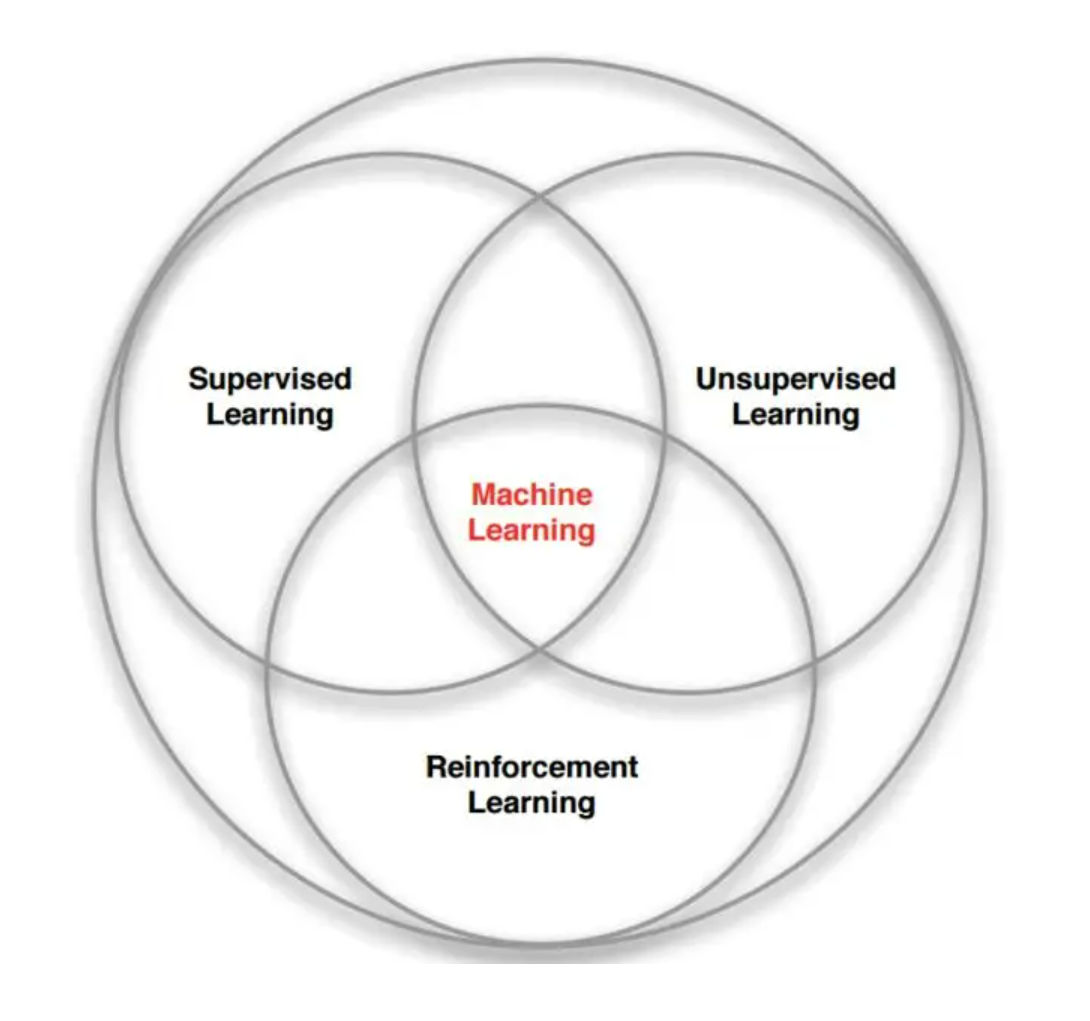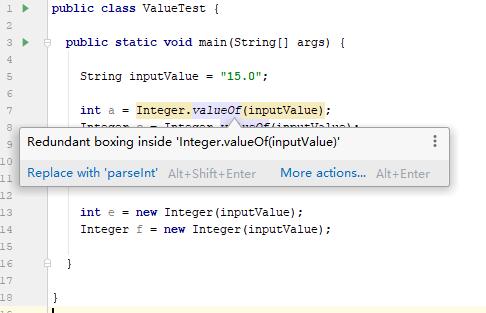
Java类型转换中valueOf方法和parseInt方法的区别
在Java的类型转换中,我们经常会使用valueOf或者parseInt(parseFloat/parseDouble等)来转换。这二者有什么区别呢?这里简要介绍一下。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
在Java的类型转换中,我们经常会使用valueOf或者parseInt(parseFloat/parseDouble等)来转换。这二者有什么区别呢?这里简要介绍一下。

在进行编程操作的时候,我们常常会遇到很多与编程无关的项目管理工作,如下载依赖、编译源码、单元测试、项目部署等操作。一般的,小型项目我们可以手动实现这些操作,然而大型项目这些工作则相对复杂。构建工具是帮助我们实现一系列项目管理、测试和部署操作的工具。本文将对Java构建工具做简单介绍。

