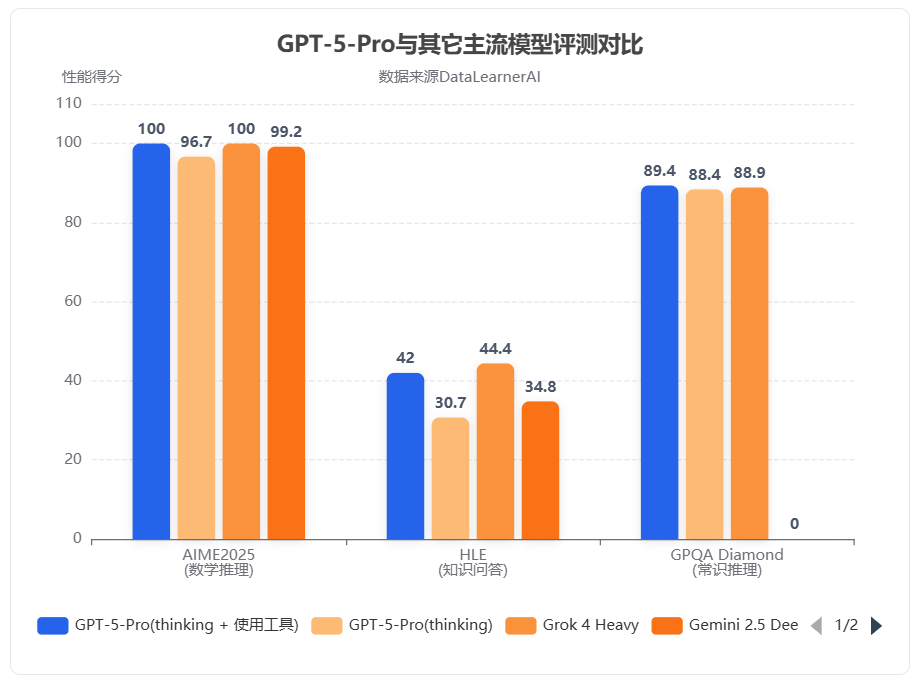
Kimi开源K2大模型:全球首个开源可商用的1万亿参数规模大模型,MoE架构,评测结果与DeepSeekV3相当,但模型文件有1TB!
Kimi K2是由Moonshot AI最新推出的旗舰级大模型,首次将开放Agentic Intelligence(自主代理智能)与强大工具调用能力有机整合。它不仅在知识推理、数学、代码等传统“非思维模型”任务上展现出全球领先的能力,还特别针对一系列实际Agentic(自动决策与操作型)任务进行了深度优化。在业内,这代表AI模型正从“只会答题”向“能自主完成复杂任务”转变。K2模型完全开源,可免费商用授权。