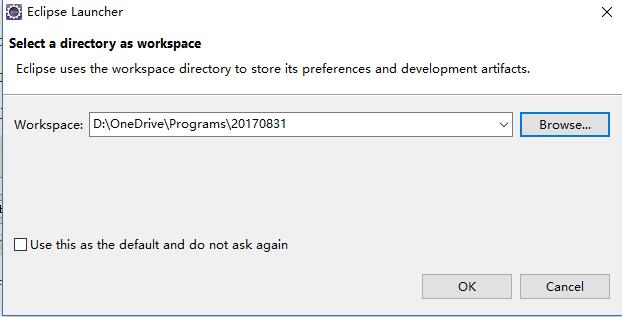
Eclipse的Web开发环境搭建——从零开始入门介绍
使用Eclipse进行Web系统开发是一种非常流行的方式。本文将讲述如何从零开始搭建Eclipse的Web开发环境。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
使用Eclipse进行Web系统开发是一种非常流行的方式。本文将讲述如何从零开始搭建Eclipse的Web开发环境。
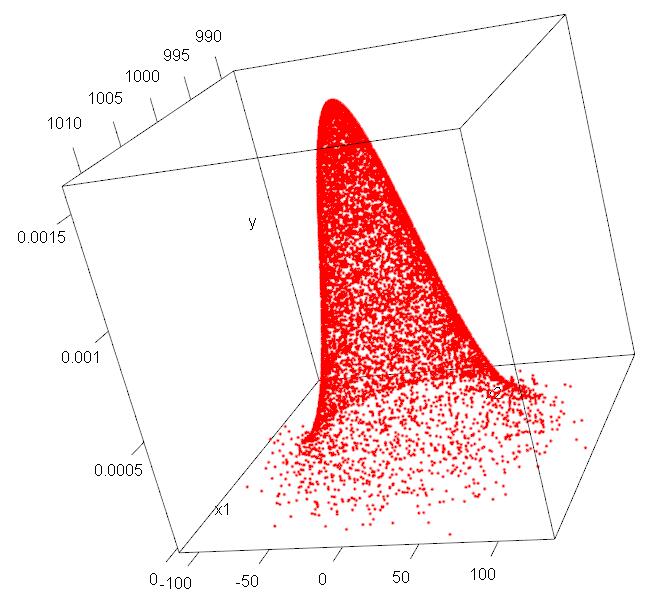
蛋疼的R语言
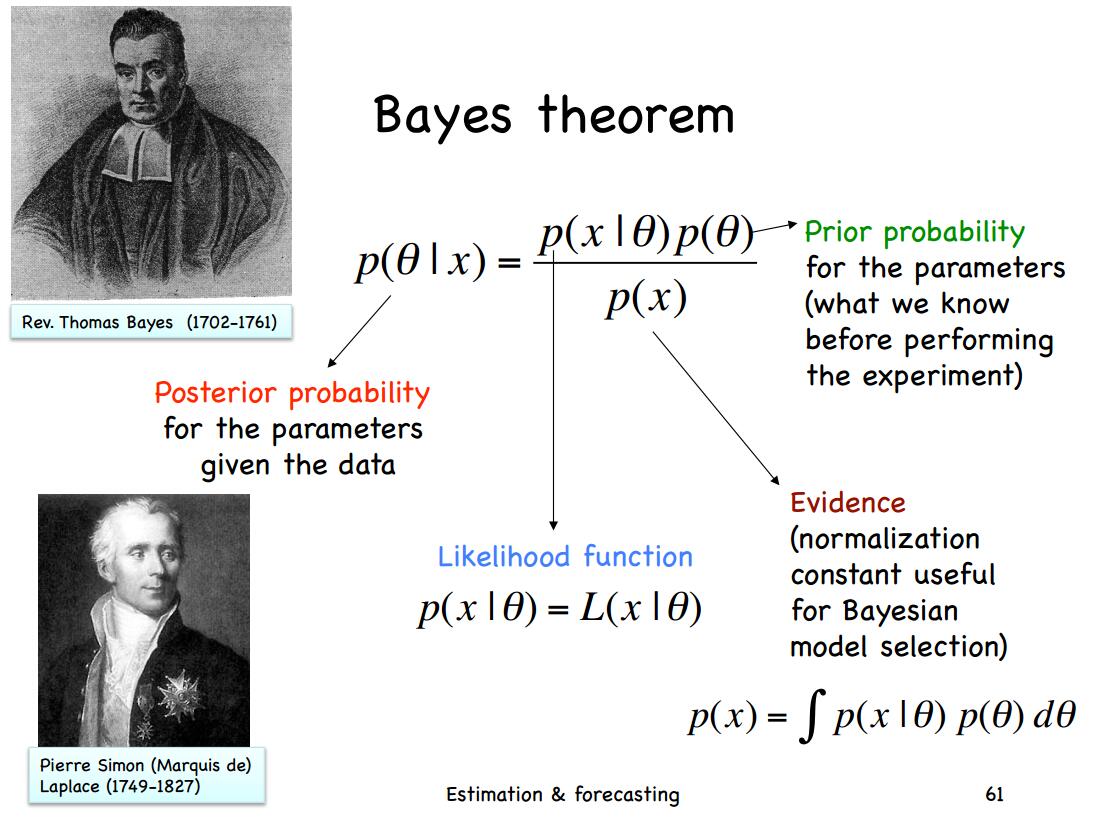
贝叶斯统计非常有用,也有一些基本的概念。这篇博客介绍了各种分布/概率的相关概念,并做了简单的介绍。

吉布斯抽样是贝叶斯推断中非常常用的方法。本文来自Cross Validated中一个人的回答。
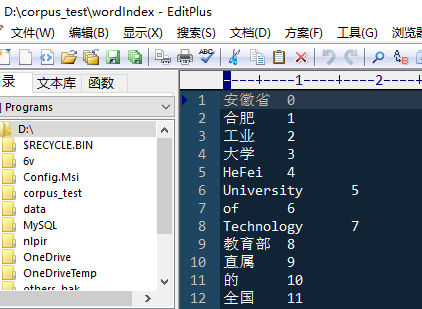
HFUTUtils是一个工具程序集合,方便我们平时处理数据。针对文本处理的内容较多。使用起来非常简单。是本人平时使用Java处理数据时候写的工具,方便数据预处理的。
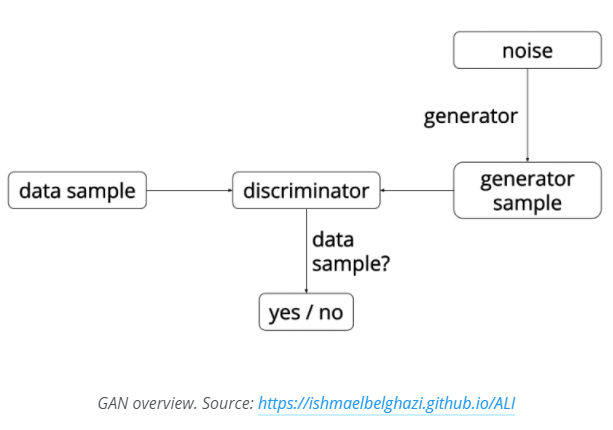
这篇博客是AYLIEN上的一篇关于生成对抗网络的简单介绍,包含非常简洁的代码示例。是入门非常好的材料。
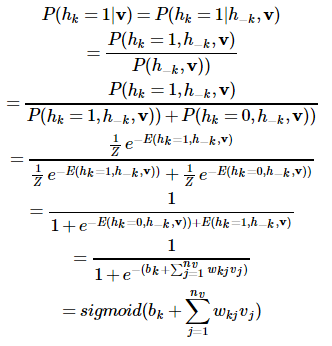
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是G.Hinton教授的一宝。Hinton教授是深度学习的开山鼻祖,也正是他在2006年的关于深度信念网络DBN的工作,以及逐层预训练的训练方法,开启了深度学习的序章。其中,DBN中在层间的预训练就采用了RBM算法模型。RBM是一种无向图模型,也是一种神经网络模型。