NVIDIA在2024年GPU技术大会(NVIDIA GPU Technology Conference,GTC)发布了全新的算力芯片和服务,即基于最新的Blackwell架构的算力芯片B200和GB200服务器。但是,大多数人对于NVIDIA芯片的升级只有数字的变化,本文将针对NVIDIA的GPU算力芯片做简单的介绍,并说明NVIDIA B200以及GB200的升级的地方。

LLaMA是由Meta开源的一个大语言模型,是最近几个月一系列开源模型的基础模型。包括著名的vicuna系列、LongChat系列等都是基于该模型微调得到。可以说,LLaMA的开源促进了大模型在开源界繁荣发展。而刚刚,微软官方宣布Azure上架LLaMA2模型!这意味着LLaMA2正式发布!
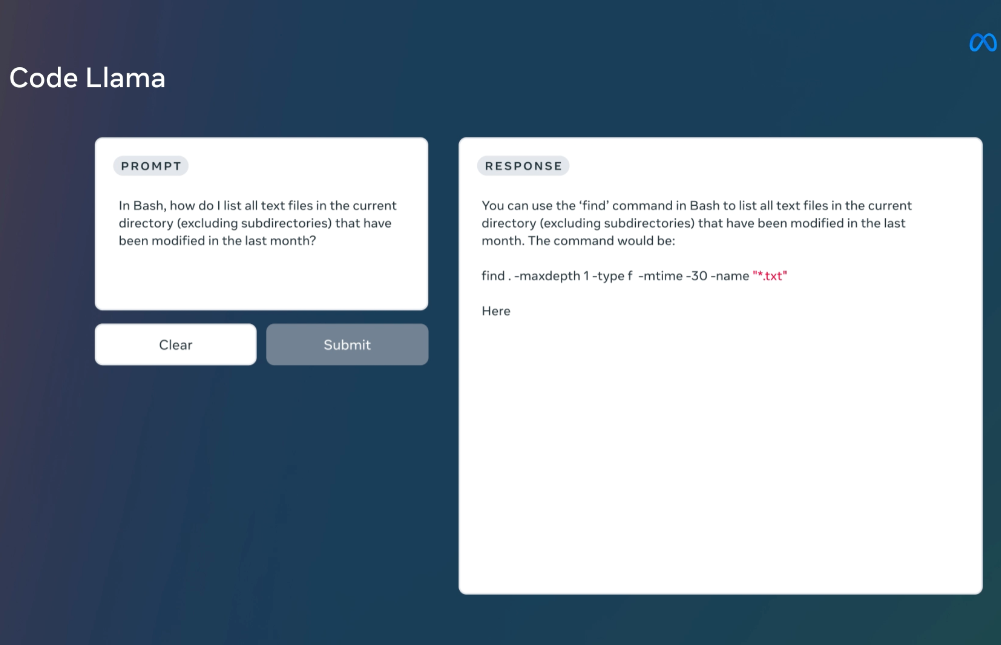
