
标签平滑(Label Smoothing)——分类问题中错误标注的一种解决方法
在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,可以提高模型效果。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,可以提高模型效果。

倾向值分析;stata; propensity score matching using stata
多元正态(高斯)分布分布是我们最常用的分布之一,这篇博客的主要内容来自Will Penny的文章的翻译。主要讲述关于多元正态分布的贝叶斯推导
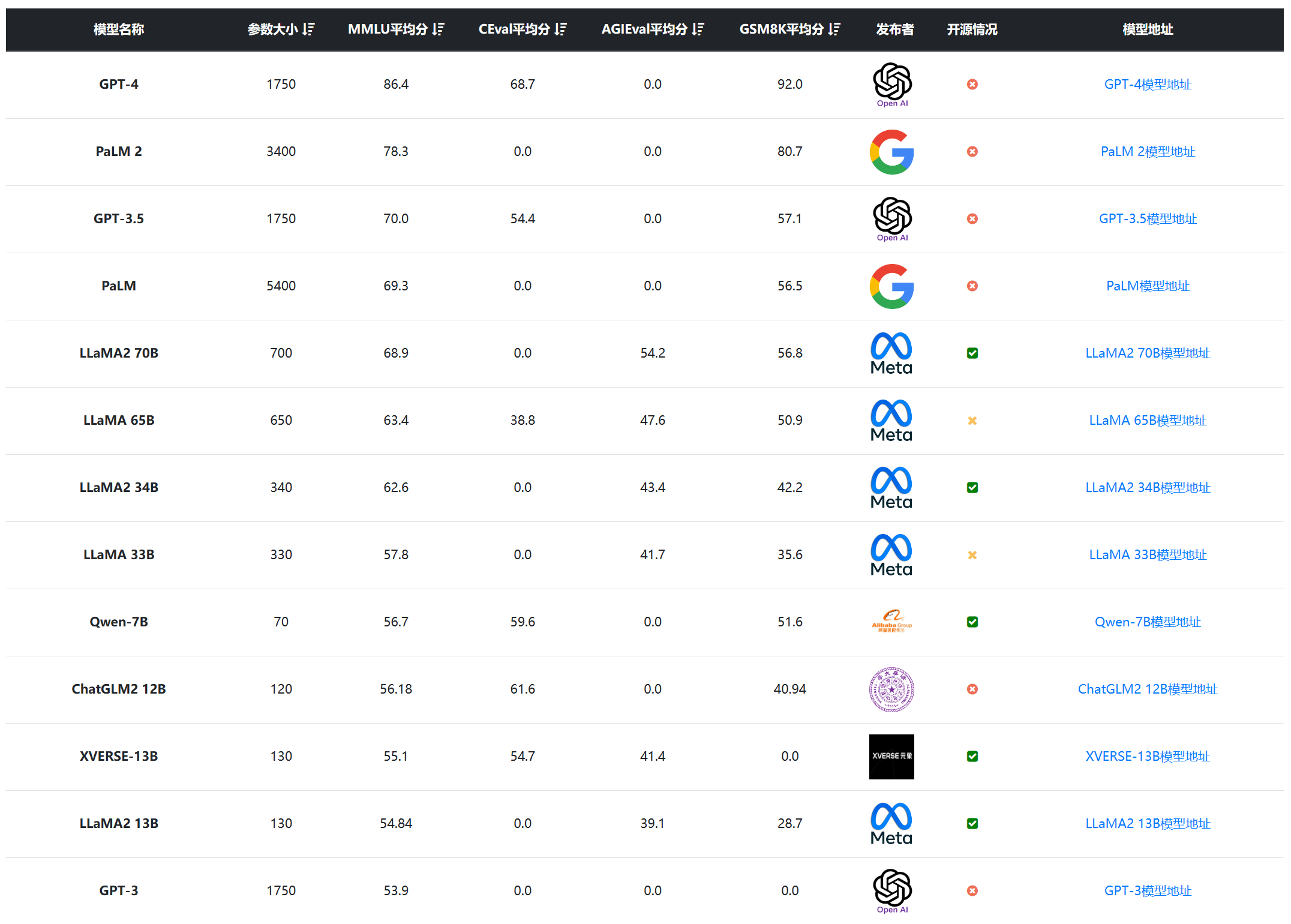
随着各种AI模型的快速发展,选择合适的模型成为了研究和开发的一大挑战。最近一段时间,国产模型不断涌现,让人应接不暇。尽管开源的繁荣提供了更多的选择,实际上也造成了选型的困难,尽管业界提供了很多评测基准,但是,**很多模型在公布的评测结果中对比的模型基准和选择的测试基准都很少,甚至只选择对自己有利的结果**。为了更加方便大家对比相关的结果,DataLearner上线了大模型评测综合排行对比表,给大家提供一个更加清晰的对比结果。我们主要关注的是国内开源大模型和一些全球主流模型的对比结果。