人工神经网络,简称神经网络,是一种模仿生物神经网络的结构和功能的数学模型或者计算模型。其实是一种与贝叶斯网络很像的一种算法。之前看过一些内容始终云里雾里,这次决定写一篇博客。弄懂这个基本原理,毕竟现在深度学习太火了。
本文转自雷锋网,原文《通过从零开始实现一个感知机模型,我学到了这些》,作者:恒亮,文章转载已获授权。感知器(英语:Perceptron)是Frank Rosenblatt在1957年就职于Cornell航空实验室(Cornell Aeronautical Laboratory)时所发明的一种人工神经网络。它可以被视为一种最简单形式的前馈神经网络,是一种二元线性分类器。本文介绍了搭建感知机模型的基本操作也包含了作者的一些心得。
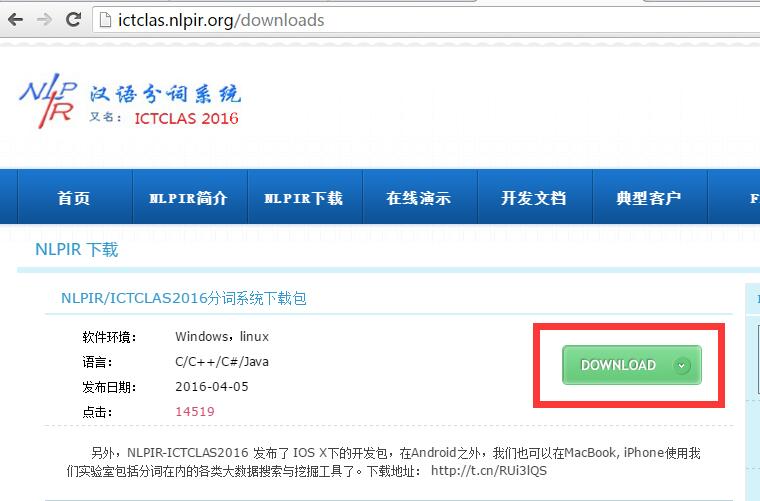
张华平汉语分词系统,现称为NLPIR汉语分词系统,是优秀的中文分词系统。但其使用却有一些配置上的设置是新手可能遇到的一个困难。这里我们简单介绍使用Eclipse导入NLPIR分词系统工程的使用方法。
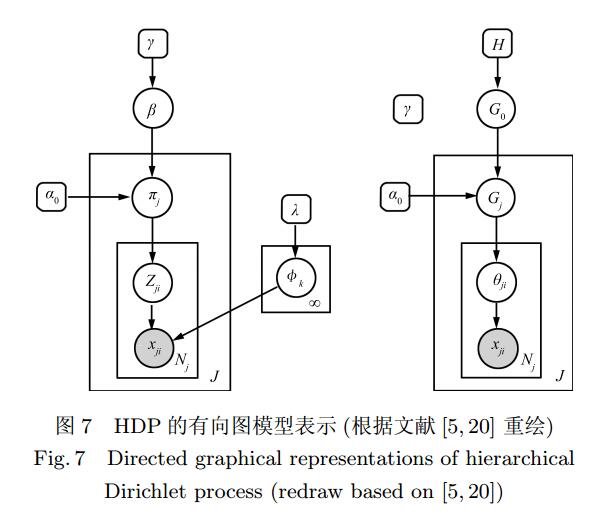
Dirichlet过程是一种重要的非参数模型,它可运用在聚类中,自动发现类别的数量。但很多时候,我们的工作都是具有层次话的。这篇文章介绍的层次狄利克雷模型就是解决这样的问题的。
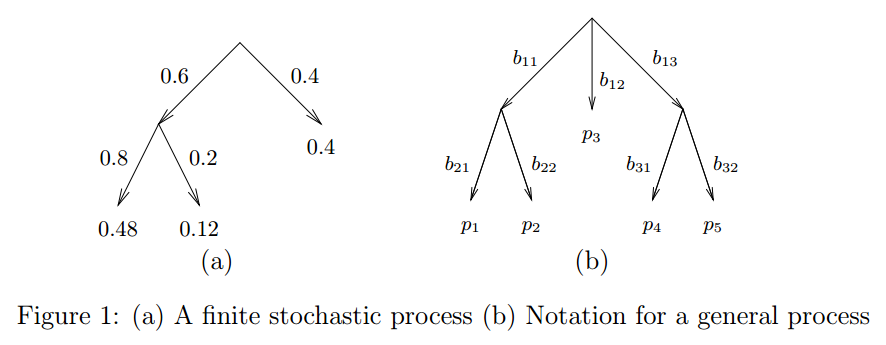
狄利克雷分布作为多项式分布的先验大家应该比较熟悉了。这里介绍另外一种Dirichlet树结构的分布,也可以作为多项式分布的先验,但却更加灵活
EM(expectation-maximization)算法是统计学中求统计模型的最大似然和最大后验参数估计的一种迭代式算法,模型一般是依赖于不可观测的潜在变量。
