重磅!苹果官方发布大模型框架:一个可以充分利用苹果统一内存的新的大模型框架MLX,你的MacBook可以一键运行LLaMA了
苹果刚刚发布了一个全新的机器学习矿机MLX,这是一个类似NumPy数组的框架,目的是可以在苹果的芯片上更加高效地运行各种机器学习模型,当然最主要的目的是大模型。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
苹果刚刚发布了一个全新的机器学习矿机MLX,这是一个类似NumPy数组的框架,目的是可以在苹果的芯片上更加高效地运行各种机器学习模型,当然最主要的目的是大模型。
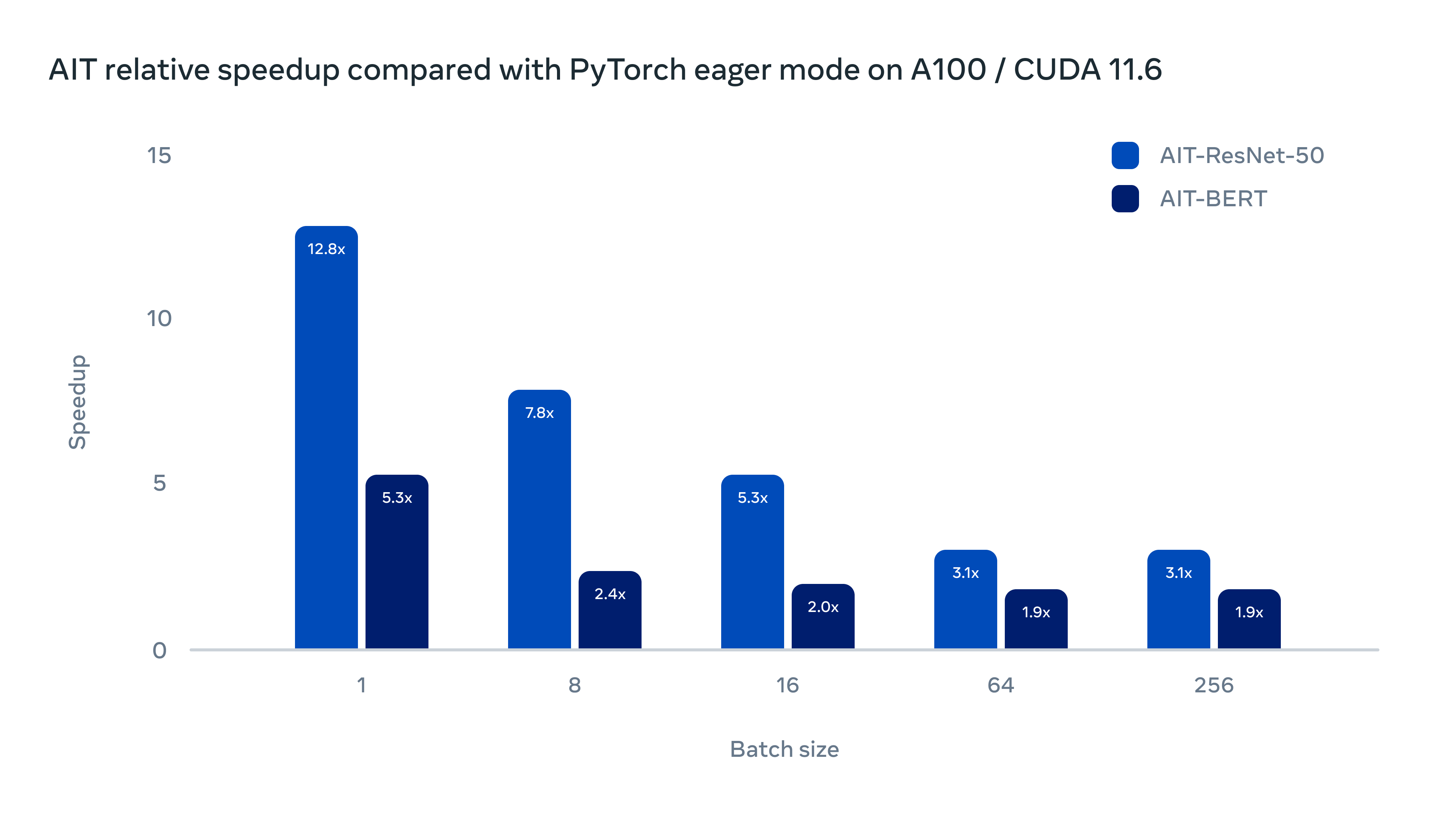
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。
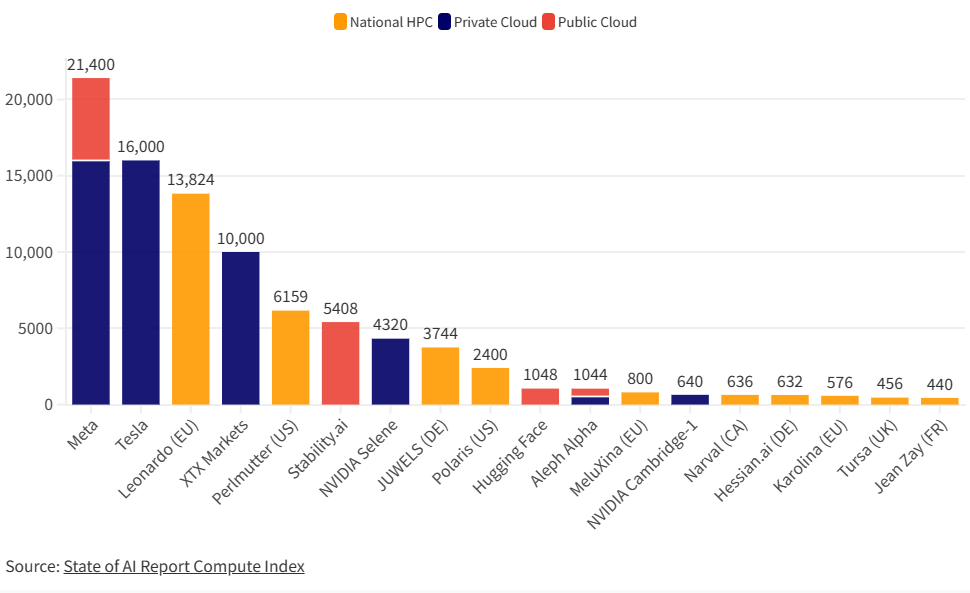
在高性能计算(HPC)、人工智能(AI)、和数据分析等领域,图形处理器(GPUs)正在发挥越来越重要的作用。其中,NVIDIA的 A100尤为引人注目。这是英伟达最强大的显卡处理器,也是当前使用最广泛大模型训练用的显卡。本文主要是各大企业最新的2023年9月份拥有的显卡数量统计。


