OpenAI发布最新最强大的AI对话系统——GPT3.5微调的产物ChatGPT
今天,OpenAI公布了最新的一个基于AI的对话系统ChatGPT,是基于GPT3.5微调的结果,试用显示效果惊人!
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
今天,OpenAI公布了最新的一个基于AI的对话系统ChatGPT,是基于GPT3.5微调的结果,试用显示效果惊人!
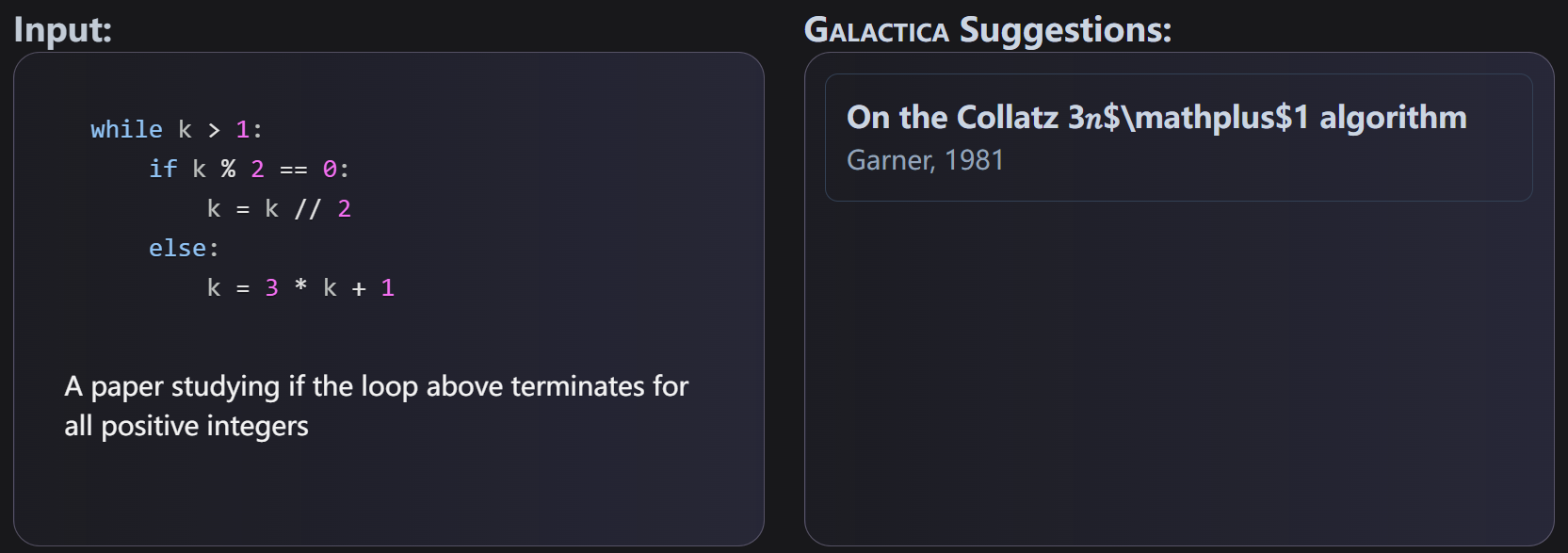
自然语言处理预训练大模型在最近几年十分流行,如OpenAI的GPT-3模型,在很多领域都取得了十分优异的性能。谷歌的PaLM也在很多自然语言处理模型中获得了很好的效果。而昨天,PapersWithCode发布了一个学术论文处理领域预训练大模型GALACTICA。功能十分强大,是科研人员的好福利!

