非常火的话题,不仅在学术界有很多论文,在业界也有很多实际运用。本篇博客主要介绍了三种基本的深度学习的架构,并对深度学习的原理作了简单的描述。本篇文章翻译自Medium上一篇入门介绍。