刚刚,StabilityAI宣布Stable Diffusion2.1发布。距离Stable Diffusion2.0大版本发布刚2个星期,2.1版本就发布了,2.1版本有诸多改进功能。

Llama3是MetaAI开源的最新一代大语言模型。一发布就引起了全球AI大模型领域的广泛关注。这是MetaAI开源的第三代大语言模型,也是当前最强的开源模型。但相比较第一代和第二代的Llama模型,Llama3的升级之处有哪些?本文以图表的方式总结Llama3的升级之处。

Batch Normalization(BN)是深度学习领域最重要的技巧之一,最早由Google的研究人员提出。这个技术可以大大提高深度学习网络的收敛速度。简单来说,BN就是将每一层网络进行归一化,就可以提高整个网络的训练速度,并打乱训练数据,提升精度。但是,BN的使用可以在很多地方,很多人最大的困惑是放在激活函数之前还是激活函数之后使用,著名机器学习领域的博主Santiago总结了这部分需要注意的内容。

Pandas和NumPy是Python数据科学领域中最基础的两个库,他们都可以读取大量的数据并对数据做计算等处理。有很多的操作他们都能做。那么,这两个Python库在数据处理的性能上有什么差别呢?今天在Reddit上看到一个有意思的讨论和大家分享一下。
腾讯AI Lab去年四月成立,今年是首次参加ICML,共计四篇文章被录取,位居国内企业前列。此次团队由机器学习和大数据领域的专家、腾讯AI Lab主任张潼博士带领到场交流学习,张潼博士还担任了本届ICML领域主席。在本次130人的主席团队中,华人不超过10位,内地仅有腾讯AI Lab、清华大学和微软研究院三家机构。

现代软件企业中,SaaS服务提供商是最值得注意的企业。因为SaaS行业规模大利润高,也是最有前景的一类企业。但是,国内市场因为很多因素导致SaaS的规模和空间都比较低。本文梳理一下全球最大的10个SaaS服务提供商,供大家参考。

Cornell Tech开源了LLMTune,这是一个可以在消费级显卡上微调大模型的框架,经过测试,可以在48G显存的显卡上微调4bit的650亿参数的LLaMA模型!
本文是Effective Java第三版笔记的第七个之消除过期的对象引用,Item 7: Eliminate obsolete object references