近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。
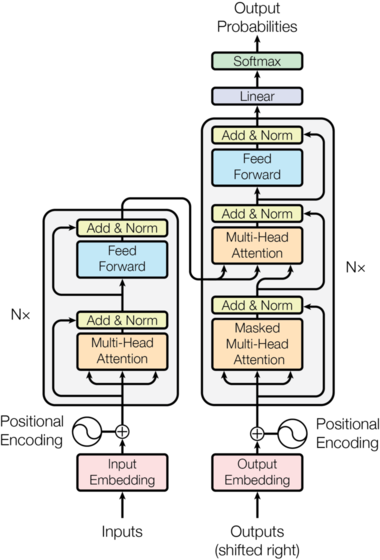
The Annotated Transfomer是哈佛大学的研究人员于2018年发布的Transformer新手入门教程。这个教程从最基础的理论开始,手把手教你按照最简单的python代码实现Transformer,一经推出就广受好评。2022年,这个入门教程有了新的版本。

Batch Normalization(BN)是深度学习领域最重要的技巧之一,最早由Google的研究人员提出。这个技术可以大大提高深度学习网络的收敛速度。简单来说,BN就是将每一层网络进行归一化,就可以提高整个网络的训练速度,并打乱训练数据,提升精度。但是,BN的使用可以在很多地方,很多人最大的困惑是放在激活函数之前还是激活函数之后使用,著名机器学习领域的博主Santiago总结了这部分需要注意的内容。