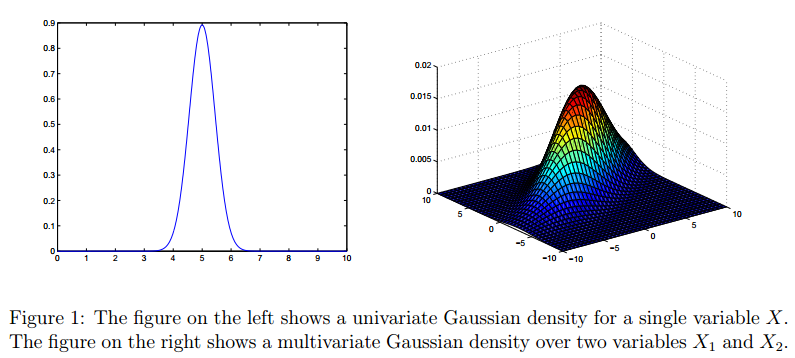
高斯分布是一种非常常见的分布,对于一元高斯分布我们比较熟悉,对于高斯分布的多元形式有很多人不太理解。这篇博客的材料主要来源Andrew Ng在斯坦福机器学习课的材料。
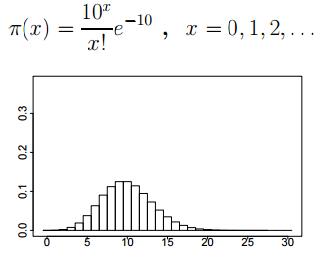
有人把Metropolis算法当作是二十世纪最伟大的十大算法之一。这个算法是大规模抽样算法的一种,也叫做马尔可夫链蒙特卡洛(Markov chain Monte Carlo,MCMC)。对于很多高维问题来说,比如计算一个凸体的体积,MCMC仿真是目前唯一可以在合理时间内解决这个问题的一般性方法。本文介绍了三种主流的MCMC算法,即MH算法、模拟退火算法和吉布斯抽样方法

仿真抽样是给予贝叶斯方法第二春的重要角色。由于很多时候实际问题很复杂,我们无法精确求出后验密度,使用仿真抽样的方法我们可以获得近似的结果。这篇博客主要介绍了几种仿真抽样的方法。
使用eclipse打包java工程并导出java包
狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)是一种非参数贝叶斯模型,它可以理解为一种聚类方法,但是不需要指定类别数量,它可以从数据中推断簇的数量。这篇博客将描述该模型及其求解过程。
这篇博客主要翻译自Gregor Heinrich的技术博客Parameter estimation for text analysis,介绍极大似然估计、极大后验估计和贝叶斯参数估计的原理和案例
贝叶斯分析在概率模型中有非常重要的作用,这些年以来比较有影响力的模型如LDA、非参数贝叶斯模型等都是基于贝叶斯分析的。贝叶斯分析有一些非常基础性的知识,在这里我们描述了贝叶斯分析里面的一些基本表示和一些分析准则等内容。

