
全球最大的39亿参数的text-to-image预训练模型发布
CVPR2022的一篇论文带来了一个39亿参数的自回归图像模型公开了他们的代码和论文。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
CVPR2022的一篇论文带来了一个39亿参数的自回归图像模型公开了他们的代码和论文。

不久前,Java18发布,至此这款编程语言已经走过三十多年。随着近几年深度学习的发展,python已经开始霸榜编程语言,Java的流行度似乎下降很多。那么,如今的Java到底是什么状态,未来它的方向在哪?近期,JRebel对中大型企业技术人员的访谈,给我们一些指引和回答。
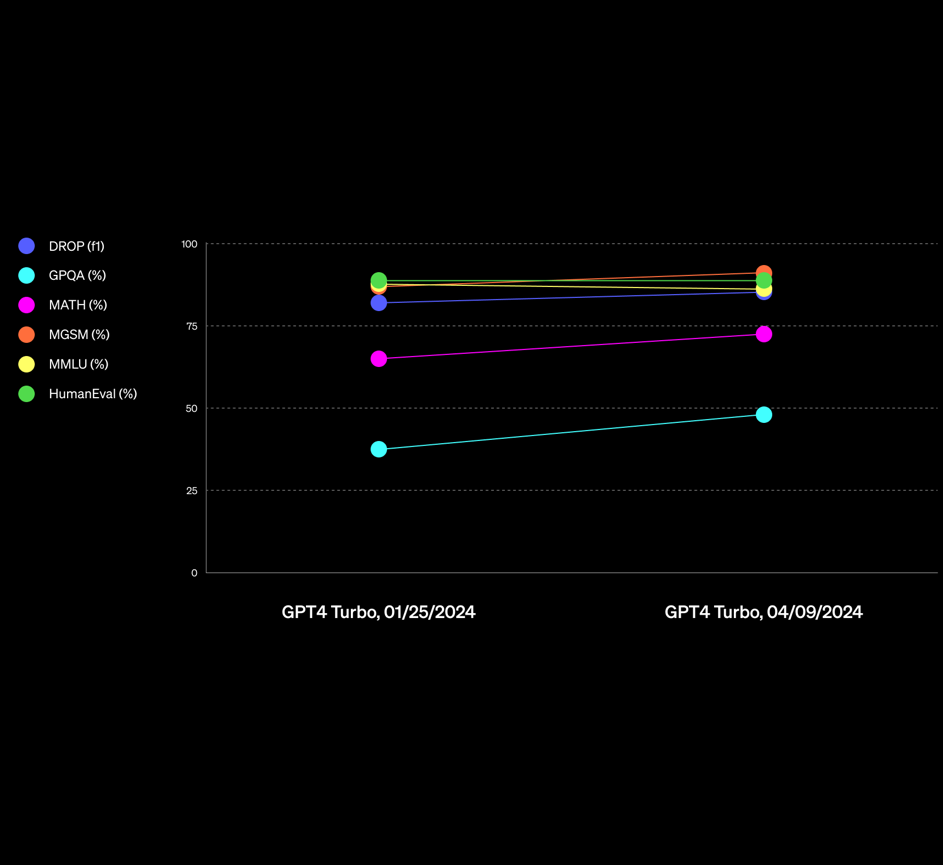
OpenAI的GPT-4一直是全球最强的大语言模型。但是在最近的一系列新模型对比中,已经有一些模型在某些领域被认为已经接近或者超过GPT-4了。而在前几天,OpenAI更新了一个新版本的GPT-4,是GPT-4-Turbo-2024-04-09,官方说该版本的GPT在推理和数学能力上有明显提升,而实测结果也很不错。在基准测试评测中,最高有19%的提升幅度!在GPT-4这样强的模型上有这样的提升幅度,十分不错!

Stepfun AI(阶跃星辰)正式发布了其最新开源基础模型Step-3.5-Flash。这款模型以“快速、锐利、可靠的agentic智能”为核心设计,采用稀疏混合专家(Sparse MoE)架构,总参数量196B,但每token仅激活11B参数,实现高效推理的同时保持前沿级性能。它支持256K超长上下文、多token并行预测(MTP-3),推理速度可达100-300 token/s,甚至在编码任务中峰值350 token/s。

