
2021年适合初学者的10个最佳机器学习在线课程
机器学习是这几年很热门的学习和工作的方向。但是机器学习相关算法的入门却并不容易。本文参考自MLTUT的博文,列举了2021年适合初学者的十个最佳机器学习网络课程供大家学习参考。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
机器学习是这几年很热门的学习和工作的方向。但是机器学习相关算法的入门却并不容易。本文参考自MLTUT的博文,列举了2021年适合初学者的十个最佳机器学习网络课程供大家学习参考。

去年5月份的时候,Python创始人Guido van Rossum在参加Language Summit时候说他希望Python3.11能在性能上获得巨大的提升,可以实现性能翻倍。目前看,似乎已经有了很大的希望!

前几天,北京智源人工智能研究院引入了一个名为WuDaoMM的大规模多模态语料库,总共包含超过6.5亿对图像-文本。具体来说,约有6亿对数据是从图像和标题呈现弱相关的多个网页中收集的,另外5000万对强相关的图像-文本是从一些高质量的图片网站中收集的。
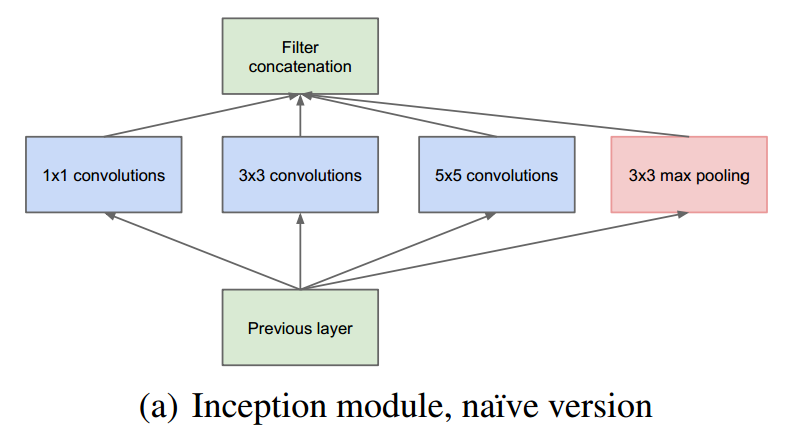
GoogLeNet是谷歌在2014年提出的一种CNN深度学习方法,它赢得了2014年ILSVRC的冠军,其错误率要低于当时的VGGNet。与之前的深度学习网络思路不同,之前的CNN网络的主要目标还是加深网络的深度,而GoogLeNet则提出了一种新的结构,称之为inception。GoogLeNet利用inception结构组成了一个22层的巨大的网络,但是其参数却比之前的如AlexNet网络低很多。是一种非常优秀的CNN结构。
本文介绍了文本领域的相关任务和技术,探讨了循环神经网络在文本领域的优势,并进一步研究了应用在文本领域的卷积网络方法,原文地址:https://medium.com/@TalPerry/convolutional-methods-for-text-d5260fd5675f
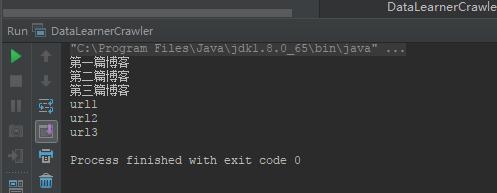
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。在这篇博客里,我们将简单介绍Jsoup解析HTML页面的操作。
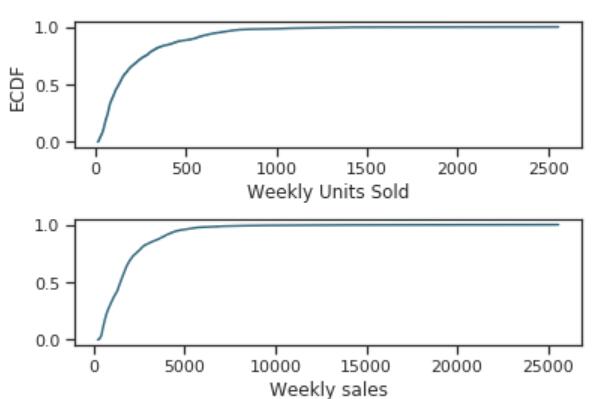
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。
蛋疼的R语言
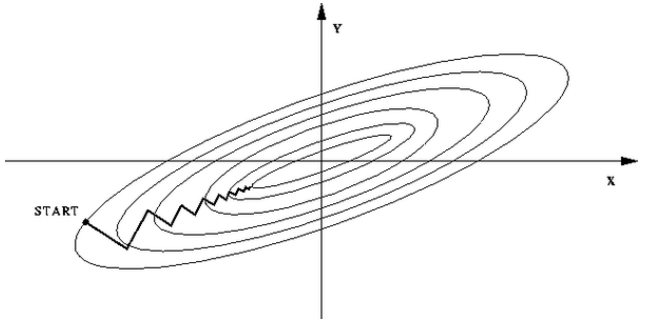
Batch Normalization是深度学习中最重要的技巧之一。是由Sergey Ioffe和Christian Szeged创建的。Batch Normalization使超参数的搜索更加快速便捷,也使得神经网络鲁棒性更好。本篇博客将简要介绍相关概念和原理。
Dirichlet Process and Stick-Breaking(DP的Stick-breaking 构造)

