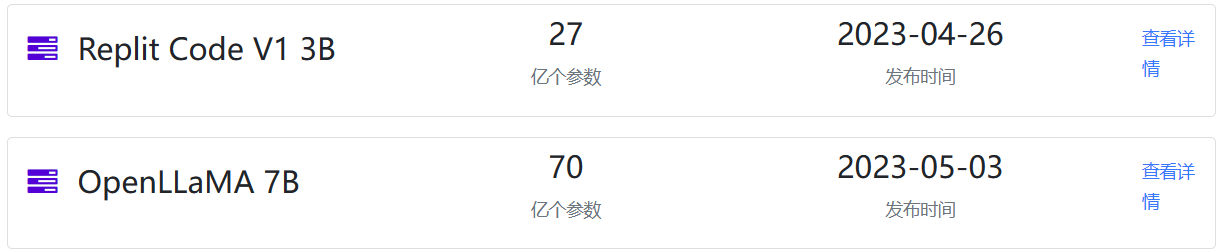
5月3日,2个重磅开源的AI模型发布:Replit代码补全大模型和LLaMA复刻版OpenLLaMA发布
五一长假最后一天,AI技术的发展依然火热。今天有2个重磅的开源模型发布:一个是前几天提到的Replit的代码补全大模型Replit Code V1 3B,一个是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
五一长假最后一天,AI技术的发展依然火热。今天有2个重磅的开源模型发布:一个是前几天提到的Replit的代码补全大模型Replit Code V1 3B,一个是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。

随着NLP预训练模型的发展,大语言模型在各个领域的作用也越来越大。几个月前,GitHub基于OpenAI的GPT-3训练的Copilot效果十分惊艳,可惜现在已经开始收费。而最近,清华大学也发布了一个代码补全神器——CodeGeeX。
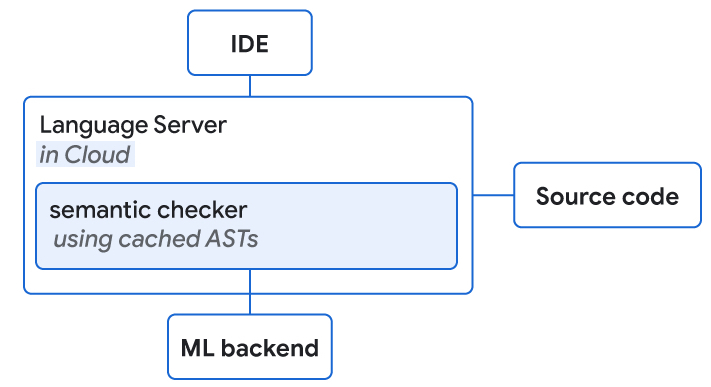
我们将介绍如何将ML和SE结合起来,开发一种新的基于Transformer的混合语义ML代码补全,现在可供内部谷歌开发人员使用。我们讨论了如何通过(1)使用ML对SE单标记建议重新排序,(2)使用ML应用单行和多行补全并使用SE检查正确性,或(3)使用单标记语义建议的ML的单行和多行延拓来组合ML和SE。