阿里宣布开源第三代编程大模型Qwen3-Coder-480B-A35B,该模型是Qwen3编程大模型中第一个开源的版本,同时官方还基于Google的Gemini CLI改造并开源了阿里自己的命令行编程工具Qwen Code,完全免费使用。
DeepSeekAI最近发布的几个模型,如DeepSeek V3、DeepSeek R1等引起了全球的广泛关注和讨论,特别是低成本训练出高质量模型之后,引起了很多的争论。引起了大家对OpenAI、英伟达等公司未来的质疑。然而,对于DeepSeekAI的模型为什么引起了如此广泛的关注,以及大家讨论的核心内容是什么,很多人并不是很清楚。本文基于著名的独立科技行业分析师Ben Thompson的总结,配合DataLearnerAI的分析,为大家总结DeepSeek引起的全球讨论。
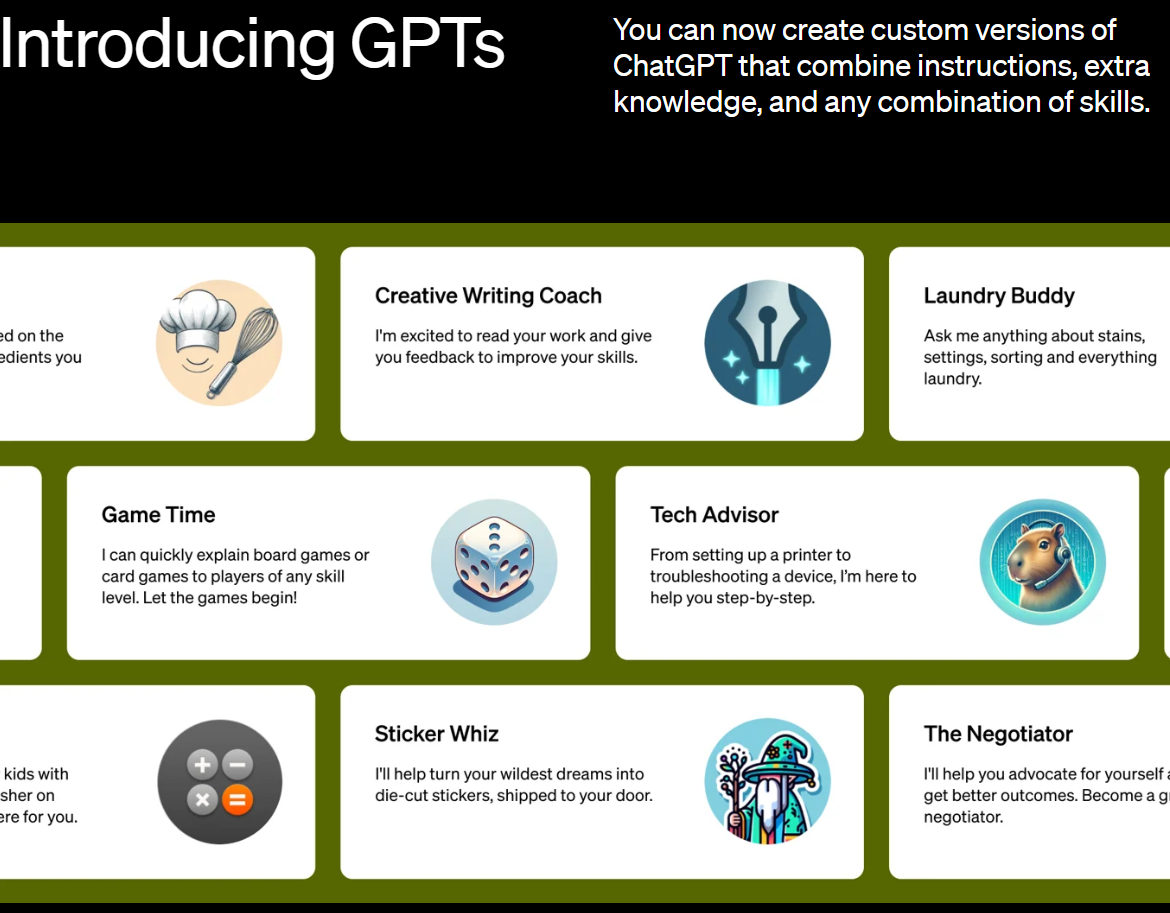
GPTs是OpenAI在其开发者日发布的一项最新的个性化GPT功能。所有人可以基于现有的GPT-4,配合网络流量、文件访问等功能,上传自己的数据,对接自己的接口来构建个性化的GPT,并对外提供服务。那么,2周后的今天GPTs的发展怎么样?有哪些受欢迎的GPTs被大量使用?本文结合各方数据介绍一下当前GPTs的情况。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。