MetaAI发布的LLaMA系列开源大语言模型已经是开源大模型领域最重要的力量了。相当多的所谓开源大模型都是基于这个模型微调得到。在上个月,LLaMA2发布,吸引了全球非常多的关注,也有相当多的后续模型基于LLaMA2进行优化。而今天MetaAI再次开源全新的编程大模型——CodeLLaMA系列,这是MetaAI第一次发布编程大模型,本次发布的CodeLLaMA共有9个版本,分别是CodeLLaMA系列、针对Python优化的CodeLLaMA-Python系列和针对指令优化的CodeLLaMA-Inst
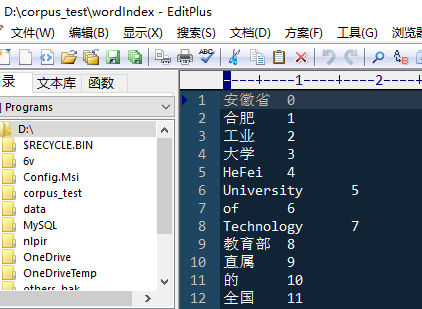
HFUTUtils是一个工具程序集合,方便我们平时处理数据。针对文本处理的内容较多。使用起来非常简单。是本人平时使用Java处理数据时候写的工具,方便数据预处理的。
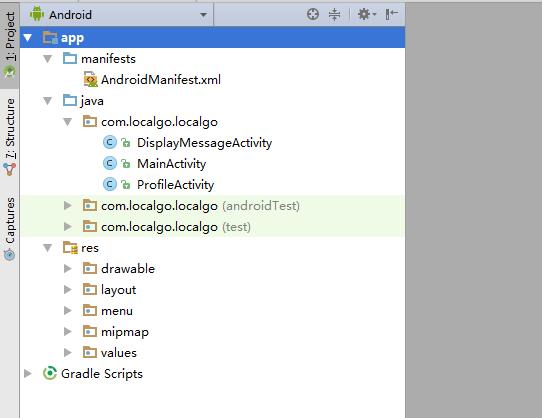
Android是基于Linux的修改版本的移动操作系统。 大多数Android代码是在开源Apache许可证下发布的。本文将简单介绍Android开发入门知识。