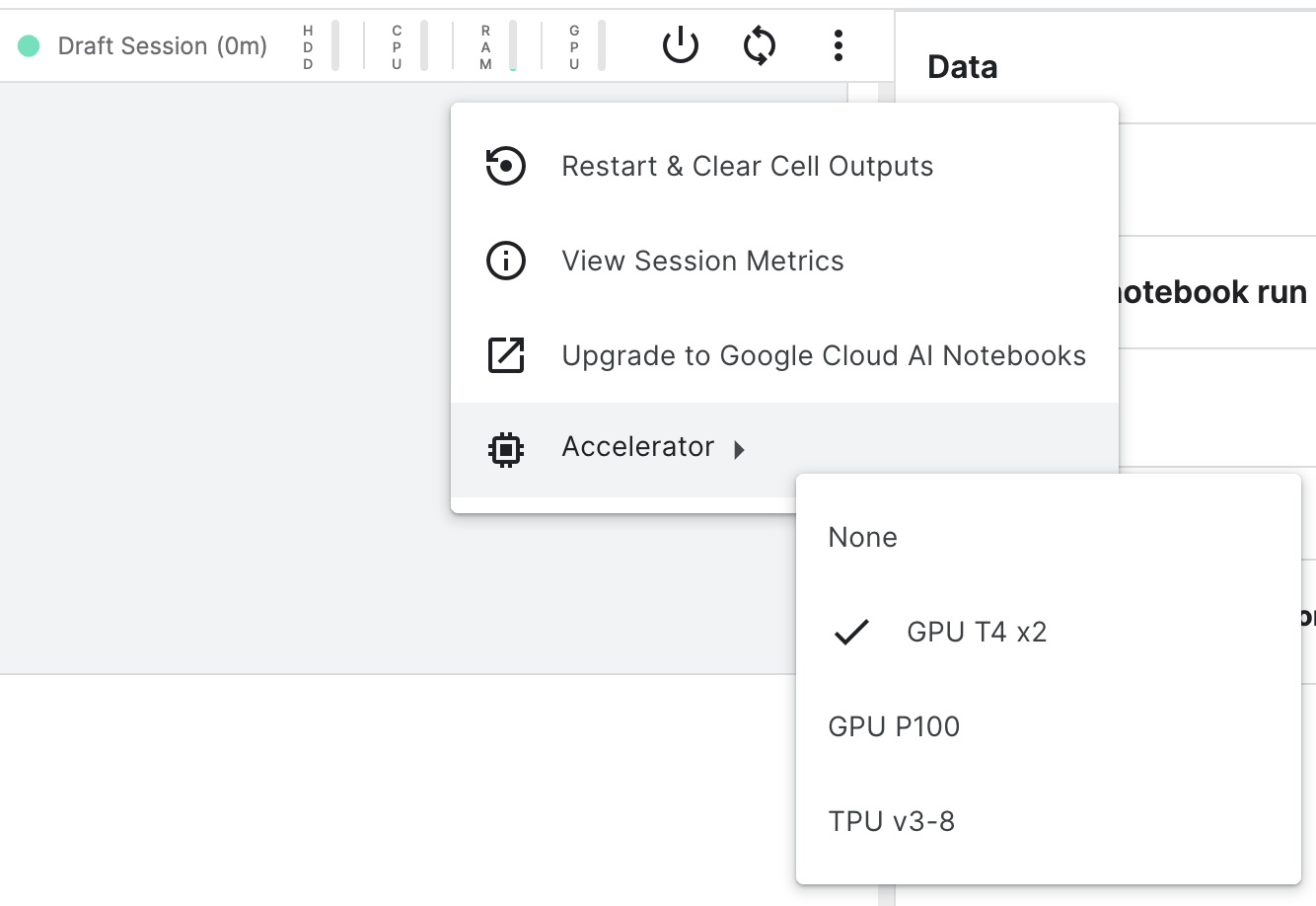
Kaggle是机器学习竞赛平台当之无愧的老大,除了提供了平台让企业和研究机构发布机器学习相关竞赛来让大家竞技和交流以外,他们还提供了免费的编程平台让大家使用免费的GPU和内存来训练模型和测试模型效果。而昨天,Kaggle升级了这些免费资源服务。
Hugging Face一直在努力支持深度学习,但是,这只是深度学习的一部分。传统统计机器学习领域里面最重要的工具Scikit-learn如今终于和深度学习的开源标杆工具Hugging Face联手。
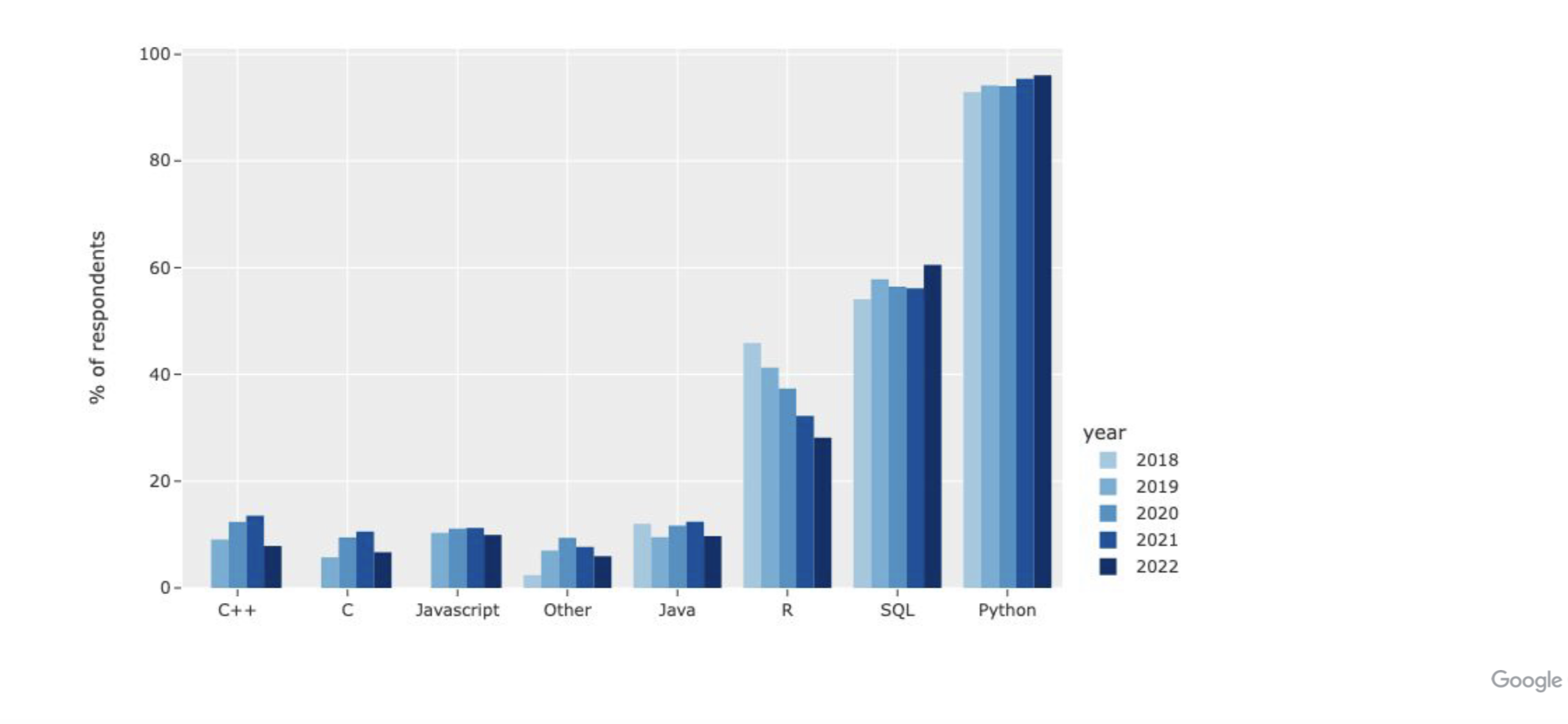
kaggle是各类机器学习竞赛的著名平台,上面聚集了大量的机器学习比赛和数据集,也有大量的数据处理相关专业人员。每年官方都会向平台用户发放问卷,调查数据科学家的工具使用和平台采用情况。今年的调查结果也在两天前发出,有很多有意思的结论。