如今,不支持https的网站基本都无法访问,https网站需要在服务端保存ssl证书才可以建立。这个原理本文不多说。目前,各大云服务厂商也提供ssl证书的发放和管理,但都是收费的。对于个人网站来说,基于第三方的服务申请免费证书其实是合适的。但是,国内申请证书并不好用。本文主要记录一个最简单的免费证书申请安装方法。

《Python Notes For Professionals》是StackOverflow上的人总结的Python使用方法。

“Vibe Coding”(氛围编程)是一种新兴的编程范式,强调通过自然语言与人工智能(AI)协作开发软件。该概念由前 OpenAI 研究员 Andrej Karpathy 于 2025 年提出,旨在让开发者沉浸于创作氛围中,利用 AI 的能力,将自然语言描述转化为实际源代码,从而简化编程过程。
影响者营销将是极好的机会,可以使你的形象更加完善,并接触到新的受众,是一个人性化的宏伟机会?的确如此。它是否充满了影响者和品牌宁愿不管理的问题?同样地,是的。
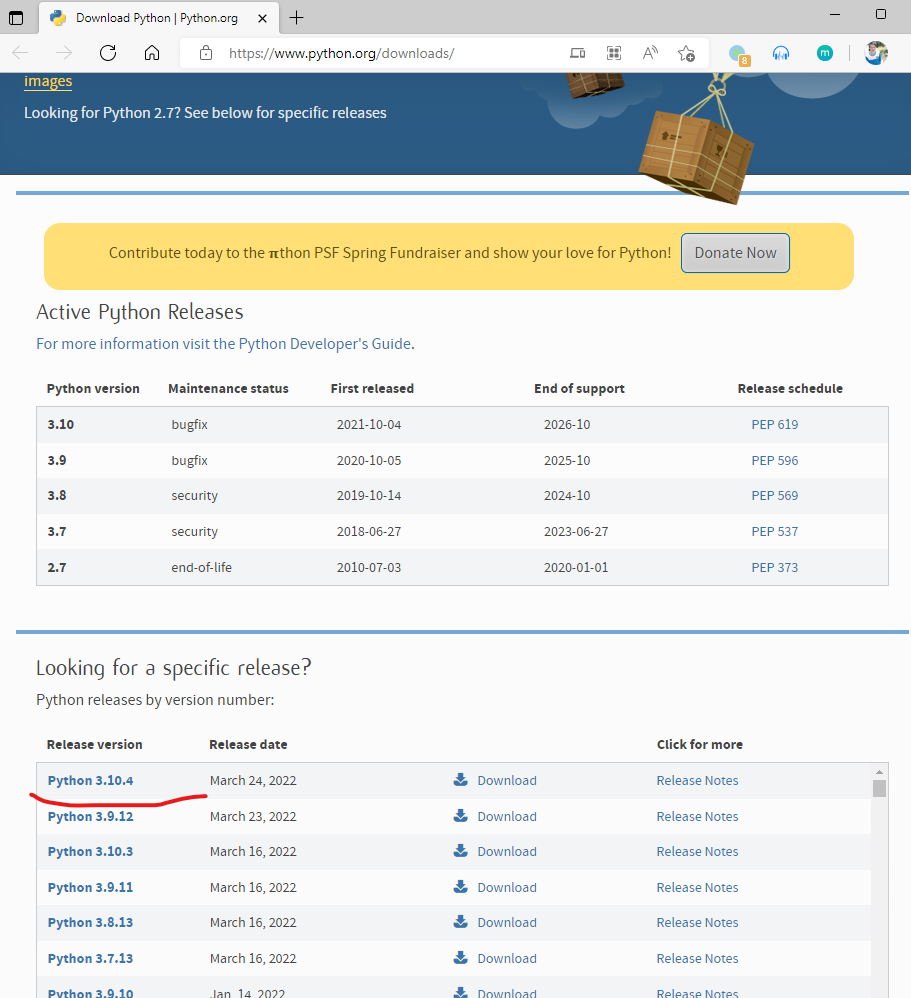
Python作为目前最流行的编程语言,因为其易用性以及丰富的库成为很多人的工具。它不仅是程序员的编程语言,也是各行各业提升工作效率的工具。本篇博客作为一篇针对完全小白的python语言搭建环境,不会为python语言本身做介绍,完全只考虑搭建python编程环境,目的是让你动手在电脑上写下第一行python程序,并成功运行,为广大童鞋提供一个入门参考。

OSWorld(Open Source World)是首个真正基于真实操作系统环境的多模态Agent评测平台。它不同于传统的模拟环境(如MiniWoB或WebArena),而是直接在完整的Ubuntu、Windows和macOS系统中运行,让AI代理通过截图观察、鼠标键盘操作来完成任务。