OpenAI在其官方GitHub上公开了一个最新的开源Python库:tiktoken,这个库主要是用力做字节对编码的。相比较HuggingFace的tokenizer,其速度提升了好几倍。
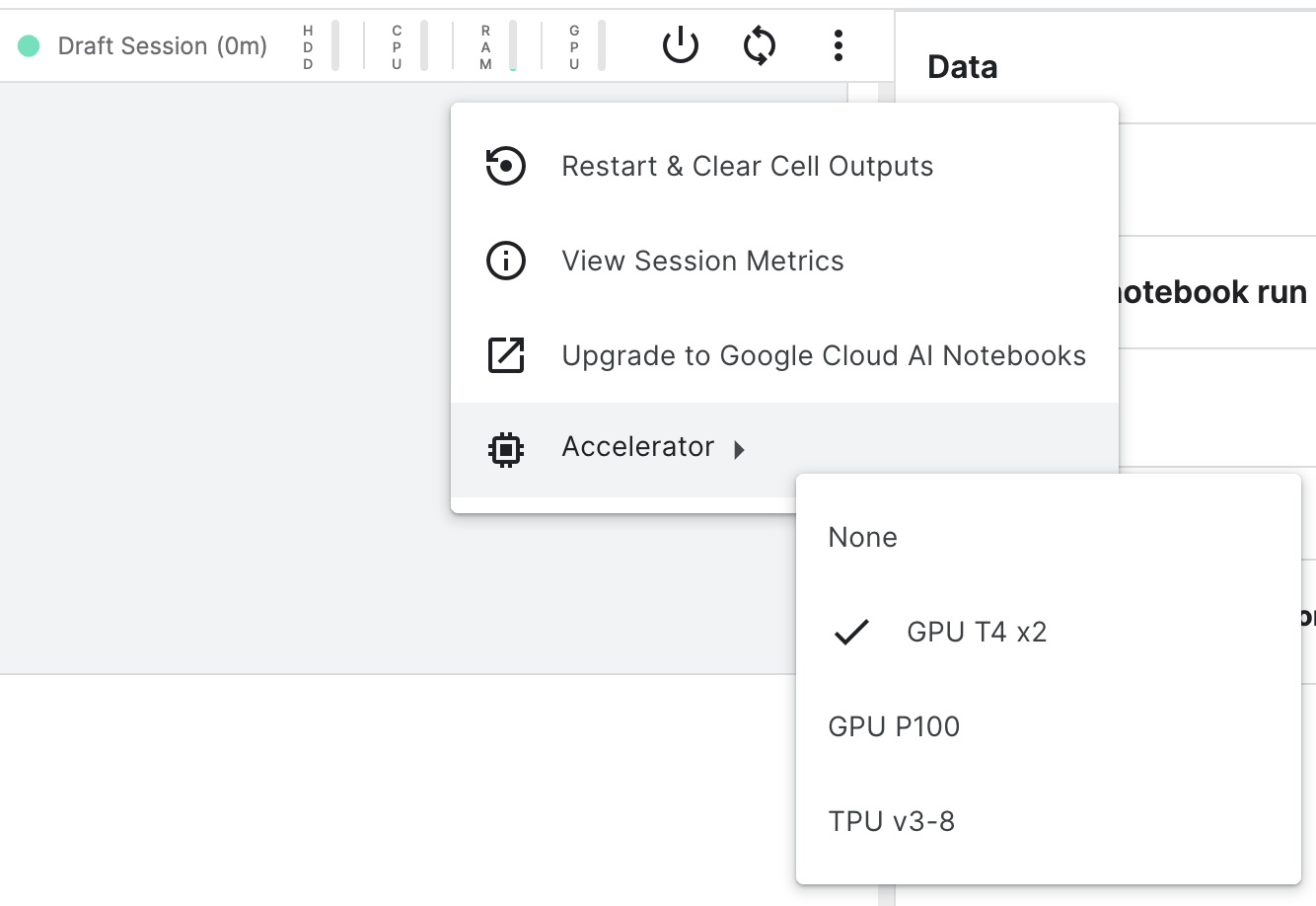
Kaggle是机器学习竞赛平台当之无愧的老大,除了提供了平台让企业和研究机构发布机器学习相关竞赛来让大家竞技和交流以外,他们还提供了免费的编程平台让大家使用免费的GPU和内存来训练模型和测试模型效果。而昨天,Kaggle升级了这些免费资源服务。
本文是Steffen Rendle的Pairwise Interaction Tensor Factorization for Personalized Tag Recommendation的译文。

ChatGPT是最近半年多全球最火的产品。去年11月底发布之后,ChatGPT仅仅2个月时间就收获了1亿的月活。尽管在前几个月,ChatGPT是一枝独秀的存在,几乎没有任何可以与其竞争的产品与服务。然而在2023年7月份快结束的今天,市场上已经有相当多优秀的产品可供大家使用。
