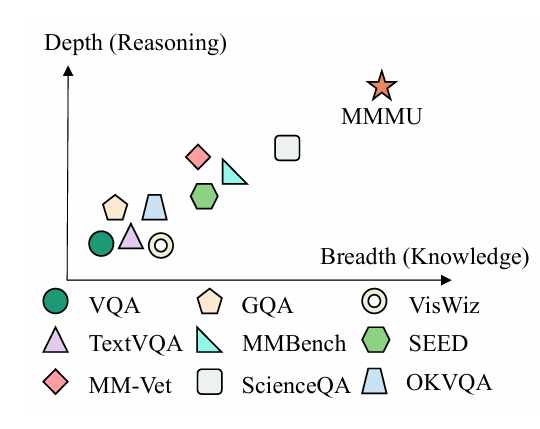
大模型多模态评测基准MMMU介绍
大模型多模态评测基准MMMU(大规模多学科多模态理解和推理基准)是一项旨在评估多模态人工智能模型在复杂跨学科任务中综合能力的测试工具。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
大模型多模态评测基准MMMU(大规模多学科多模态理解和推理基准)是一项旨在评估多模态人工智能模型在复杂跨学科任务中综合能力的测试工具。

OpenAI在2025年9月推出的GDPval基准,将焦点转向“具有经济价值的真实任务”,而第三方独立机构Artificial Analysis在此基础上开发的GDPval-AA,进一步引入了agentic(代理)能力评估和ELO排行榜,成为当前最受关注的“实用性”评测基准之一。

最初,大模型的应用主要通过像ChatGPT这样的聊天机器人展现其智能理解能力。随着技术的进步,基于大模型的智能代理(AI Agent)成为突破大模型能力边界的重要方向。这些智能代理能够执行一系列任务、解决问题,并进行决策,具备深刻理解用户需求和自主规划解决方案的能力,并能够根据规划结果,选择和使用各种工具来完成任务。然而,AI Agent系统面临的关键挑战是如何高效地将外部工具、知识、资源等迅速接入大模型,并实现有效利用。尤其是,如何将现有的工具和资源整合进大模型,提升其生产力能力,是一个亟待解决的问题。

Grok4是马斯克旗下大模型初创企业xAI的第四代代码,在五月份的时候,马斯克就透露他们马上要发布Grok 3.5模型,六月份的时候说这个模型效果很好,版本号就直接改为4,这中间经过多次波折,最终马斯克说Grok 4将在7月4日之后发布。截止目前,虽然xAI官方没有正式宣布Grok 4,但是目前Grok 4已经透露了很多的消息。本文将对这些信息做总结和分析。