当前大模型本质是一种大语言模型(Large Language Models, LLM),其核心能力是对语言的处理。良好的意图识别和文本生成能力让LLM超越了之前的模型,有了巨大的实用价值。但是,现实问题涉及了很多超越语言模型之外的能力,如基于最新数据的文本摘要、向用户提供实时数据分析和可视化结果、为代码提供debugging等。目前,让LLM解决这些问题的一个最有前景的方向就是建立大模型驱动的自动代理。也就是让LLM作为核心控制者来学会使用不同工具,进而完成最终任务。
本篇博客主要讲解如何从给定参数的的正态分布/均匀分布中生成随机数以及如何以给定概率从数字列表抽取某数字或从区间列表的某一区间内生成随机数,按照内容将博客分为3部分,并附上代码。

Intent是Android中通信的组件。这篇博客将详细讲述什么是Intent及其用法。
使用Tensorflow的高级API - tf.contrib.learn 搭建一个DNN分类器

随着NLP预训练模型的发展,大语言模型在各个领域的作用也越来越大。几个月前,GitHub基于OpenAI的GPT-3训练的Copilot效果十分惊艳,可惜现在已经开始收费。而最近,清华大学也发布了一个代码补全神器——CodeGeeX。
基于项目最近邻的协同过滤算法,面向的是隐偏好数据,数据格式为
Dask提供了多种分布式调度器,当缺少多台服务器时候,也可以通过本地集群来实现单机分布式的计算。这篇博客主要就是介绍如何实现Dask的单机分布式调度器。第一小节是简介,第二节是单机调度器的简写版本,第三节是单机调度器的完整版本,第四节是使用的一些示例。

OpenAI的o1模型是当前最强大的具有超强推理能力的大语言模型。但是,o1模型本身的能力如何,o1版本和o1-mini版本模型的差异在哪等似乎都很不清晰。为此,OpenAI在Twitter上举办了一次AMA(Ask me anything)活动,解答了很多大家关心的问题。在这篇博客中,我们根据这个讨论结果总结了一下其中比较重要的信息供大家参考。
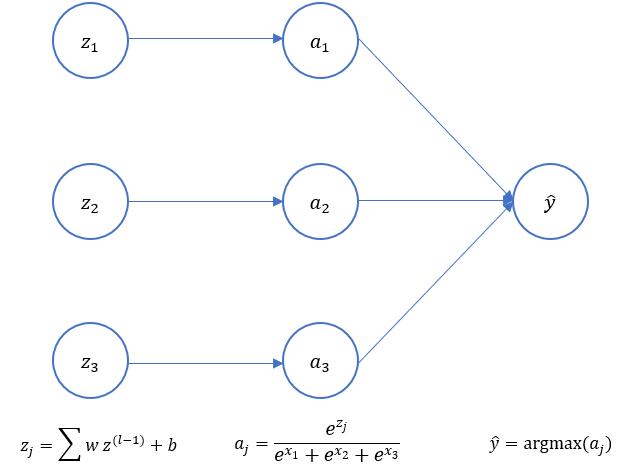
softmax作为多标签分类中最常用的激活函数,常常作为最后一层存在,并经常和交叉熵损失函数一起搭配使用。这里描述如何推导交叉熵损失函数的推导问题。

平衡二叉树(Balanced Binary Tree)是二叉树(Binary Tree)中最重要的一种树结构。由于它保证了一个良好的二叉树形结构,使得其查找、搜索和删除等操作的效率大大提高,是应用最广泛的二叉树。
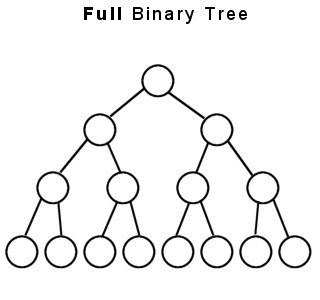
二叉树数据结构中一类重要的数据结构,也是树表家族最为基础的结构。二叉树每个节点最多具有两个子节点。本篇博客将简述二叉树原理和应用。