
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




有的时候使用Python遇到内存溢出的问题,但其实机器剩余内存很多。需要注意Python版本是否正确
今天阿里巴巴开源了他们家第二代的Qwen系列大语言模型(准确说是1.5代),从官方给出的测评结果看,Qwen1.5系列大模型相比较第一代有非常明显的进步,其中720亿参数规模版本的Qwen1.5-72B-Chat在各项评测结果中都非常接近GPT-4的模型,在MT-Bench的得分中甚至超过了此前最为神秘但最接近GPT-4水平的Mistral-Medium模型。

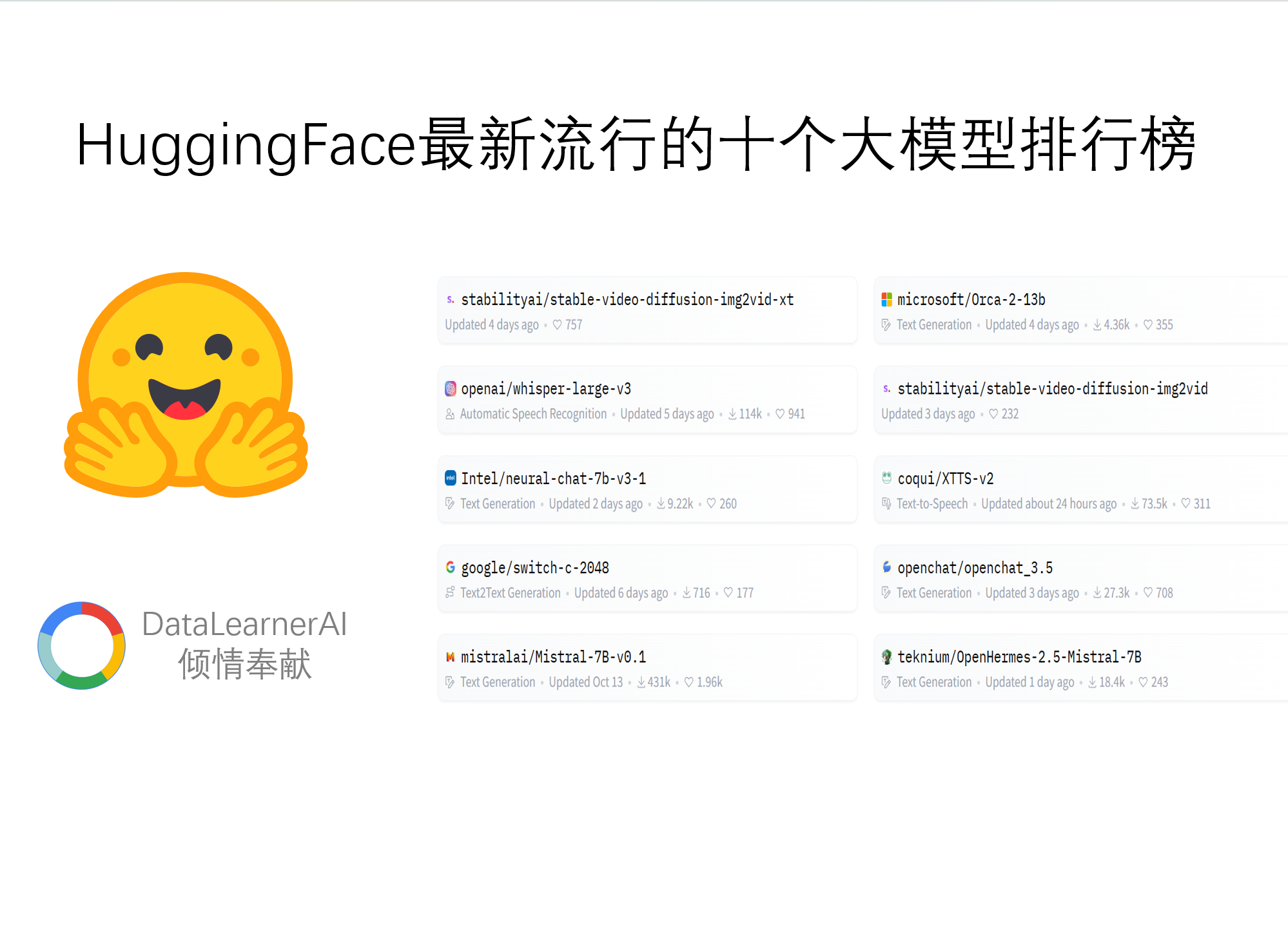
在本周,HuggingFace最流行的十个大模型多模态模型占了4个,包括StabilityAI最新开源的文本生成视频大模型Stable Video Diffusion、Coqui最新的语音合成大模型XTTS第二代等都吸引了大量的关注多。而大语言模型中,谷歌开源了2022年就已经发布的Switch大模型,该模型号称参数可以达到上万亿,也是十分有意思。

