如何提高大模型在超长上下文的表现?Claude实验表明加一句prompt立即提升效果~
1,676 views
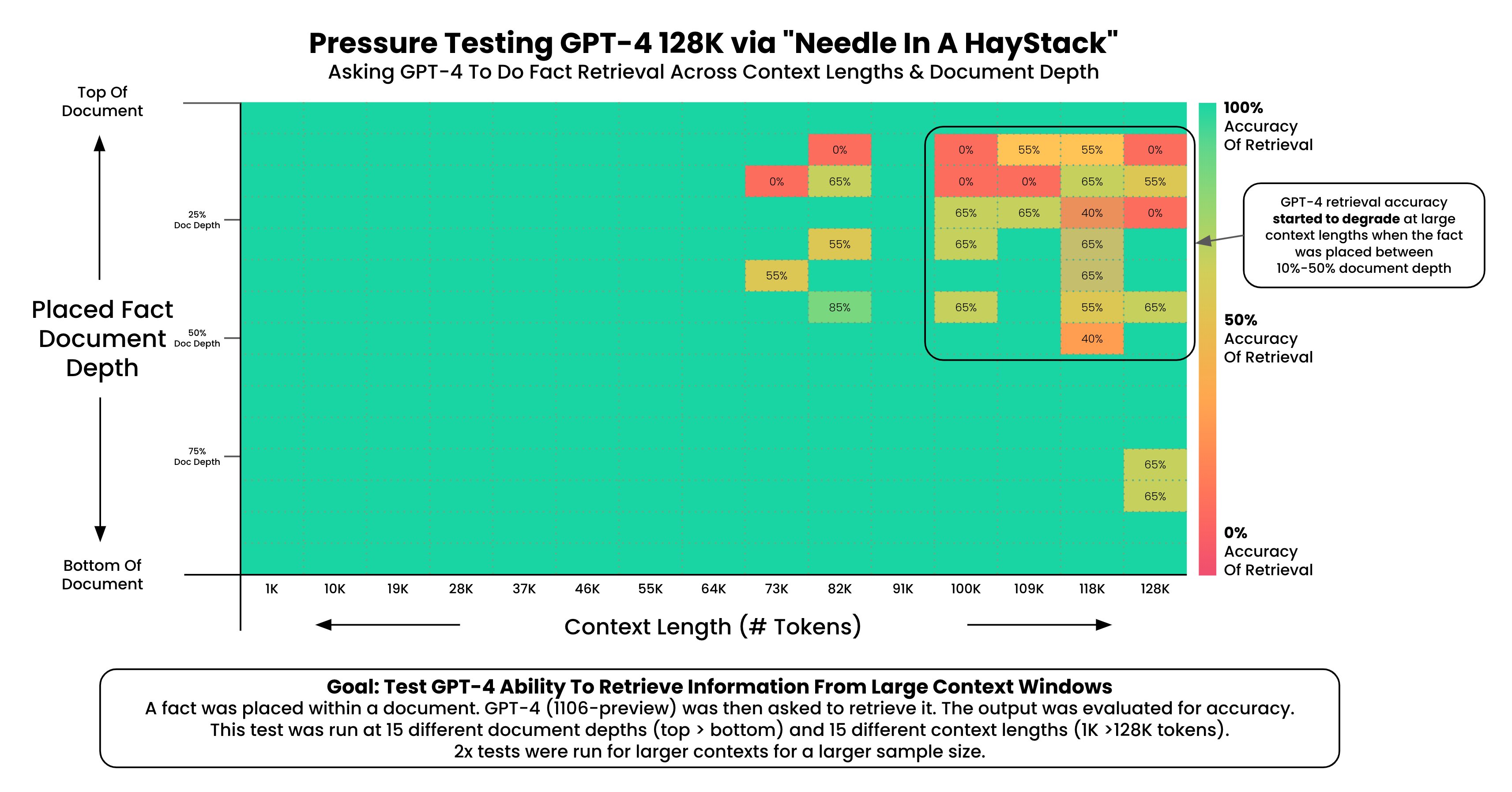
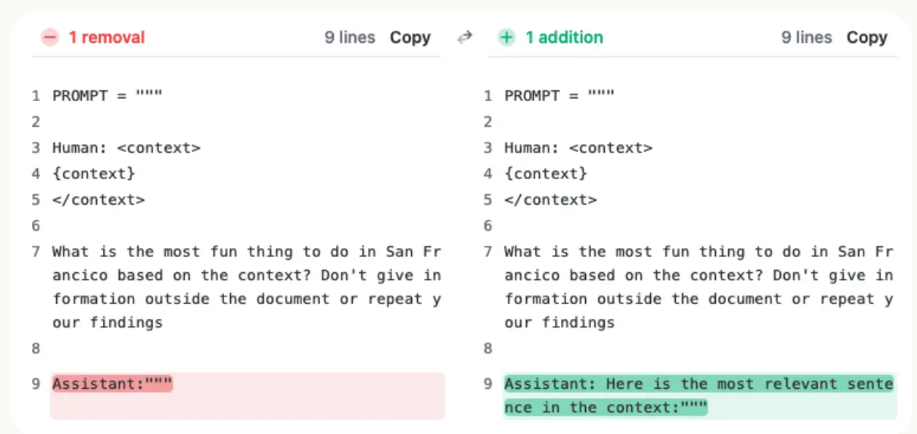
