深度学习技巧之Batch Normalization
一、概念简介
Batch Normalization是深度学习中最重要的技巧之一。是由Sergey Ioffe和Christian Szeged创建的。Batch Normalization使超参数的搜索更加快速便捷,也使得神经网络鲁棒性更好。
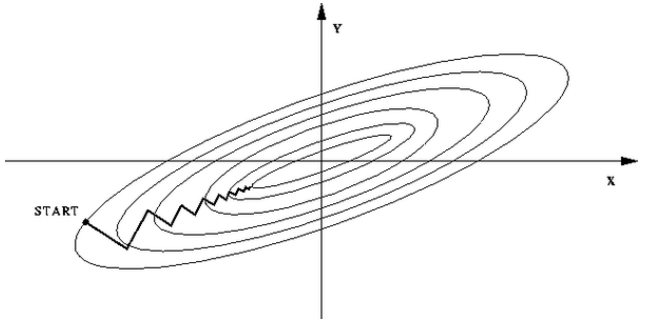
一般来说,在训练类似逻辑回归或者深度学习的算法的时候,我们需要对输入数据进行标准化,这样可以保证输入的数据均值为0,且输入数据都在一定范围内,这样做主要原因是非标准化的数据优化的时候目标函数是一个扁平的结果,会影响学习的速度,而标准化之后的目标函数是接近圆形的结果,对于梯度下降求解来说能显著加快找到最优值的速度。如下图所示:

既然如此,那么对于深度神经网络来说,我们是否可以对每一层的输出也做一个标准化,作为下一层的输入以此来加快求解速度呢?答案是可以的,这就是Batch Normalizing。
二、详细说明
这里有一个问题,对于第$l$层来说,其输入是$a^{[l-1]}$,参数是$w^{[l]}$和$b^{[l]}$,前向传播的计算如下:,即:
z^{[l]} = w^{[l]}a^{[l-1]} + b^{[l]}
a^{[l]} = g(z^{[l]})
那么BatchNormalizing是运用在求激活函数之前的$z^{[l]}$上,还是用在求得激活函数之后的$a^{[l]}$上呢?这个没有定论,但是实际中用在激活函数之前的$z^{[l]}$上比较多。
那么,Batch Norm的实现如下。给定某些中间值$z^{(1)},\cdots,z^{(m)}$,有:
\mu = \frac{1}{m} \sum_{i}z^{(i)}
\sigma^2 = \frac{1}{m} \sum_{i}(z^{(i)}-\mu)^2
那么标准化之后的值:
z_{norm}^{(i)} = \frac{z^{(i)}-\mu}{\sqrt{\sigma^2+\epsilon}}
这里在分母加了一个$\epsilon$的原因是防止分母出现0的情况。这个值是一个很小的值,一般不影响结果。这个时候,转换后的数值均值是0,方差是1。但是实际上,我们并不希望神经元总是这样的分布。使用另一种不同的分布是比较合理的,所以一般情况下,我们还会做如下一步计算:
\tilde{z}^{(i)} = \gamma \cdot z_{norm}^{(i)}+ \beta
这里的$\gamma$和$\beta$都是可以学习的参数。因此,和神经网络的其他参数如权重$w$和偏差$b$一样,可以使用梯度下降来学习。注意,这里的$\gamma$和$\beta$的作用是可以让你把$\tilde{z}^{(i)}$的均值设置成任意你想要的结果,因此,如果有如下设置:
\gamma = \sqrt{\sigma^2 + \epsilon}
\beta = \mu
那么实际上你就把上述公式翻转了,导致$\tilde{z}^{(i)} = z^{(i)}$。实际上应该是没啥效果的。
注意,与输入参数的标准化不同的是,这里我们期望隐藏层单元的输出的均值不是0,方差不是1,而是根据激活函数来的。例如,如果你使用了sigmoid激活函数,那么你肯定不希望你的数值都集中在0左右的范围内,你希望你的数值有更大的方差,或者是在均值不为0的范围内以更好地利用sigmoid函数的非线性的优点。而不是数据指在0左右的一点范围内,因为那个范围内的sigmoid结果是个接近线性的结果。这就是使用$\gamma$和$\beta$来调整你的标准化范围的作用。

注意,正常情况下:
z^{[l]} = w^{[l]}a^{[l-1]} + b^{[l]}
其中$b^{[l]}$是一个常数,加不加这个常数并不会影响归一化的结果,同时后面我们使用$\beta$和$\gamma$来控制最终的标准化的均值和反差,因此也可以省去。因此,如果在深度学习中使用了Batch Normalizing,那么它的中间值$z$的计算就变成了:
z = wx
后面的参数b就可以全部去掉。计算的时候也少了一个参数了。但是多了$\gamma$和$\beta$。
三、为什么Batch Normalizing起作用
首先是和输入数据类似,可以使目标函数变成圆形,便于梯度下降算法求解最优解 第二个原因是在图像识别中,如果你的训练集用的是黑白图像,测试集如果是彩色的,那依然是无法识别的。也就是说,一旦输入数据X变了,那么网络必须重新训练,这种问题叫协变量问题(Covariate problem),在深度学习中,每一层的输入都是上一层的输出,因此,一旦上一层的输出变了,那么也会影响一下层的训练参数。使用了BN之后,虽然上一层的输出也会变化,但是起码还是在一定范围内,因为他们的均值和方差依然在我们的范围中,这样会减少变化,加快训练速度。 还有一点是,BN有点正则的作用。在mini-batch的训练中,归一化都是以这个某一个mini-batch为基准计算的,因此与真实的全体数据相比较,这里其实是有噪音的。与dropout类似,对每个神经元加了噪音之后可以缓解过拟合的问题。但是这只是很小的影响,所以可以和dropout一起来作用于深度学习上。因此,如果mini-batch设置大一点,也可以降低这种噪音的影响。需要注意的是一般我们也不会把BN当做正则化使用,但是它会对结果产生一些预料不到的影响,所以要注意。
四、如何在测试集中运用BN
训练集通常使用min-batch来训练,但很多时候测试集预测的测试的时候但是每次只处理一条数据,这个时候要做BN会导致没有作用。也就是说那个均值和方差与自己一样。有很多方法处理问题。例如可以计算全局数据的均值方差,来做测试集的BN参数。还有个方法是记录训练过程中每一层的均值和方差,然后使用weight average方法来把所有的均值和方差引入到测试集中。最后计算。