预测在全球决策中发挥着关键作用。例如,关于COVID-19扩散的预测为国家封锁提供了信息,而经济预测则影响了利率的制定。这些预测通常依赖于人类专家的仔细判断,他们必须考虑来自各种来源的数据。由于人工智能系统能够处理大量的数据,它们在这个领域有可能非常有用。 为此,ML Safety举办了一个关于AI预测的竞赛,比赛的目的是建立一个机器学习模型,做出准确和校准的预测。
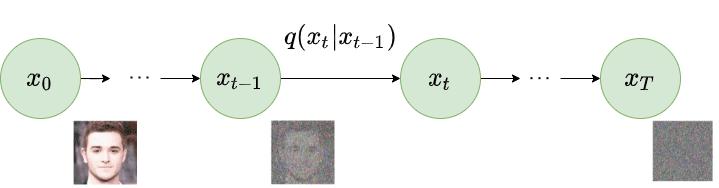
随着DALL·E2的发布,大家发现Text-to-Image居然可以取得如此好的效果。也让diffusion模型变得非常受欢迎。扩散模型虽然火热,但是背后的数学原理可能很多人也不太了解。这篇博客不仅介绍了扩散模型背后的数学原理,也讲述了如何训练扩散模型以及提高扩散模型训练效率的种种技巧,十分值得大家钻研。
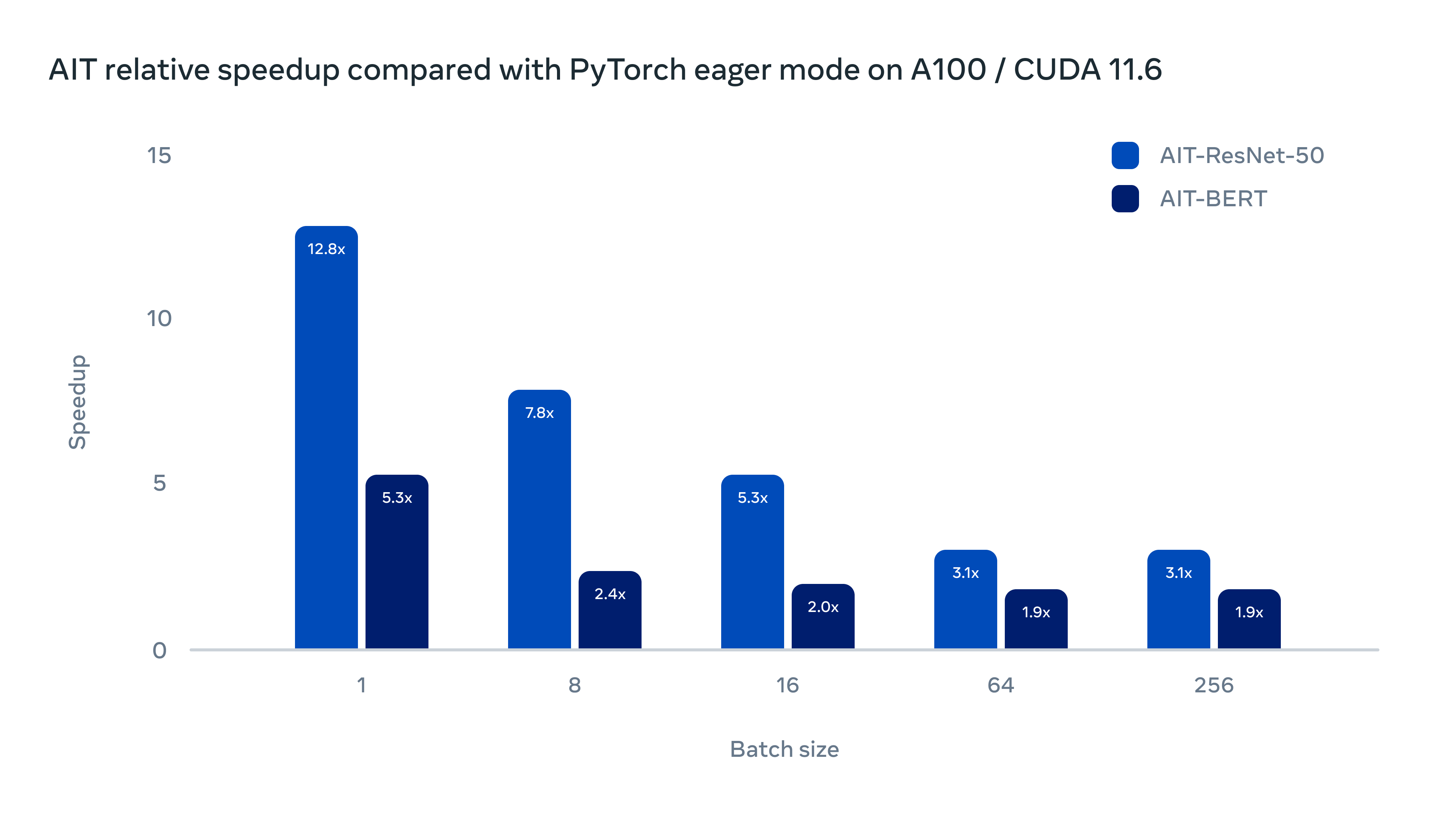
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。