谷歌终于在2025年11月18日发布了新一代Gemini 3模型:Gemini 3.0 Pro。该模型目前在各个评测排行榜中都获得了非常优秀的结果,几乎是领先了所有的模型。而根据此前大家的匿名投票评分和早期测试,该模型的文本生成、编程、SVG生成等方面都非常优秀。谷歌官方强调,Gemini 3.0 Pro不仅在推理能力上达到了新的业界巅峰,更在理解深度、细微差别以及“思考”能力上实现了质的飞跃。
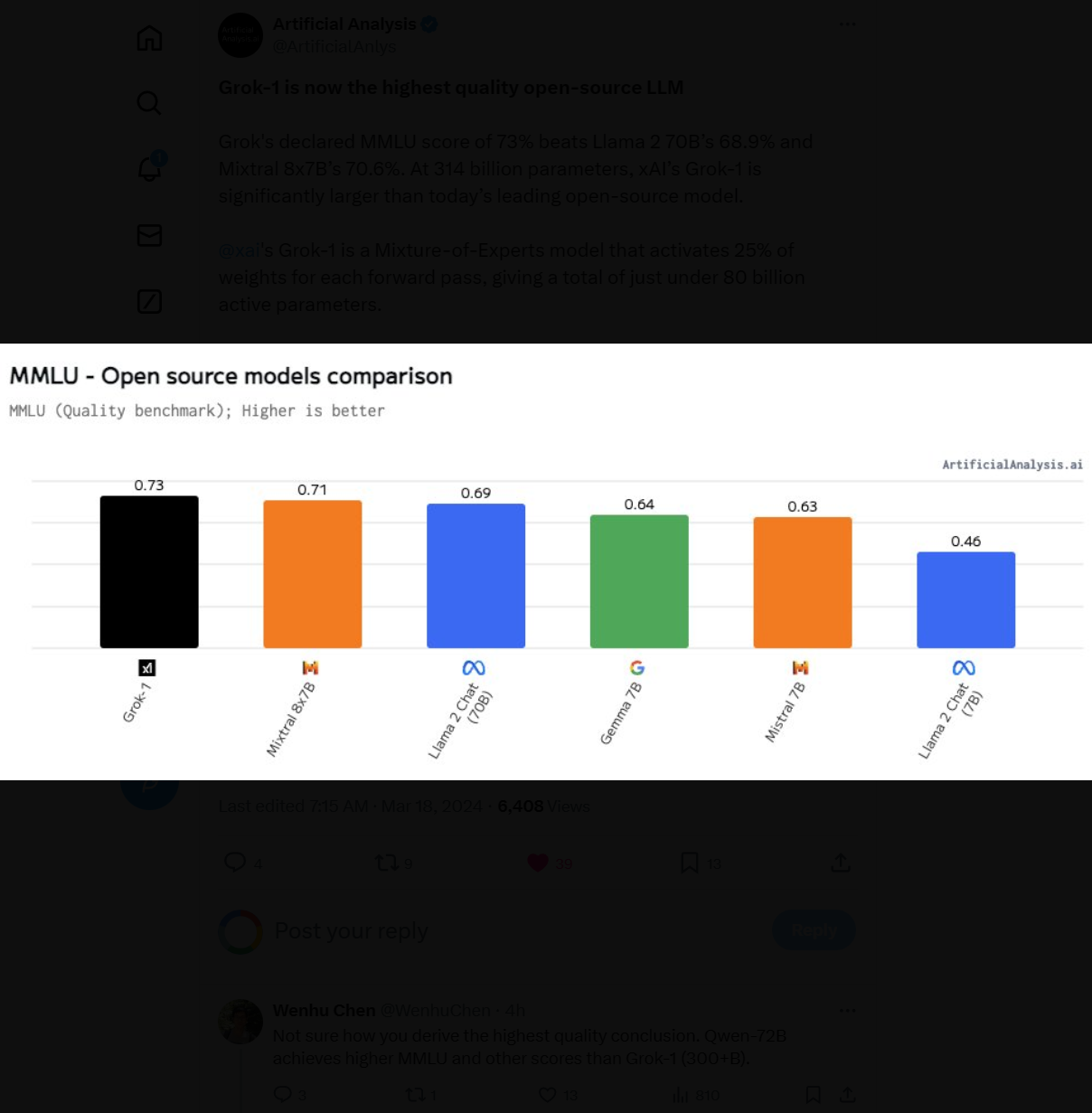
此前,马斯克在推特上宣布要开源旗下大模型公司开发的Grok-1大语言模型。一周后的现在,这个模型Grok-1正式宣布以Apache2.0开源协议开源,本文将针对Grok-1的技术部分进行介绍。

就在刚才,智谱推出了两个语音识别模型:闭源的 GLM-ASR 和开源的 GLM-ASR-Nano-2512。与过去他们更多关注通用大模型或多模态模型不同,这次聚焦的是语音转文字(ASR)任务,尤其面向中文语境、方言与复杂环境。以下是对这两款模型已知公开资料的整理与分析。

马斯克旗下的xAI公司正式发布Grok4大模型,包含Grok 4和Grok4 Heavy版本,其中Grok4 Heavy是一个Agent系统,在AIME2025(美国的数学邀请赛)得分满分,超过了所有大模型。此前透露的Grok 4 Code和视频生成能力都没有发布。

