
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



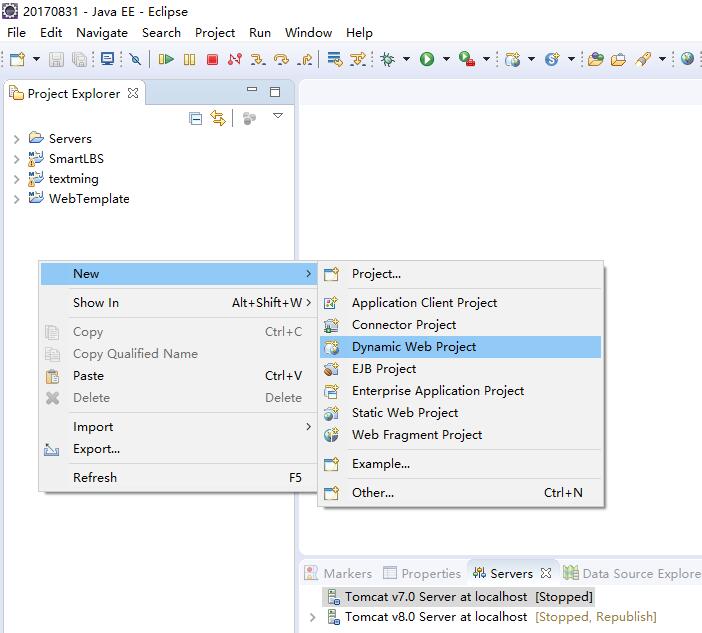
使用SpringMVC框架搭建Web项目工程是目前非常流行的web项目创建方式。同时Spring Security也为我们提供了登录验证和权限控制等内容。

在大语言模型的训练和应用中,计算精度是一个非常重要的概念,本文将详细解释关于大语言模型中FP32、FP16等精度概念,并说明为什么大语言模型的训练通常使用FP32精度。