九月份刚过去,GitHub上最火的AI研究排序出炉。这是根据9月份GitHub上创建的新的AI研究相关的项目排序,根据Star的数量来的。都是AI各大领域比较受欢迎和重要的项目。

随着NLP预训练模型的发展,大语言模型在各个领域的作用也越来越大。几个月前,GitHub基于OpenAI的GPT-3训练的Copilot效果十分惊艳,可惜现在已经开始收费。而最近,清华大学也发布了一个代码补全神器——CodeGeeX。
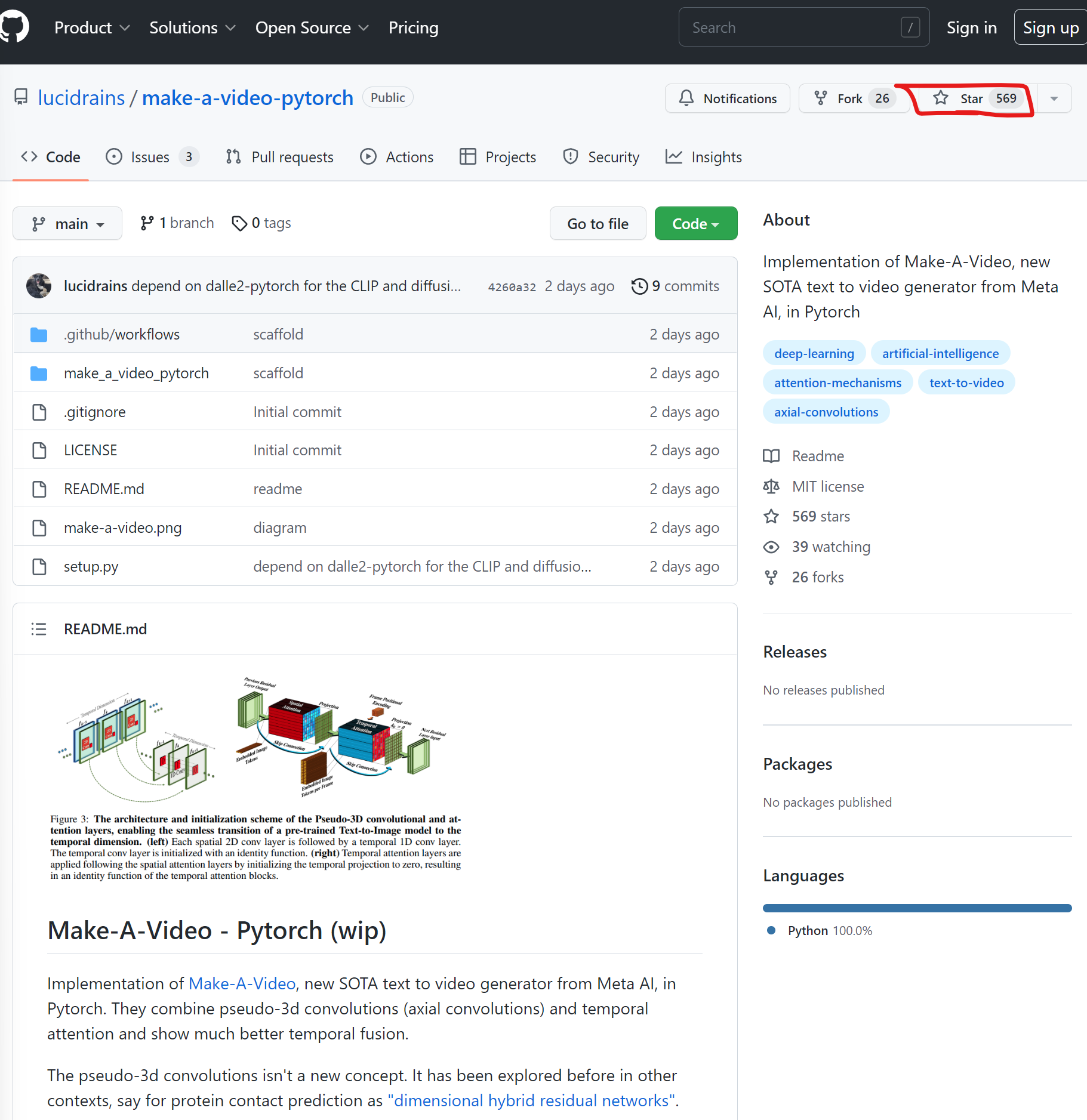
MetaAI在2天前刚发布了一个最新的Text-to-Video模型,让生成模型从逼真的图片生成往前推进到视频生成。当然,官方还是希望将其当作一种SaaS服务提供。但是,才2天,业界基于论文的开源PyTorch实现就已经准备公开,且获得了569个Star!卷到家了!