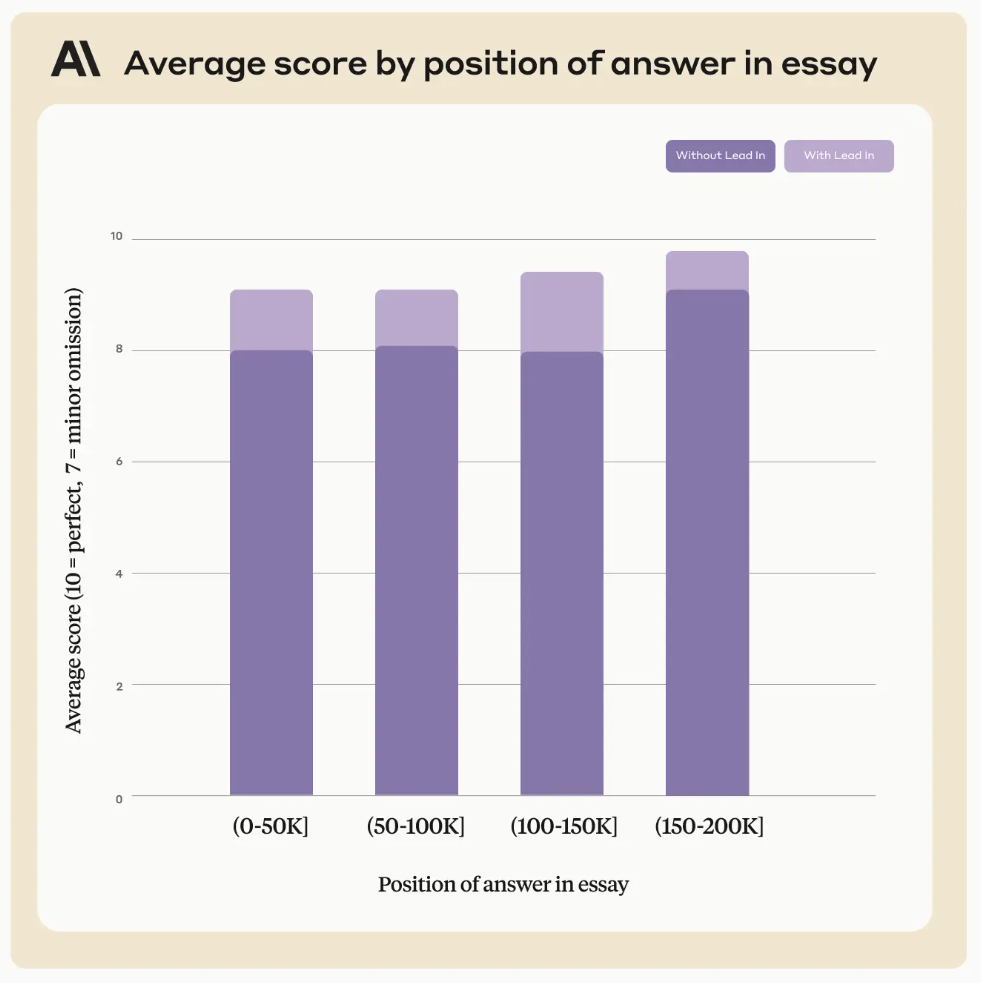
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现Claude 2.1模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。