最近,一些未公开但即将发布的内容被曝出,显示出Anthropic正在为其AI模型(Claude)推出一项名为Thinking的新功能。这一功能将极大提升AI在推理和决策时的透明度,允许用户查看AI的思考过程,并提供更长时间的推理分析,帮助用户更好地理解和验证AI的决策逻辑。

今天,Claude Code 的创建者 Boris 发了一条很长的 thread,第一次比较完整地讲了他自己是怎么使用 Claude Code 的。共13条总结,我们这里总结一下,供大家参考。

最近,初创企业Pika引起了全球的目光。这家公司发布的Pika 1.0产品可以基于生成式AI技术来创建3D动画视频或者电影级别的视频。由于其逼真的效果,引起了很多人的关注。本文则介绍一个由上海人工智能实验室开源的文本生成视频大模型LaVie。这个模型可以根据文本生成高质量的视频内容。
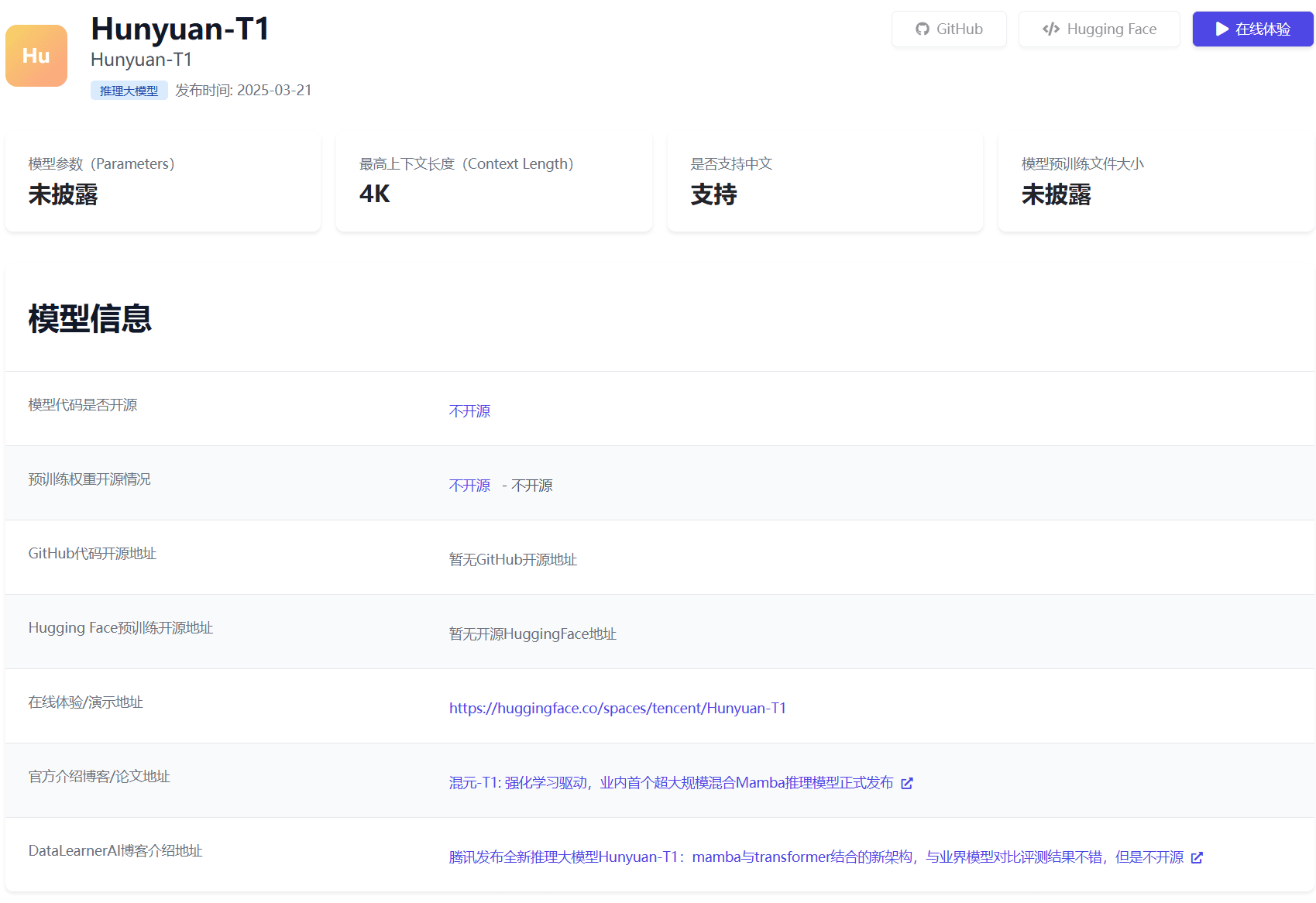
2025年3月21日,腾讯正式推出其全新大模型**Hunyuan-T1**,该模型基于此前发布的TurboS快速思维基座,首次采用**Hybrid-Transformer-Mamba混合专家架构(MoE)**,在推理效率、长文本处理及资源消耗优化等方面表现还不错。此外,这个新架构也使得Hunyuan-T1速度非常快,模型支持首字符1秒内响应,生成速度达60-80 token/秒,适用于实时交互场景。