DALLE·2的出现,让大家认识到原来文本生成图片可以做到如此逼真效果,此后Stable Diffusion的开源也让大家把Text-to-Image玩出花了。而现在,Meta AI的研究人员让这个工作继续往前一步,发布了Text-to-Video的预训练模型:Make-A-Video。

Stable Diffusion是一种功能强大的开源文本到图像(Text-to-Image)生成模型。虽然目前有多个开源项目可以实现基于文本提示(prompt)创建图像,但Stable Diffusion性能极其强大,其结果甚至可以媲美DALL·E2。而现在KerasCV提供了这个模型的官方实现!
KerasCV是由Keras官方团队发布的一个计算机视觉框架,可以帮助大家用来处理计算机视觉领域的相关任务和问题。这是2022年4月刚发布的最新产品,由于是官方团队出品的工具,所以质量有保证,且社区活跃,一直在积极更新。
少量标记的学习(Few-shot learning)是一种在较少标注数据集中进行模型训练的一种学习方法。为了解决大量标注数据难以获取的情况,利用预训练模型,在少量标记的数据中进行微调是一种新的帮助我们进行模型训练的方法。而就在昨天,Hugging Face发布了一个新的语句transformers(Sentence Transformers)框架,可以针对少量标记数据进行模型微调以获取很好的效果。

马尔可夫链(Markov Chain)是由马尔可夫性质推导出来的一种重要的概率模型。马尔科夫链是一种离散时间的随机过程,作为现实世界的统计模型,有很多应用。在热力学、统计力学、排队理论、金融领域等都有重要的应用价值。 作为一种离散时间的随机过程,与其对应的模型是马尔可夫过程(Markov Process),这是一种连续时间随机过程的模型。本节将主要介绍马尔科夫链。
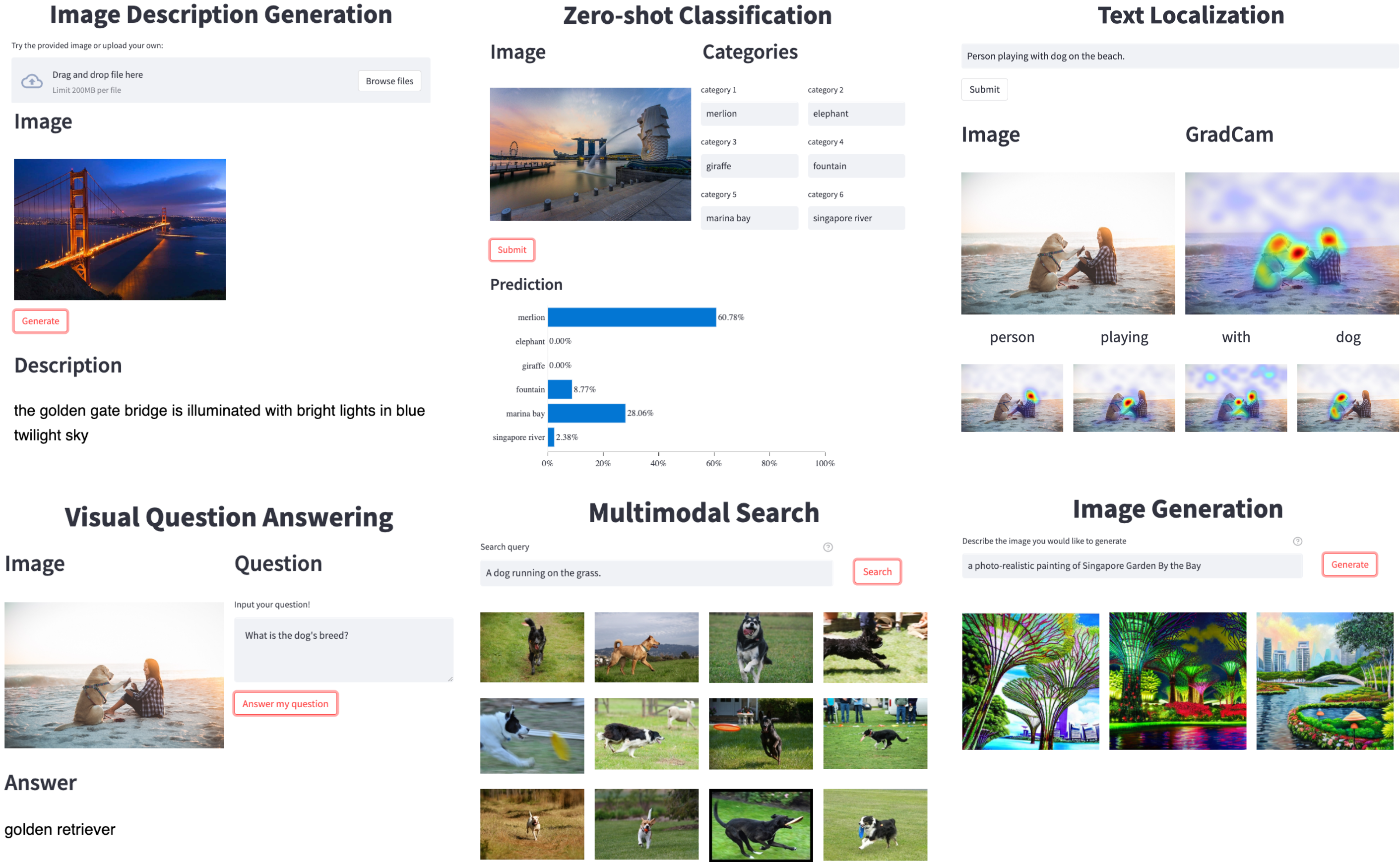
Salesforce的研究人员开发了LAVIS(LAnguage-VISION的缩写),这是一个开源的库,用于在丰富的常见任务和数据集系列上训练和评估最先进的语言-视觉模型,并用于在定制的语言-视觉数据上进行现成的推理。