随着ChatGPT的火爆,Prompts概念开始被大家所熟知。早期类似如BERT模型的微调都是通过有监督学习的方式进行。但是随着模型越来越大,冻结大部分参数,根据下游任务做微调对模型的影响越来越小。大家开始发现,让下游任务适应预训练模型的训练结果有更好的性能。而ChatGPT的火爆让大家知道,虽然ChatGPT的能力很强,但是需要很好的提问方式才能让它为你所服务。
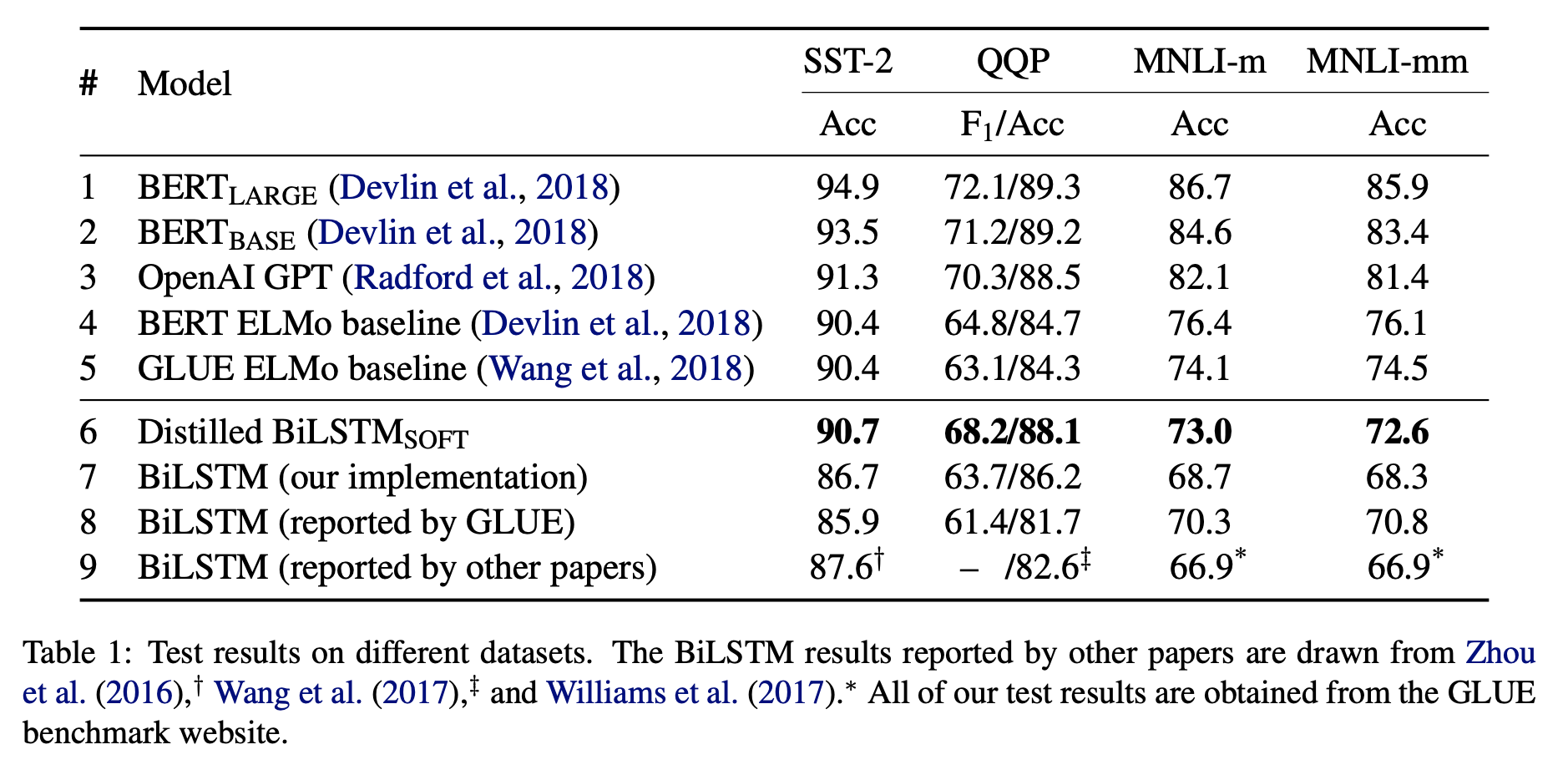
BERT是很好的模型,但是它的参数太大,网络结构太复杂。在很多没有GPU的环境下都无法部署。本文讲的是如何利用BERT构造更好的小的逻辑回归模型来代替原始BERT模型,可以放入生产环境中,以节约资源。
网站启用HTTPS必须制作证书,而证书的制作需要定期更新。这里介绍了Certbot证书自动生成工具和自动更新的方法。并描述了Tomcat如何配置pem证书。
当数据量达到一定程度,单机的处理能力会无法达到性能的要求,采用并行计算,并利用多台服务器进行分布式处理可能会提升数据处理的速度,达到性能要求。然而如果使用不当,并行处理可能并不会提升处理的速度。这篇博客介绍了Dask中关于并行处理的一些效率方面的建议,尽管是针对Dask的说明,但对于所有的并行处理来说都是适用的。
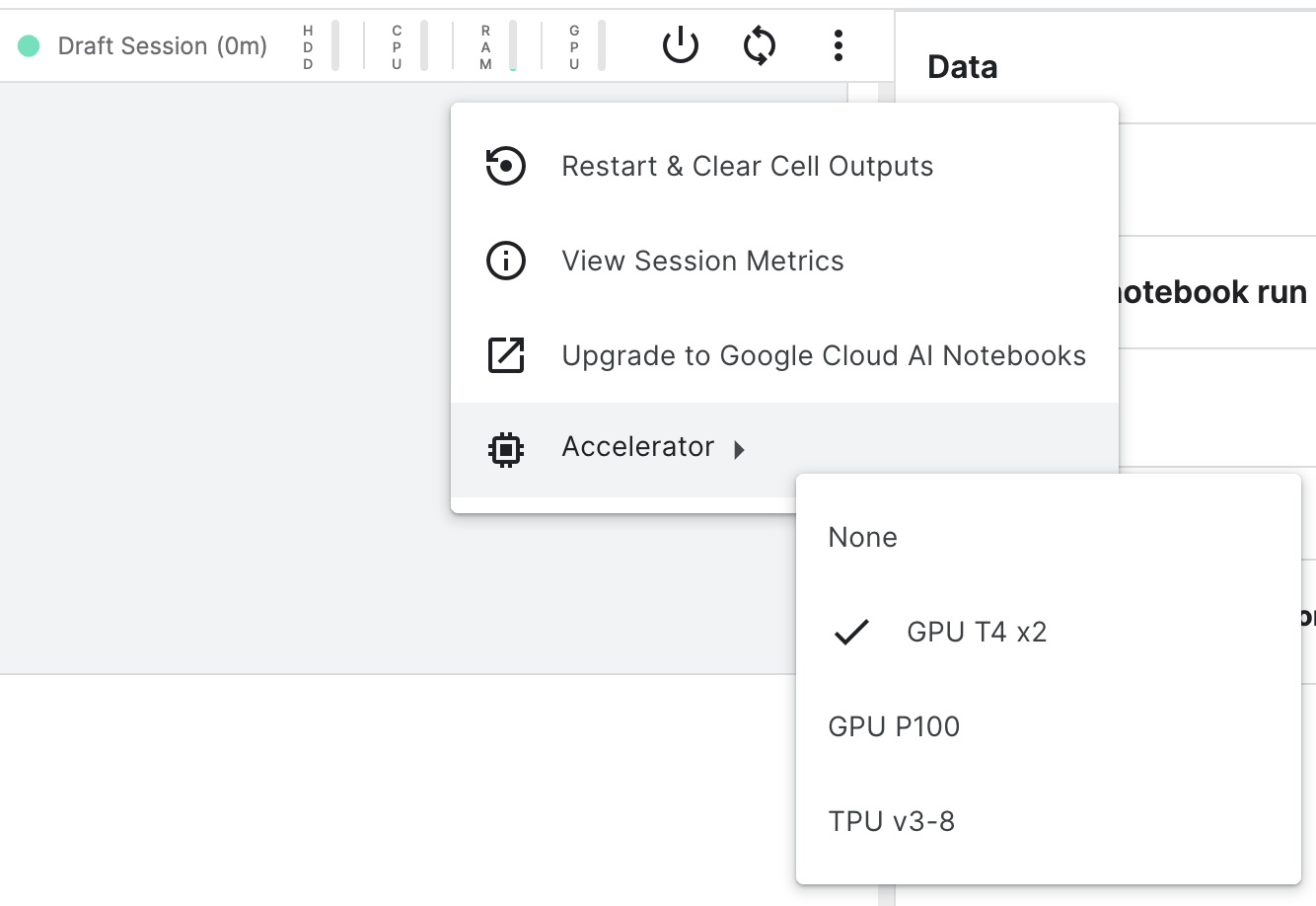