GPTs是OpenAI推出的用户自定义的GPT功能,这里的GPTs可以认为是specific GPT。用户创建GPTs主要是通过OpenAI提供的GPT Builder完成。GPT Builder提供的最基本的能力就是基于对话的方式来帮助用户创建GPTs。那么,这个对话式的GPT背后的指令是什么?官方设置了什么样的Prompt来让GPT帮助普通用户建立GPTs呢?本文基于官方最新的博客介绍一下。
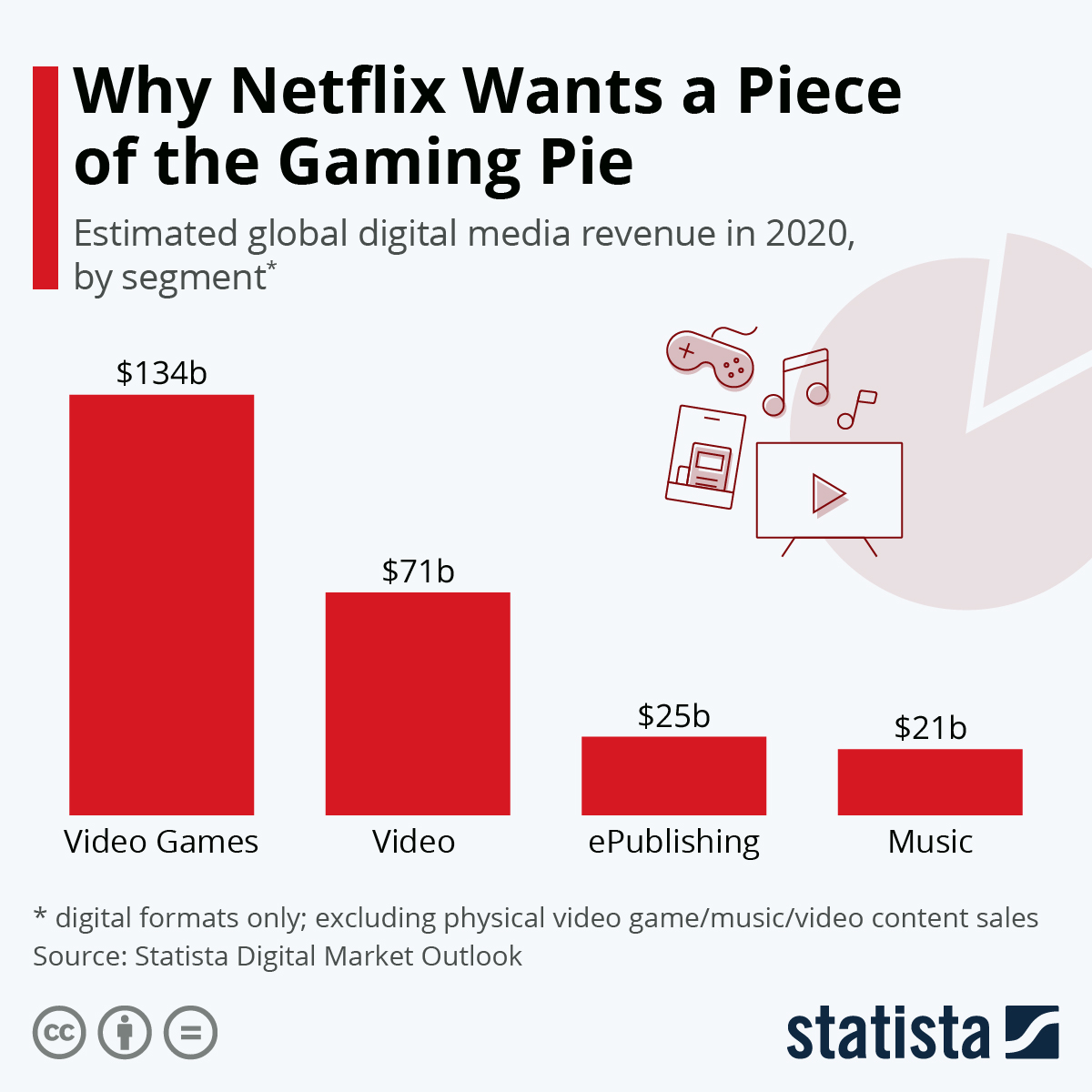
Netflix是一家网络视频服务公司,国内的爱奇艺、腾讯视频都与此类似。前几年大火的《纸牌屋》也就是这家公司提供的。当时最热吵的就是说Netflix凭借大数据选择的剧本形式与演员,让搞数据科学的人风光了好一阵。最近很火的《鱿鱼游戏》也是在Netflix全球独家播出。那么,网络视频搞得这么火热的Netflix为啥要开始搞游戏呢?这里有几个统计数据图可以解释Netflix这样做的原因。
Hunyuan大模型是腾讯训练的大模型品牌名,2022年4月份,某中文语言理解能力排行榜第一名就出现了Hunyuan模型,在2022年11月,Hunyuan大模型就有了1万亿参数的规模,即HunYuan-NLP 1T大模型(比ChatGPT还早发布)。但是最近2年,这个系列的模型几乎没有出现在公众视野上。而昨天(2025年3月10日),Hunyuan官方在X平台上宣布了旗下最新的Hunyuan Turbo S大模型,称其在多个评测基准上超越了GPT-4o的表现。