大模型的发展一个重要的基础条件是底层硬件计算能力的大幅提高,特别是GPU的发展,与transformer架构的大模型训练非常契合。当前全球最大的GPU供应商英伟达系列的显卡几乎垄断了大模型训练与推理的所有GPU芯片市场。除了英伟达显卡本身算力强悍外,基于英伟达GPU之上构建的CUDA、PyTorch等平台软件生态也是非常重要的一环。而最新的PyTorch2.1版本发布的一个beta特性中包含了对华为昇腾芯片的原生支持,这也是大模型生态多样性发展的一个很重要的信号。
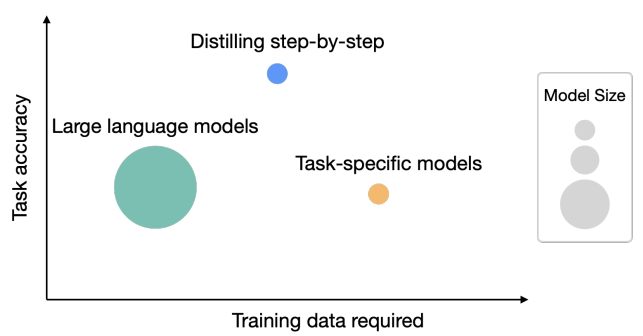
华盛顿大学研究人员与Google的研究人员一起在5月3日公布了一个新的方法,即逐步蒸馏(Distilling step-by-step),这个方法最大的特点有2个:一是需要更少的数据来做模型的蒸馏(根据论文描述,平均只需要之前方法的一半数据,最多只需要15%的数据就可以达到类似的效果);而是可以获得更小规模的模型(最多可以比原来模型规模小2000倍!)
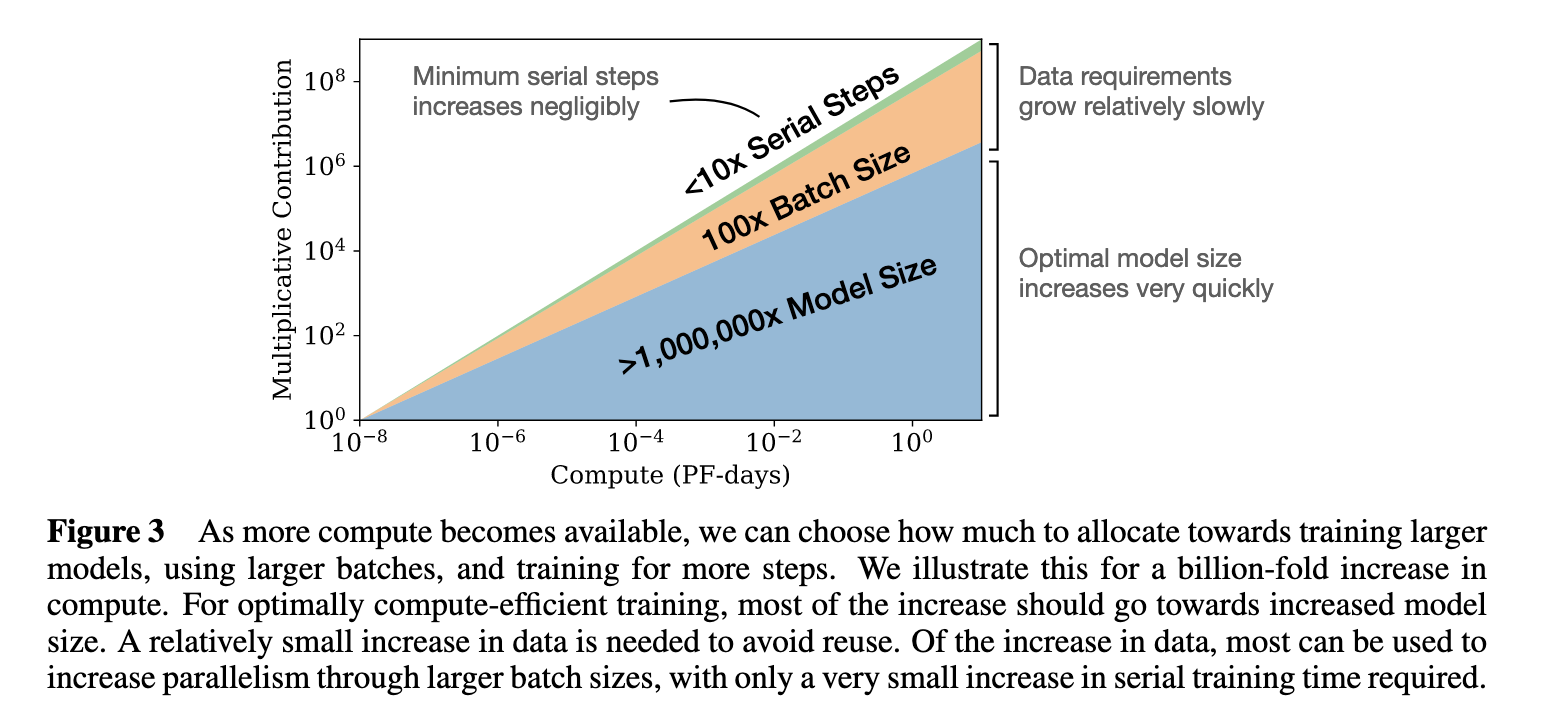
3月29日,DeepMind发表了一篇论文,"Training Compute-Optimal Large Language Models",表明基本上每个人--OpenAI、DeepMind、微软等--都在用极不理想的计算方式训练大型语言模型。论文认为这些模型对计算的使用一直处于非常不理想的状态。并提出了新的模型缩放规律。