ChatGPT是属于生成式AI的一种应用。由于其强大的效果已经变成了当前最主流的一种AI方案。而构建生成式AI应用的一个重要方向是构建友好的web形态的demo让用户能快速体验。Gradio就是这样一种开源方案,也是当前最流行的一种快速构建AI Web应用的方案。昨天吴恩达的DeepLearningAI与HuggingFace共同推出了最新的一期短课程《Building Generative AI Applications with Gradio》,教大家如何使用Gradio快速构建生成式AI的应用。

大模型的进展非常快,但是如何在移动端部署和使用依然是一个非常大的挑战。今天,CerebrasAI联合Opentensor一起开源了一个30亿参数规模的模型BTLM-3B-8K,官方宣称其性能接近70亿参数规模的大模型,但是运行的资源却很低,最低量化版本只需要不到4GB显存即可。

阿里巴巴的 Qwen Code 是一款开源的命令行 AI 工具,旨在提升开发者的编程效率,特别适用于处理大型代码库和复杂的开发任务。 2025年8月9日,阿里宣布提供每天2000次的免费Qwen Code服务,应该是满足大多数开发者的日常需求了。

为了解决大模型的Agent操作依赖交互和人工处理这个问题,普林斯顿大学与 Sierra Research 的研究团队在 2025 年 6 月提出了 τ²-Bench(Tau-Squared Benchmark),并发布了论文《τ²-Bench: Evaluating Conversational Agents in a Dual-Control Environment》。 它是对早期 τ-Bench 的扩展版本,旨在建立一种标准化方法,评估智能体在与用户共同作用于环境时的表现。

Llama系列大语言模型是由MetaAI开源的一系列大语言模型。作为最早开源的大语言模型,Llama系列对大模型开源社区的推动有目共睹。而现在MetaAI开源Llama3.1系列模型,其中包括迄今为止最大规模的开源大语言模型Llama3.1-405B,参数规模达到了4050亿!其多项评测结果超过GPT-4、GPT-4o模型,与Claude3.5-Sonnet几乎有来有回!
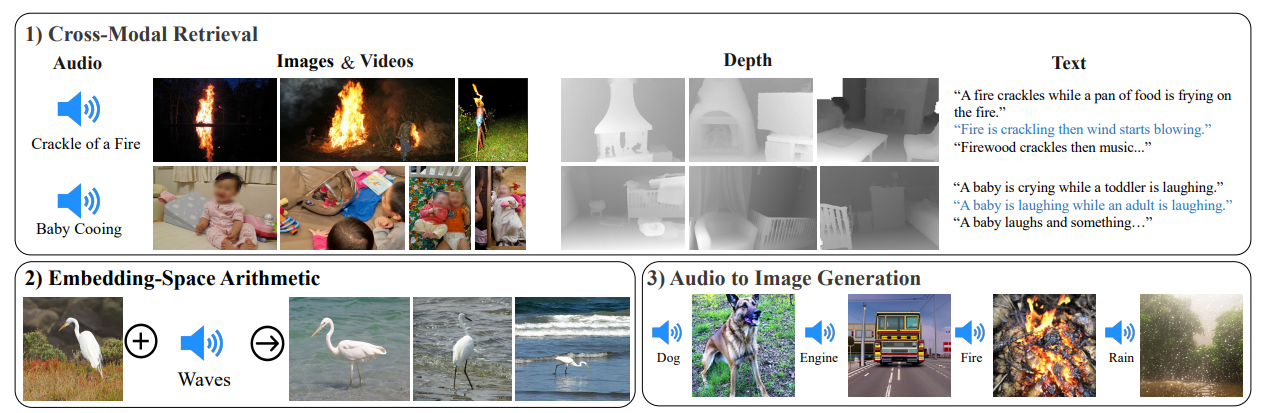
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。