广告分配问题属于运筹中的优化问题。一般情况下,我们期望有个最大化收益,但同时需要保证合约的完成。因此,这是一个带不等式约束的最优化问题。由于广告数量和用户数量很多,因此,求解的难度很高。在这篇文章中,作者推导了原问题的拉格朗日函数的系数之间的关系,大大降低了求解的难度。这里将简要介绍原理和推导过程。
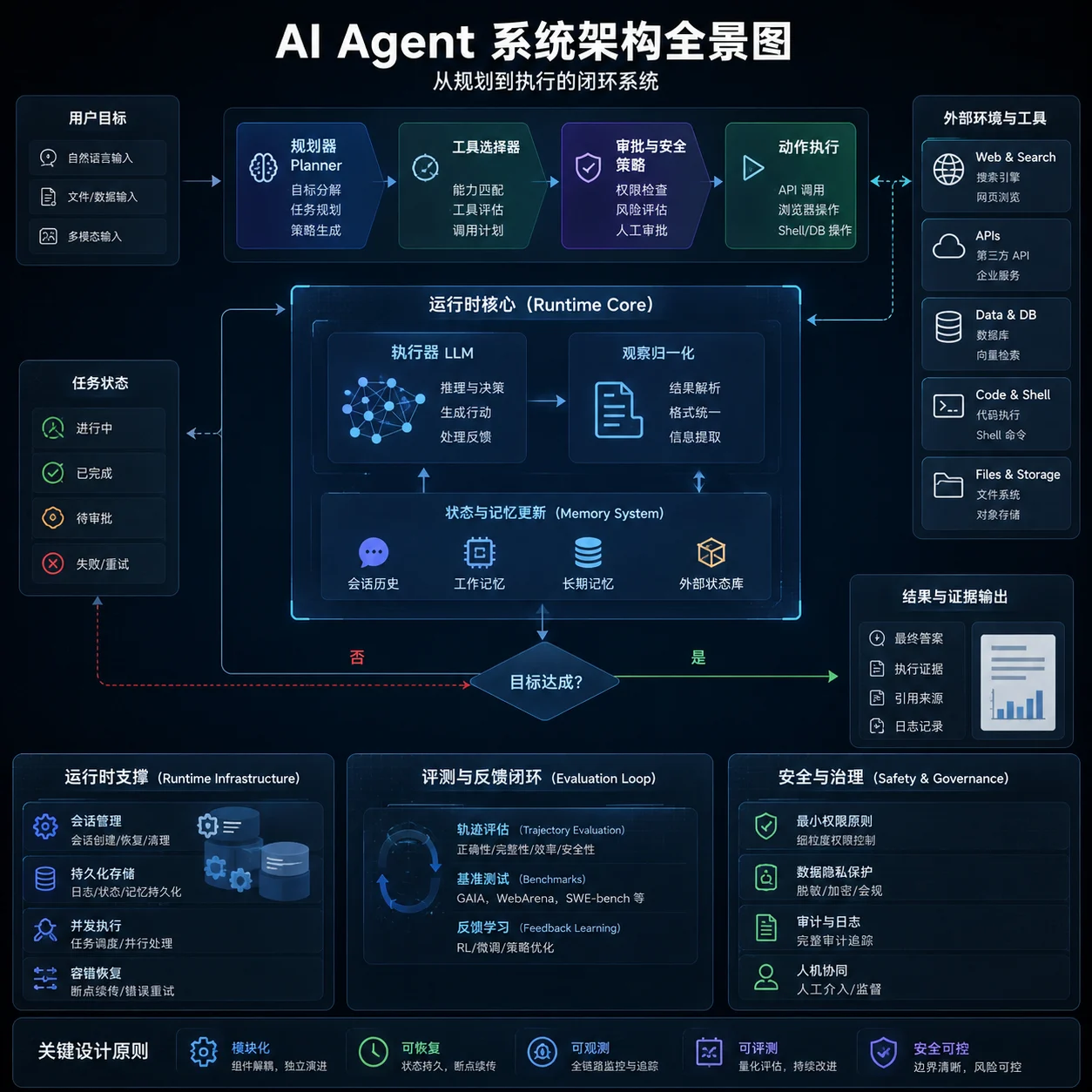
本报告按用户要求以中文撰写,时间范围优先覆盖 2024–2026,并纳入若干对当前路线仍具决定性影响的 2023 奠基工作;不假设预算、组织规模或行业约束。报告优先采用近两年论文、顶会/期刊页面、arXiv 摘要页,以及 OpenAI、Anthropic、Google、AWS、Microsoft、Salesforce、NIST、OWASP 等一手文档。
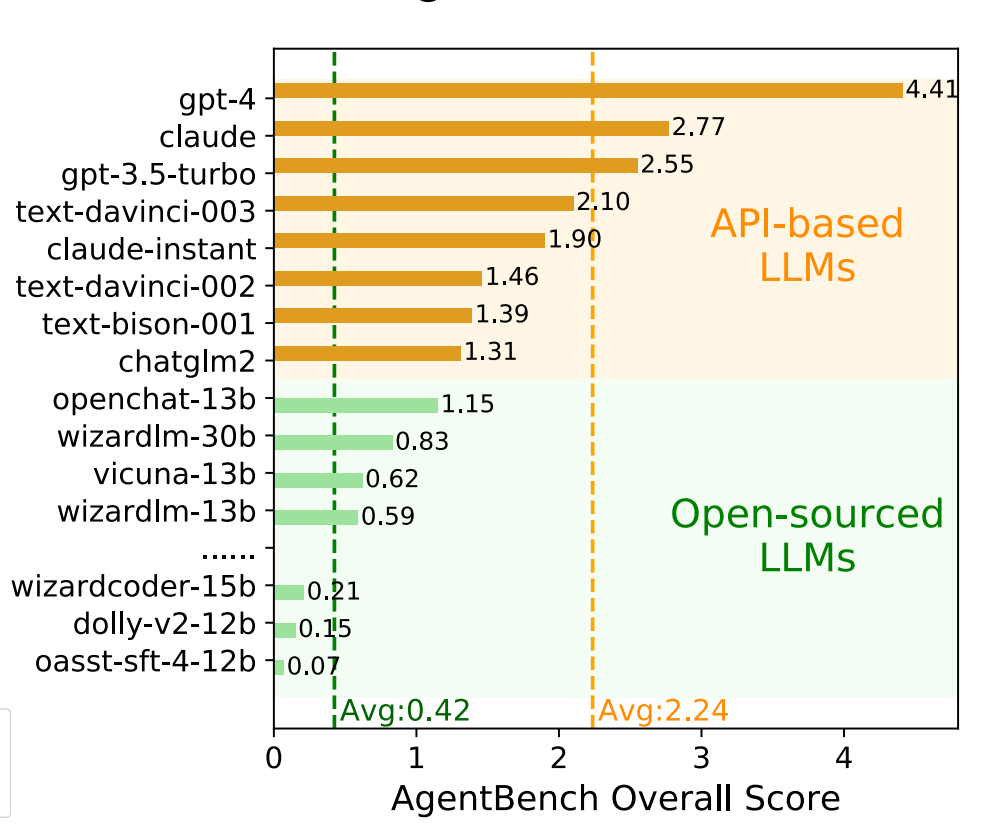