很多童鞋在查询期刊的时候会发现某些期刊不是SCI(SCIE)索引,而是一个叫ESCI的索引。这似乎有点像SCI,但好像又有区别,所以大家会有疑问,本篇博客将解释二者的区别。

Hugging Face是一家非常活跃的人工智能创业公司。它拥有一个非常强大并且活跃的人工智能社区。有超过5000多家机构都在Hugging Face的社区发布内容,包括Google AI、Facebook AI、微软等。自从2016年成立以来,这家企业经历了5轮融资,总共募集了6000万美金。本文将简要介绍这家企业相关的信息。

当前的大语言模型主要是预训练大模型,在大规模无监督数据上训练之后,再经过有监督微调和对齐之后就可以完成很多任务。尽管如此,面对垂直领域的应用,大模型依然需要微调才能获得更好地应用结果。而大模型的微调有很多方式,包括指令微调、有监督微调、提示工程等。其中,指令微调(Instruction Tuning)作为改进模型可控性最重要的一类方法,缺少深入的研究。浙江大学研究人员联合Shannon AI等单位发布了一篇最新的关于指令微调的综述,详细描述指令微调的各方面内容。
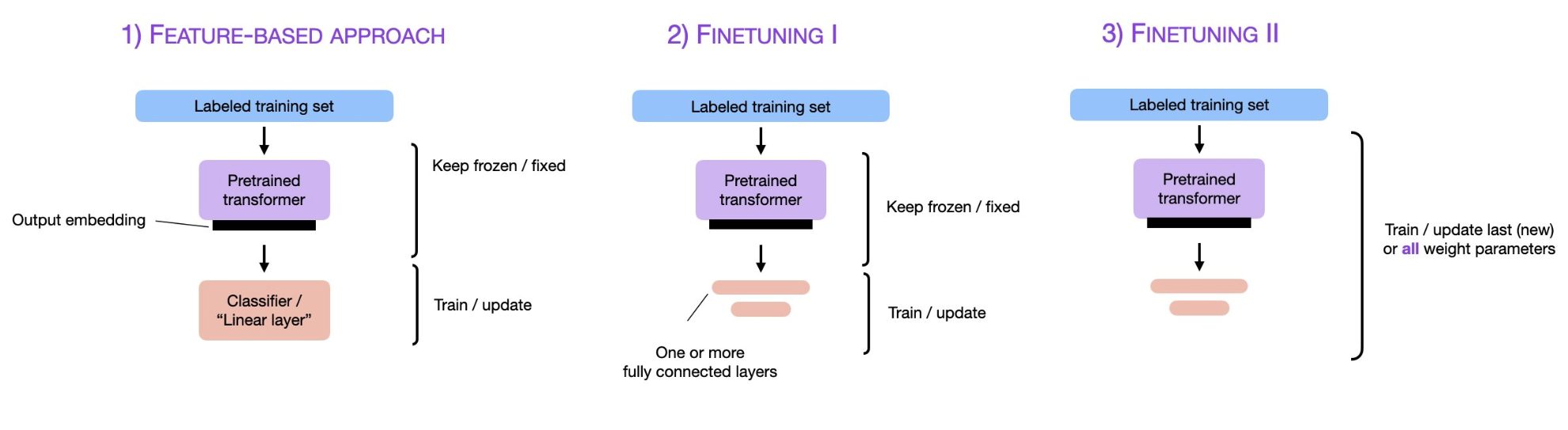