DALLE·2的出现,让大家认识到原来文本生成图片可以做到如此逼真效果,此后Stable Diffusion的开源也让大家把Text-to-Image玩出花了。而现在,Meta AI的研究人员让这个工作继续往前一步,发布了Text-to-Video的预训练模型:Make-A-Video。
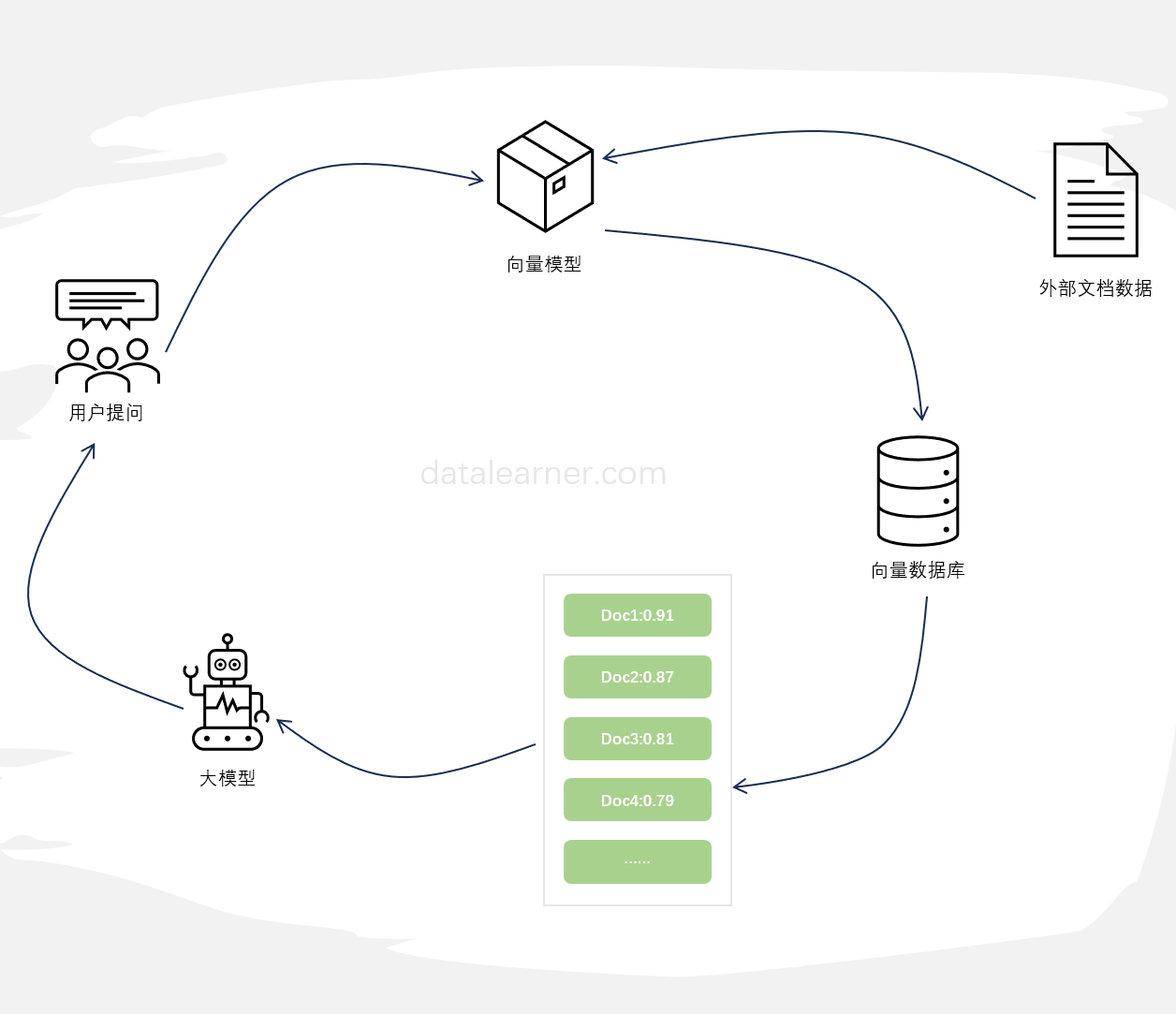
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。
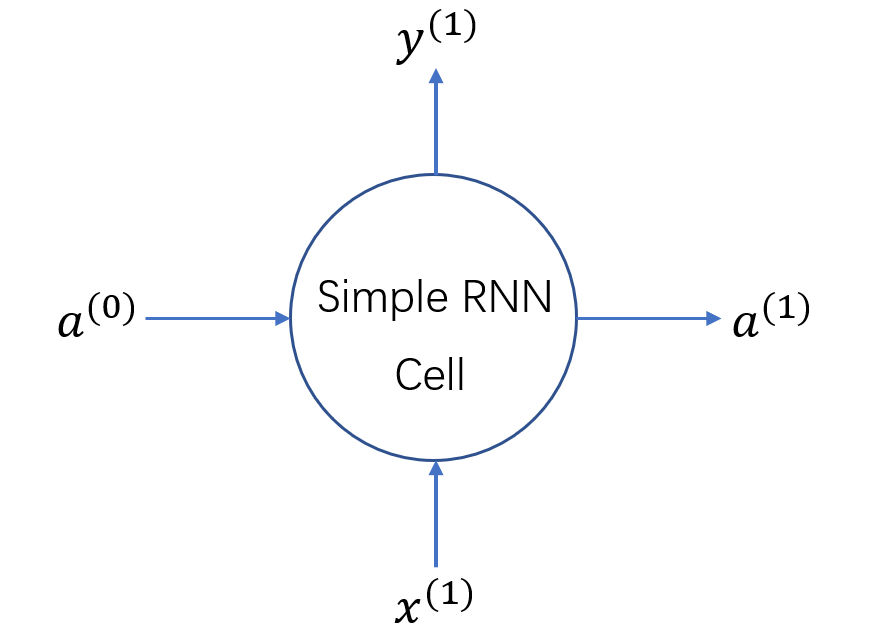
RNN的应用有很多,尤其是两个RNN组成的Seq2Seq结构,在时序预测、自然语言处理等方面有很大的用处,而每个RNN中一个节点是一个Cell,它是RNN中的基本结构。本文从如何使用RNN建模数据开始,重点解释RNN中Cell的结构,以及Keras中Cell相关的输入输出及其维度。我已经尽量解释了每个变量,但可能也有忽略,因此可能对RNN之前有一定了解的人会更友好,本文最主要的目的是描述Keras中RNNcell的参数以及输入输出的两个注意点。如有问题也欢迎指出,我会进行修改。
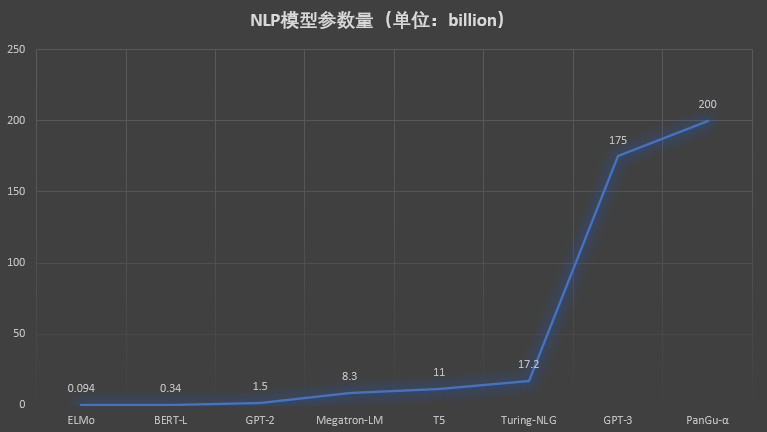
这几年深度学习的发展给人工智能相关应用的落地带来了很大的促进。随着NLP、CV相关领域的算法的发展,算法层面的创新已经逐渐慢了下来,但是工程方面的研究依然非常火热。从底层的硬件的创新,到平台框架的发展,为支撑超大规模模型训练与移动端小规模算法推断而创造的软硬件体系也在飞速革新。本文将总结深度学习平台框架软件及下层的硬件支撑系统。

检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。

随着预训练大模型技术的发展,基于prompt方式对模型进行微调获得模型输出已经是一种非常普遍的大模型使用方法。但是,对于同一个问题,使用不同的prompt也会获得不同的结果。为了获得更好的模型输出,对prompt进行调整,学习prompt工程技巧是一种必备的技能。

NumPy是Python中非常优秀的一个数据科学工具包,使用Python做数据分析的童鞋几乎是必备的工具。NumPy的提供了非常丰富的计算能力,但是底层是C语言实现的,因此既有Python语法的低门槛,速度上却依然非常好。NumPy本身也和Pandas、SciPy一起成为一种生态了。今天,NumPy发布了1.20.0最新版本,这个版本的改动很大。值得童鞋们关注~