所谓AI Agent就是一个以LLM为核心控制器的一个代理系统。业界开源的项目如AutoGPT、GPT-Engineer和BabyAGI等,都是类似的例子。然而,并不是所有的AI Agent都有很好的表现,其核心还是取决于LLM的水平。尽管LLM已经在许多NLP任务上取得进步,但它们作为代理完成实际任务的能力缺乏系统的评估。清华大学KEG与数据挖掘小组(就是发布ChatGLM模型)发布了一个最新大模型AI Agent能力评测数据集,对当前大模型作为AI Agent的能力做了综合测评,结果十分有趣。

SQLCoder 是 Defog 团队推出的一款前沿的语言模型,专门用于将自然语言问题转化为 SQL 查询。这是一个拥有150亿参数的模型,其性能略微超过了 gpt-3.5-turbo 在自然语言到 SQL 生成任务上,并且显著地超越了所有流行的开源模型。更令人震惊的是,尽管 SQLCoder 的大小只有 text-davinci-003 的十分之一,但其性能却远超后者。
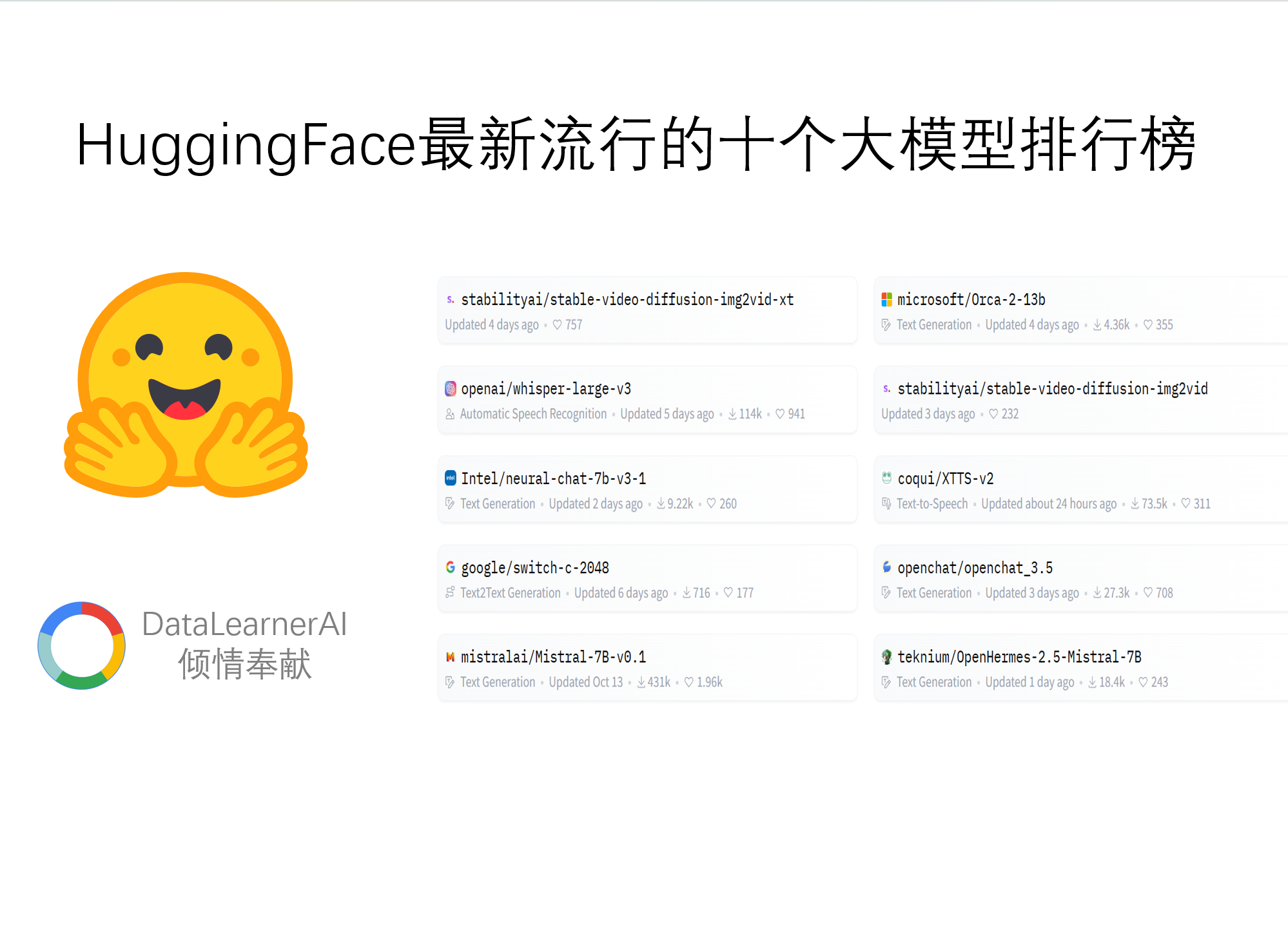
在本周,HuggingFace最流行的十个大模型多模态模型占了4个,包括StabilityAI最新开源的文本生成视频大模型Stable Video Diffusion、Coqui最新的语音合成大模型XTTS第二代等都吸引了大量的关注多。而大语言模型中,谷歌开源了2022年就已经发布的Switch大模型,该模型号称参数可以达到上万亿,也是十分有意思。
tf.nn.softmax_cross_entropy_with_logits函数

在大语言模型的训练和应用中,计算精度是一个非常重要的概念,本文将详细解释关于大语言模型中FP32、FP16等精度概念,并说明为什么大语言模型的训练通常使用FP32精度。
本笔记是来自Neural Networks and Deep Learning课程第二周作业

检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。