这个系列的博客来自于 Bayesian Data Analysis, Third Edition. By. Andrew Gelman. etl. 的第五章的翻译。实际中,简单的非层次模型可能并不适合层次数据:在很少的参数情况下,它们并不能准确适配大规模数据集,然而,过多的参数则可能导致过拟合的问题。相反,层次模型有足够的参数来拟合数据,同时使用总体分布将参数的依赖结构化,从而避免过拟合问题。
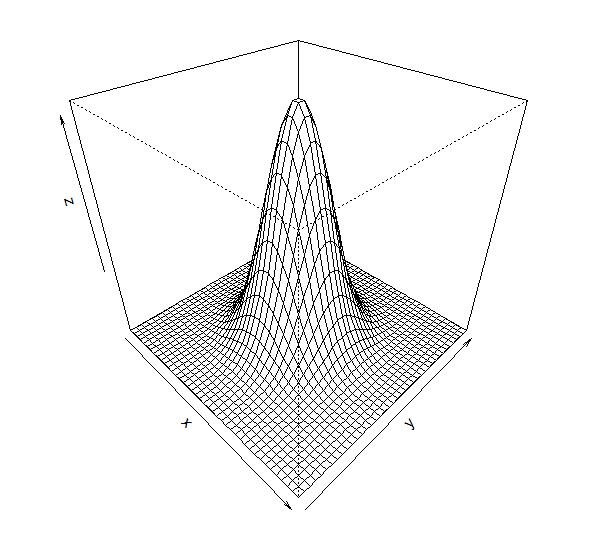
关于高斯过程,其实网上已经有很多中文博客的介绍了。但是很多中文博客排版实在是太难看了,而且很多内容介绍也不太全面,搞得有点云里雾里的。因此,我想自己发表一个相关的内容,大多数内容来自于英文维基百科和几篇文章。

我们对层次贝叶斯推断的策略与一般的多参数问题一样,但由于在实际中层次模型的参数很多,所以比较困难。在实际中,我们很难画出联合后验概率分布的图形。但是,我们可以使用近似的基于仿真的方法。 在这个部分,我们提出一个联合了分析的和数值的方法从联合后验分布p(θ, φ|y)中获取仿真结果,以 小鼠肿瘤实验的beta-binormial模型为例,总体分布是p(θ|φ),与似然函数p(y|θ)是共轭的。对于很多非共轭层次模型,更高级的算法将在后面叙述。即使针对更复杂的问题,使用共轭分布来获取近似估计也是很有用的。
这个系列的博客来自于 Bayesian Data Analysis, Third Edition. By. Andrew Gelman. etl. 的第五章的翻译。实际中,简单的非层次模型可能并不适合层次数据:在很少的参数情况下,它们并不能准确适配大规 模数据集,然而,过多的参数则可能导致过拟合的问题。相反,层次模型有足够的参数来拟合数据,同 时使用总体分布将参数的依赖结构化,从而避免过拟合问题。本节将讲述互换性并建立层次模型