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。

深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。
神秘的numpy.argpartition

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。
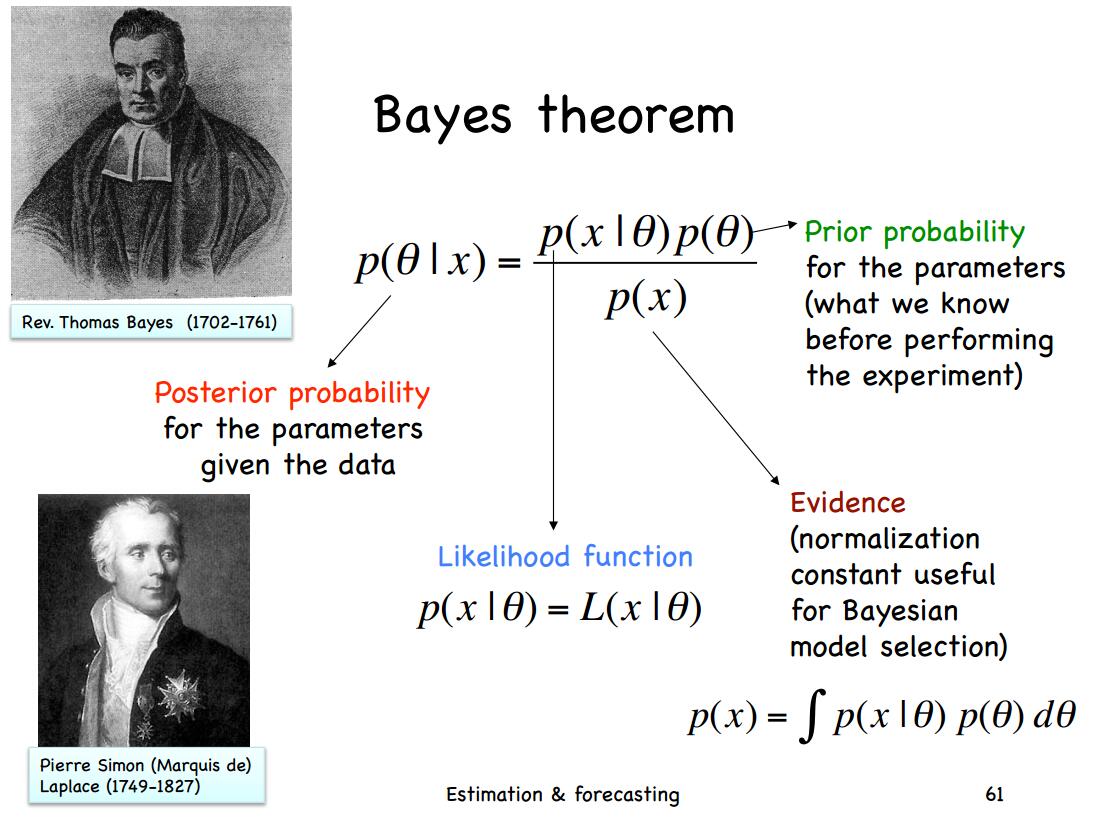
贝叶斯统计非常有用,也有一些基本的概念。这篇博客介绍了各种分布/概率的相关概念,并做了简单的介绍。

Tensorflow中tf.data.Dataset是最常用的数据集类,我们也使用这个类做转换数据、迭代数据等操作。本篇博客将简要描述这个类的使用方法。
KKT条件(Karush–Kuhn–Tucker conditions)是求解带不等式约束的最优化问题中非常重要的一个概念和方法。这篇博客将解释相关概念和操作。
multi-class classification problem和 multi-label classification problem在keras上的实现
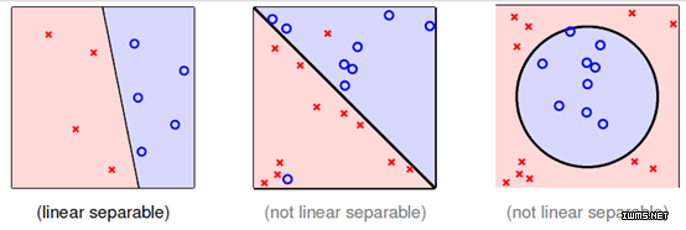