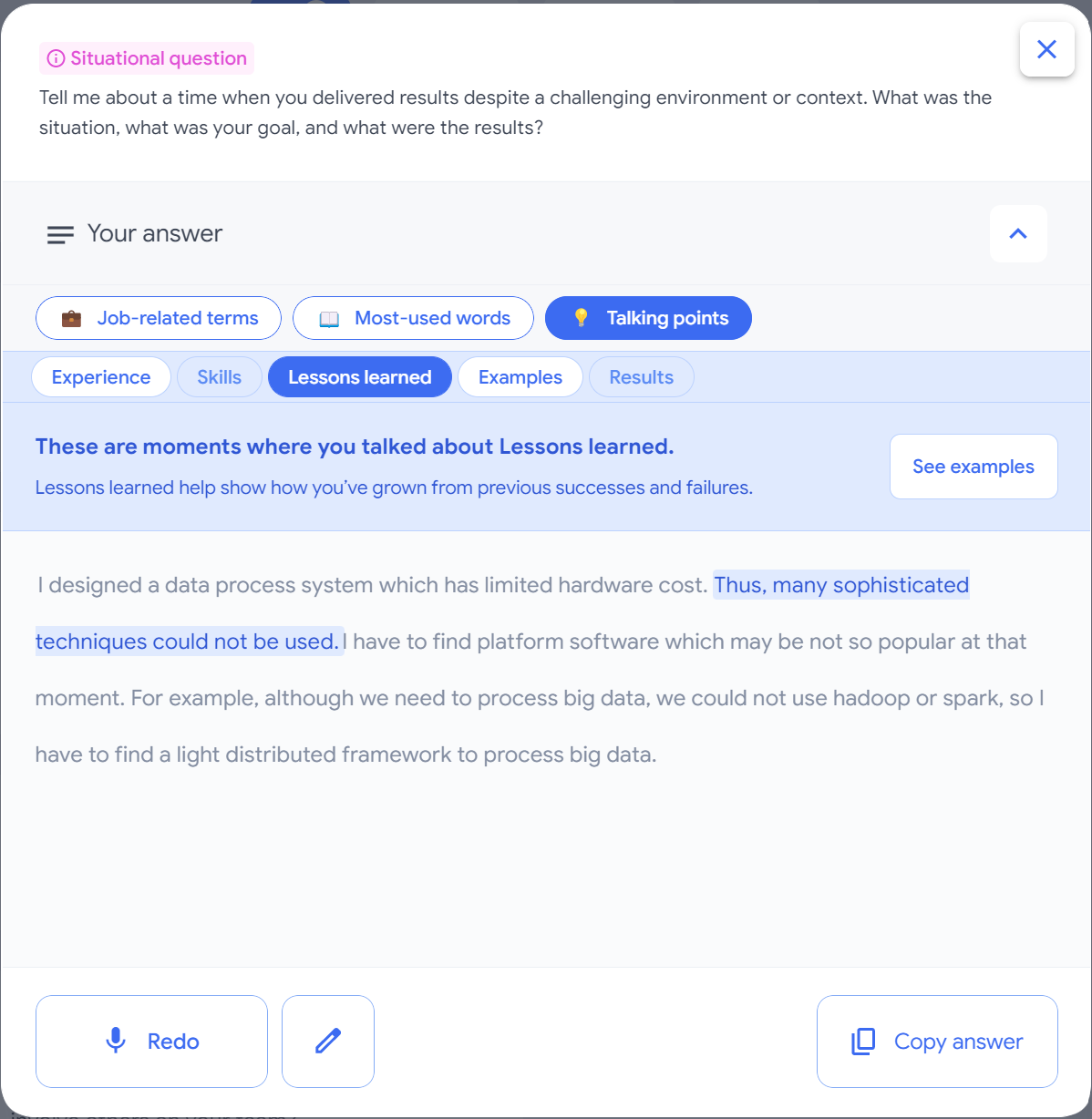
最近,谷歌发布了一项新的工具:Google Interview Warmup,让你练习回答由行业专家选定的问题,并使用机器学习来转录你的答案,帮助你发现改进面试的回答。
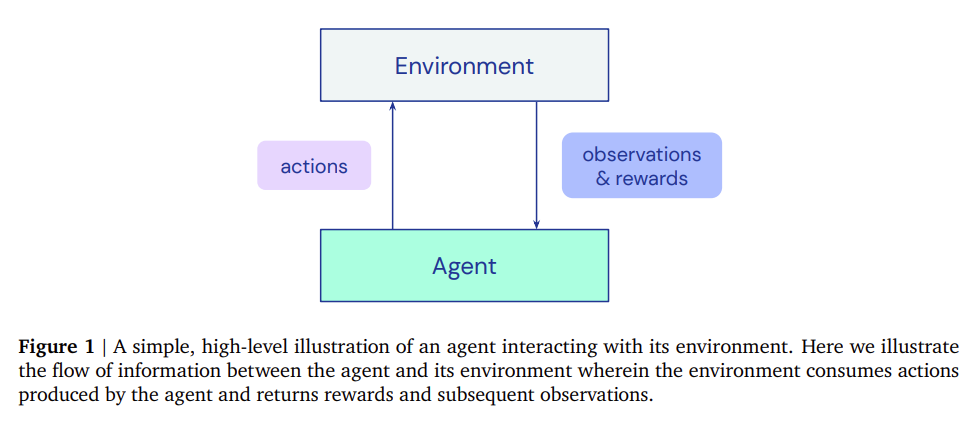
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的

今天Google发布了TensorStore,这是一个开源的C++和Python软件库,设计用于存储和操作大规模n维数据。TensorStore已经被用来解决科学计算中的关键工程挑战(例如,管理和处理神经科学中的大型数据集,如石油级的三维电子显微镜数据和神经元活动的 "4d "视频)。TensorStore还被用于创建大规模的机器学习模型,如PaLM,解决了分布式训练期间管理模型参数(检查点)的问题。