Anthropic 于 2026 年 1 月 12 日发布了 Cowork,这是一款基于 Claude 模型的新型 AI Agent工具,作为 Claude 桌面应用的 macOS 版本研究预览版推出。目前仅限 Claude Max 订阅者使用,未来计划扩展到 Windows 和跨设备同步。Cowork 继承了 Claude Code 的核心代理能力,但更注重非开发者用户的日常生产力任务,例如访问用户指定的文件夹,读取、编辑或创建文件,帮助整理杂乱下载、从截图生成电子表格,或从笔记起草报告。

就在刚才,阿里开源了Qwen Image大模型,这是阿里千问团队开源的高质量图片生成和编辑的大模型。这份发布迅速在AI社区引起了广泛关注,其核心并非又一个单纯追求图像美学或真实感的模型,而是直指一个长期存在的行业痛点:在图像中进行复杂、精准、尤其是高保真的多语言文本渲染。

国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。

Andrej Karpathy预测2026年AI将主导软件编码工作流,带来巨大效率提升,但可能引发低质代码泛滥(slopacolypse)。Anthropic的Boris Cherny以Claude Code团队实践回应,展示近100% AI生成代码、通用工程师招聘策略,以及通过模型迭代有效控制质量问题。

2025年2月25日,Anthropic发布了Claude 3.7 Sonnet大模型,该模型是业界第一个同时支持标准输出和深度推理模式的单一大模型,各项评测相比较Claude Sonnet 3.5大幅提升。特别是代码能力进一步增强。
Creative Writing v3 是一个用于评估大型语言模型(LLM)创意写作能力的评测基准。该基准采用混合评分系统,旨在更精确地区分不同模型,特别是顶尖模型之间的性能差异。
MiniMax M2发布2周后已经成为OpenRouter上模型tokens使用最多的模型之一。已经成为另一个DeepSeek现象的大模型了。然而,实际使用中,很多人反馈说模型效果并不好。而此时,官方也下场了,说当前大家使用MiniMax M2效果不好的一个很重要的原因是没有正确使用Interleaved Thinking。正确使用Interleaved thinking模式,可以让MiniMax M2模型的效果最多可以提升35%!本文我们主要简单聊聊这个Interleaved thinking。