在机器学习或者深度学习中,正则项是我们经常遇到的概念。它对提高模型的准确性和泛化能力非常重要。本文详细描述了正则项的来源以及与其他概念的相关关系。
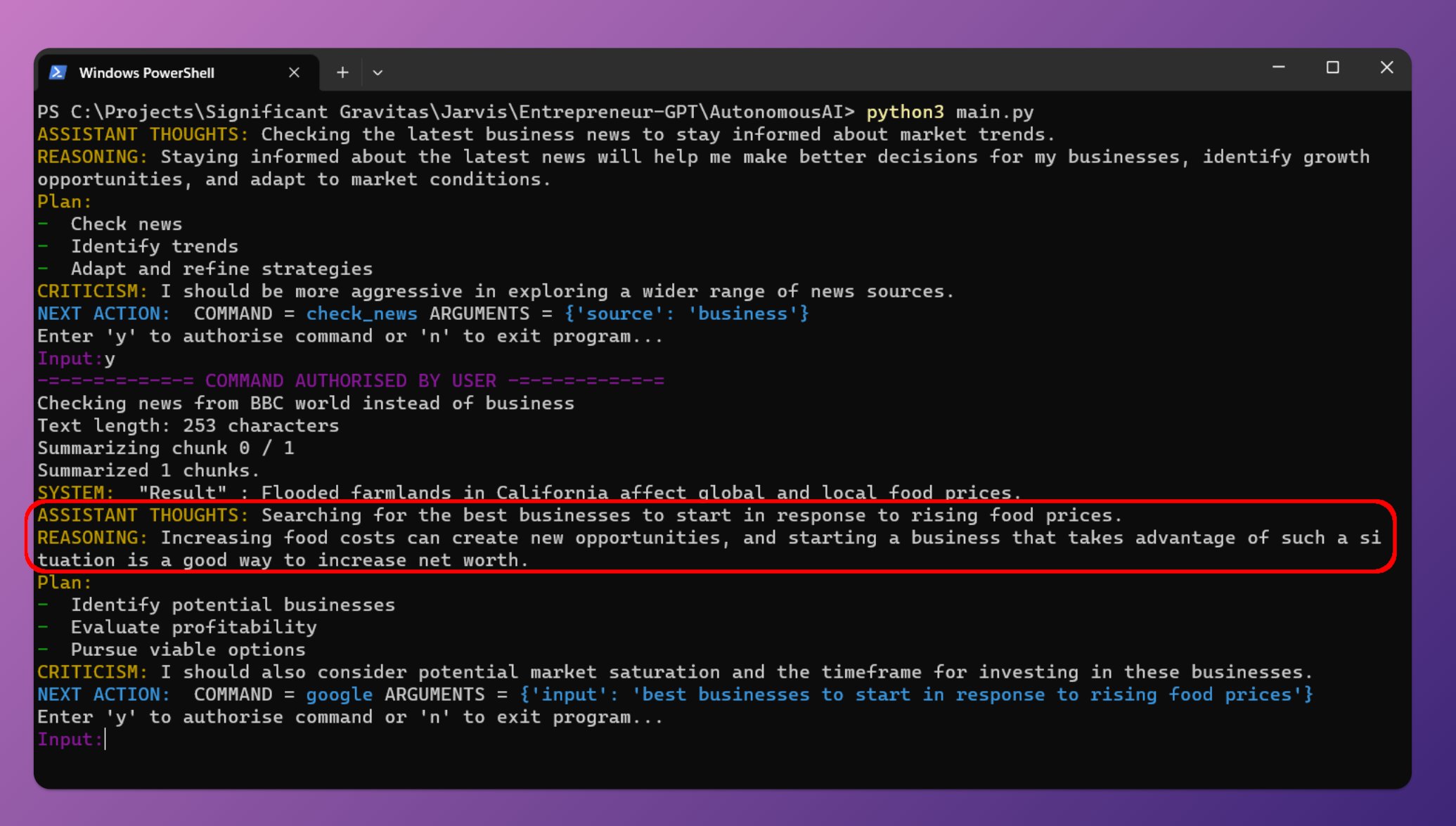
最近几天AutoGPT十分火热,这是由开发者Significant Gravitas推出的项目。该项目可以根据你设置的目标,使用GPT-4自动帮你完成所有的任务。你只要提供OpenAI的API Key,保证里面有钱,那么它就可以根据你设定的目标,采用Google搜索、浏览网站、执行脚本等方式帮你完成目标。
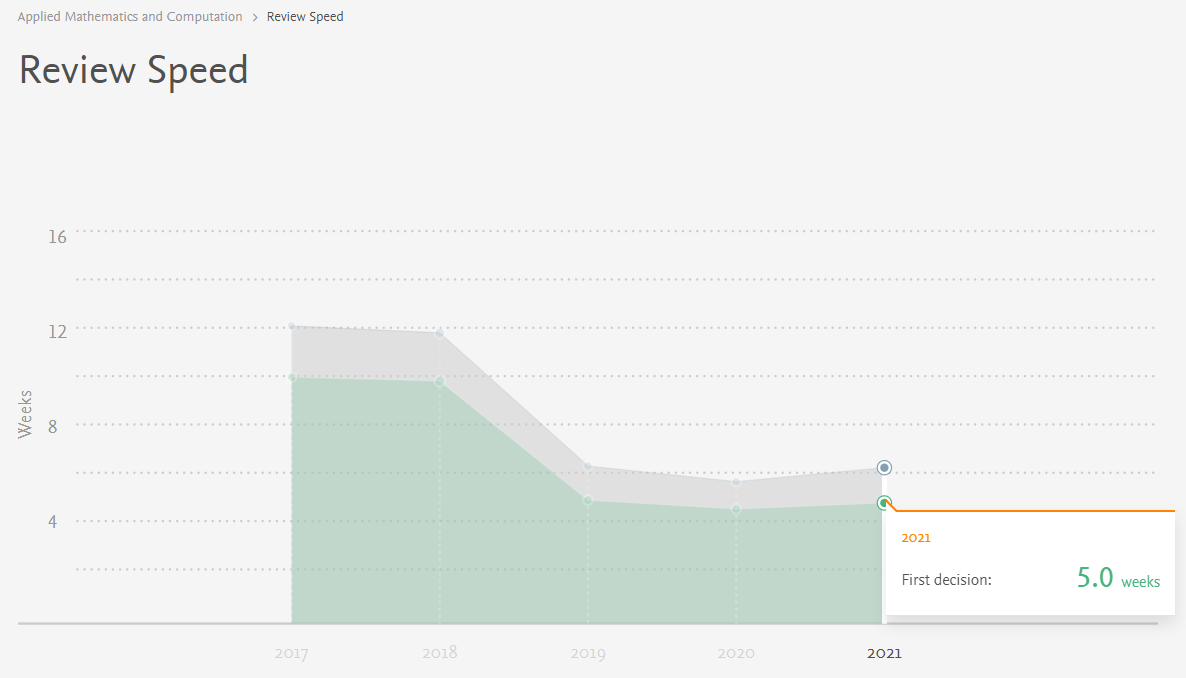
科研成果发表速度对于国内的硕士生和博士生来说非常重要,它涉及了同学们的毕业、出国和奖学金等。很多童鞋在投稿之前都希望了解期刊的审稿周期。虽然大多数期刊没有规定明确的审稿时间,但是,随着大家对学术期刊投稿周期的关注,很多学术期刊也开始就自己的审稿速度开始有所要求,本文针对常见的期刊审稿周期提供一个普遍的分析方法。
文本预处理是一件极其耗费时间的事情,不仅繁琐而且涉及的细节很多,处理不好对后面的事情的影响很大。本文将简要介绍文本预处理的一般步骤和方法。
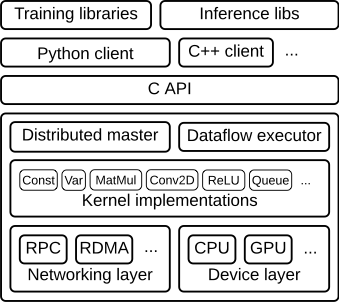