RedPajama模型是TOGETHER发布的一个开源可商用的大模型。2023年6月6日,TOGETHER在官方宣布该模型完成训练,经过测试,该模型目前超过所有7B规模的大模型,比LLaMA-7B和Falcon-7B的效果还要好!
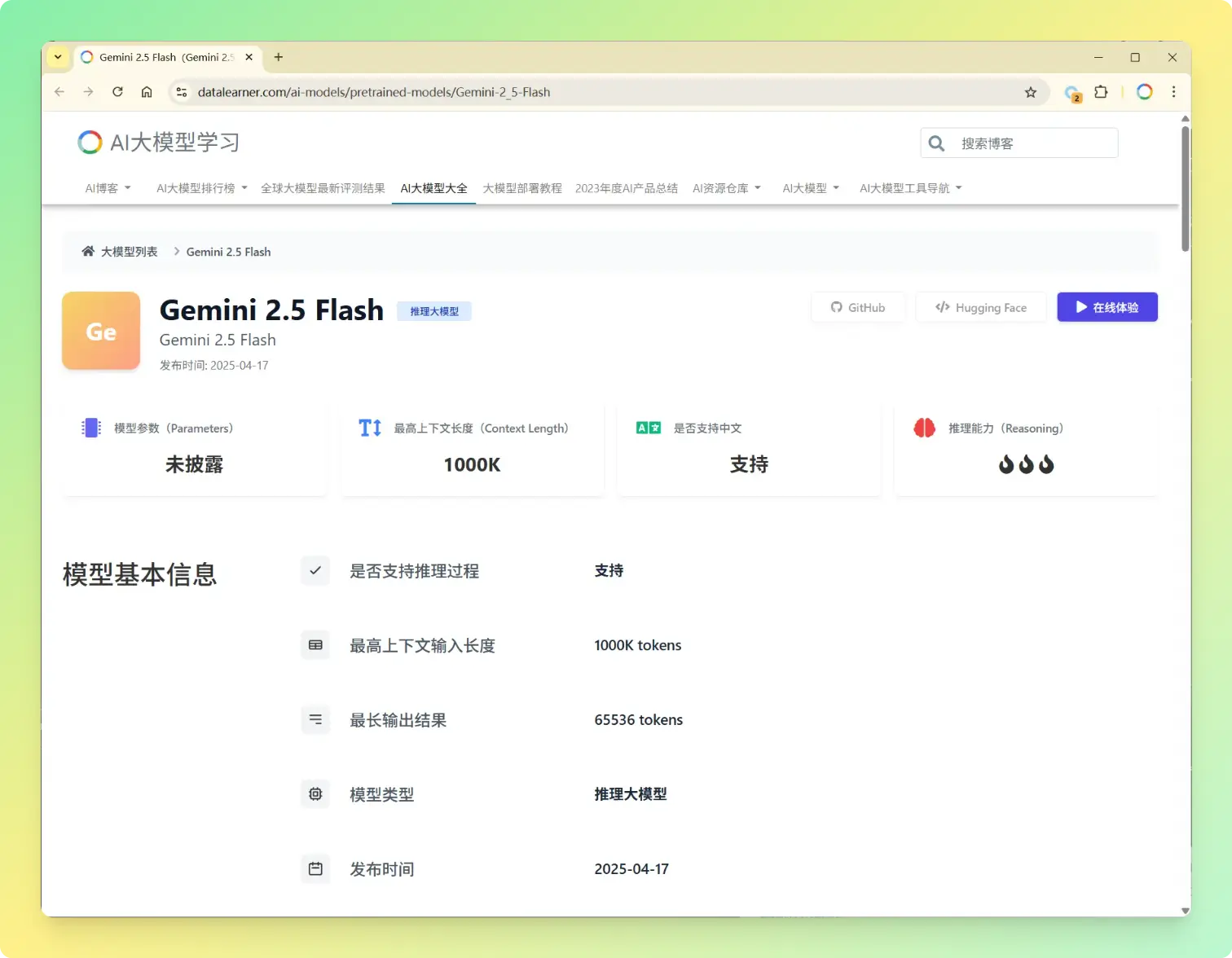
Gemini系列是Google的大模型品牌,2025年3月25日,Google发布了Gemini 2.5 Pro版本,这是谷歌发布的Gemini 2.5系列的第一个模型,参数规模较大,但是在多项评测结果上获得了全球最优的效果,Gemini 2.5 Pro成本比较高,时延也比较大,20天之后,谷歌又发布了Gemini 2.5 Flash模型,是性能、成本和效果的最佳均衡模型。
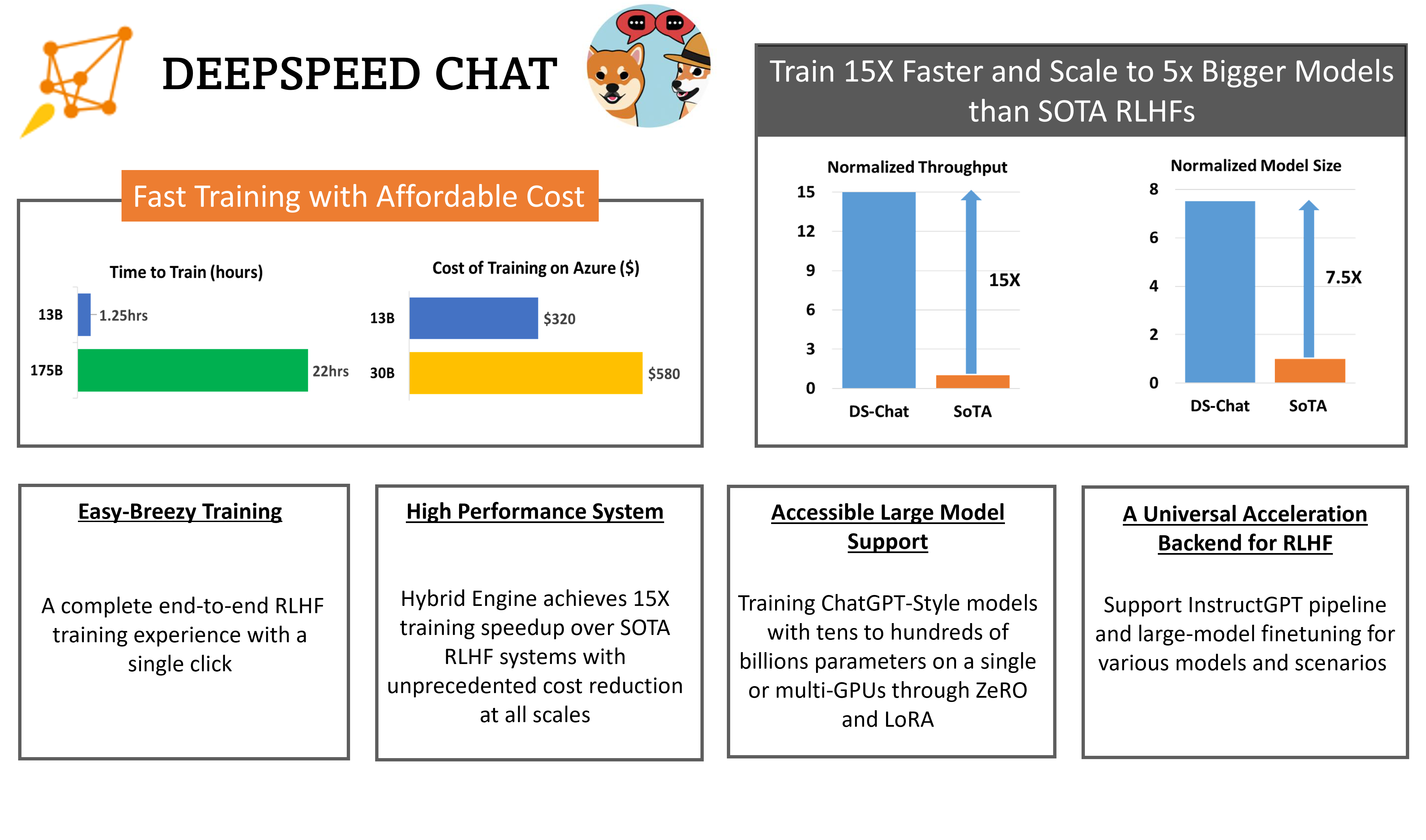
RLHF全称Reinforcement Learning from Human Feedback,是随着ChatGPT火爆之后而被大家所关注的技术。昨天,微软开源了业界第一个RLHF的pipeline框架,可以用来训练类似ChatGPT的模型。