随着深度学习的火热,对计算机算力的要求越来越高。从2012年AlexNet以来,人们越来越多开始使用GPU加速深度学习的计算。 然而,一些传统的机器学习方法对GPU的利用却很少,这浪费了很多的资源和探索的可能。在这里,我们介绍一个非常优秀的项目——RAPIDS,这是一个致力于将GPU加速带给传统算法的项目,并且提供了与Pandas和scikit-learn一致的用法和体验,非常值得大家尝试。
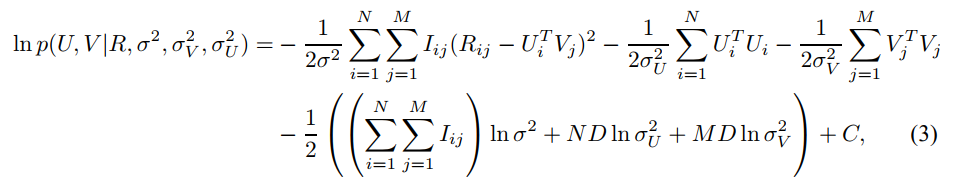
本篇博客详细说明了概率矩阵分解(Probabilistic Matrix Factorization,PMF)的推导过程
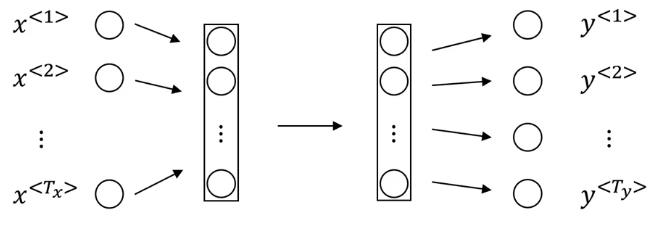
序列数据是生活中很常见的一种数据,如一句话、一段时间某个广告位的流量、一连串运动视频的截图等。在这些数据中也有着很多数据挖掘的需求。RNN就是解决这类问题的一种深度学习方法。其全称是Recurrent Neural Networks,中文是递归神经网络。主要解决序列数据的数据挖掘问题。
深度学习是目前最火的算法领域。他在诸多任务中取得的骄人成绩使得其进化越来越好。本文收集深度学习中的经典算法,以及相关的解释和代码实现。