OpenAI Startup Fund是OpenAI和微软等合作伙伴在2022年推出的一个创业基金,收到OpenAI Startup Fund投资的初创企业几乎可以等同于OpenAI认为的未来AI应用重要方向。这些企业不仅可以获得资金支持,还可以比其它企业更早使用OpenAI的模型。本文将简要介绍当前OpenAI已经投资的企业,它们可能是未来AI领域重要的角色!
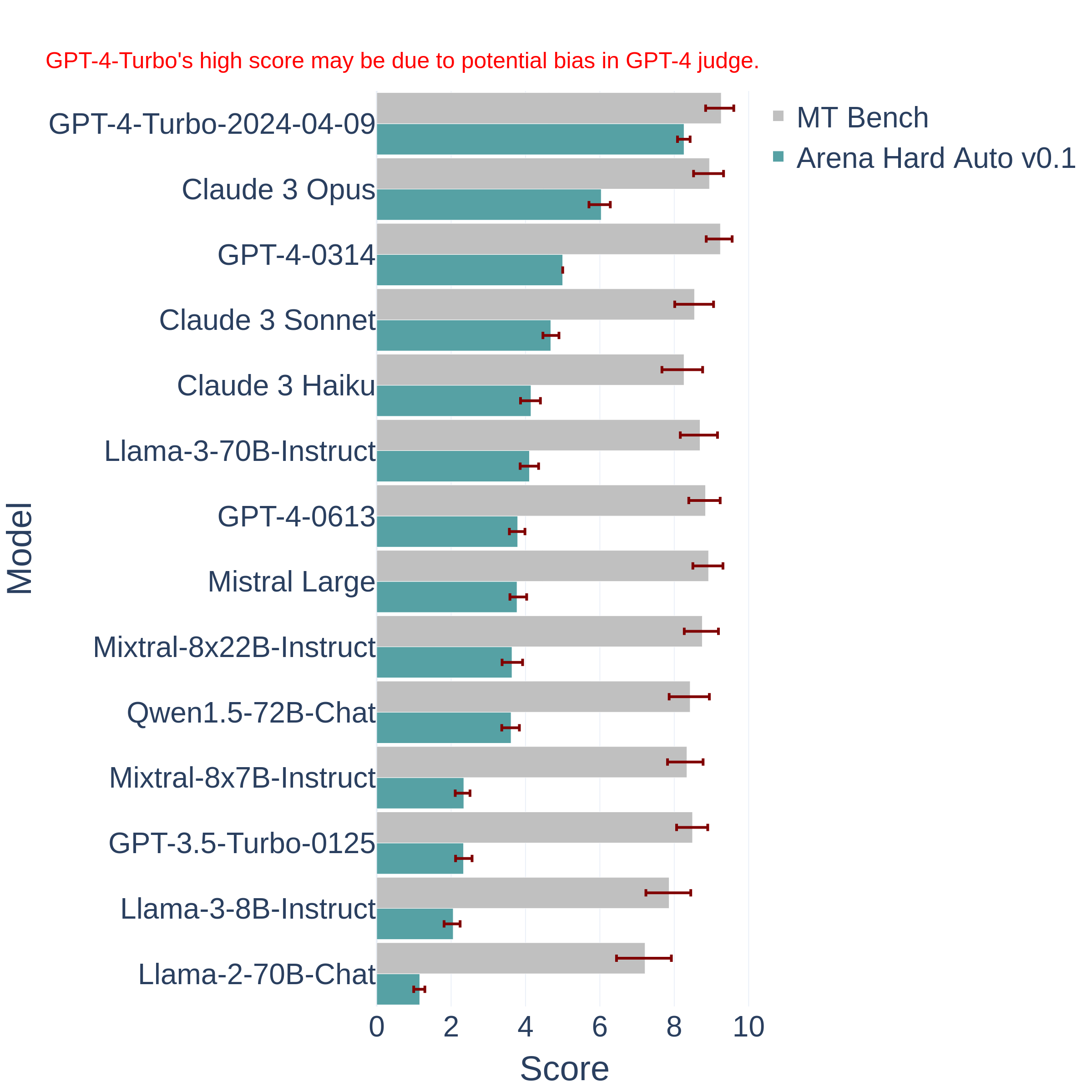
评估日益发展的大型语言模型(LLM)是一个复杂的任务。传统的基准测试往往难以跟上技术的快速进步,容易过时且无法捕捉到现实应用中的细微差异。为此,LM-SYS研究人员提出了一个全新的大模型评测基准——Arena Hard。这个平常基准是基于Chatbot Arena发展而来,相比较常规的评测基准,它更难也更全面。
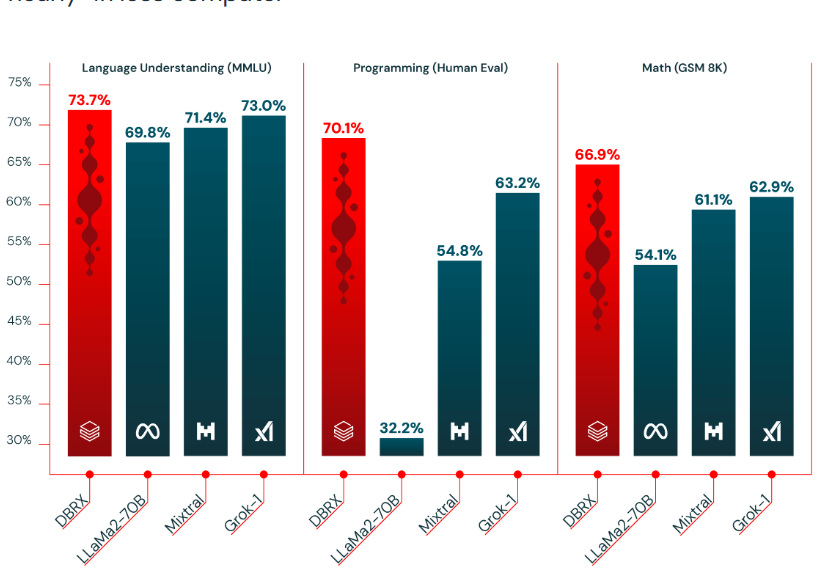
基于混合专家技术的大语言模型是当前大语言模型的一个重要方向。去年MistralAI开源了全球最有影响力的Mixtal-8×7B-MoE模型,吸引了很多关注。在2024年3月27日的今天,Databricks宣布开源一个全新的1320亿参数的混合专家大语言模型DBRX。