Kaggle是机器学习竞赛平台当之无愧的老大,除了提供了平台让企业和研究机构发布机器学习相关竞赛来让大家竞技和交流以外,他们还提供了免费的编程平台让大家使用免费的GPU和内存来训练模型和测试模型效果。而昨天,Kaggle升级了这些免费资源服务。
OpenAI在其官方GitHub上公开了一个最新的开源Python库:tiktoken,这个库主要是用力做字节对编码的。相比较HuggingFace的tokenizer,其速度提升了好几倍。

ChatGPT是最近半年多全球最火的产品。去年11月底发布之后,ChatGPT仅仅2个月时间就收获了1亿的月活。尽管在前几个月,ChatGPT是一枝独秀的存在,几乎没有任何可以与其竞争的产品与服务。然而在2023年7月份快结束的今天,市场上已经有相当多优秀的产品可供大家使用。

SQLCoder 是 Defog 团队推出的一款前沿的语言模型,专门用于将自然语言问题转化为 SQL 查询。这是一个拥有150亿参数的模型,其性能略微超过了 gpt-3.5-turbo 在自然语言到 SQL 生成任务上,并且显著地超越了所有流行的开源模型。更令人震惊的是,尽管 SQLCoder 的大小只有 text-davinci-003 的十分之一,但其性能却远超后者。
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
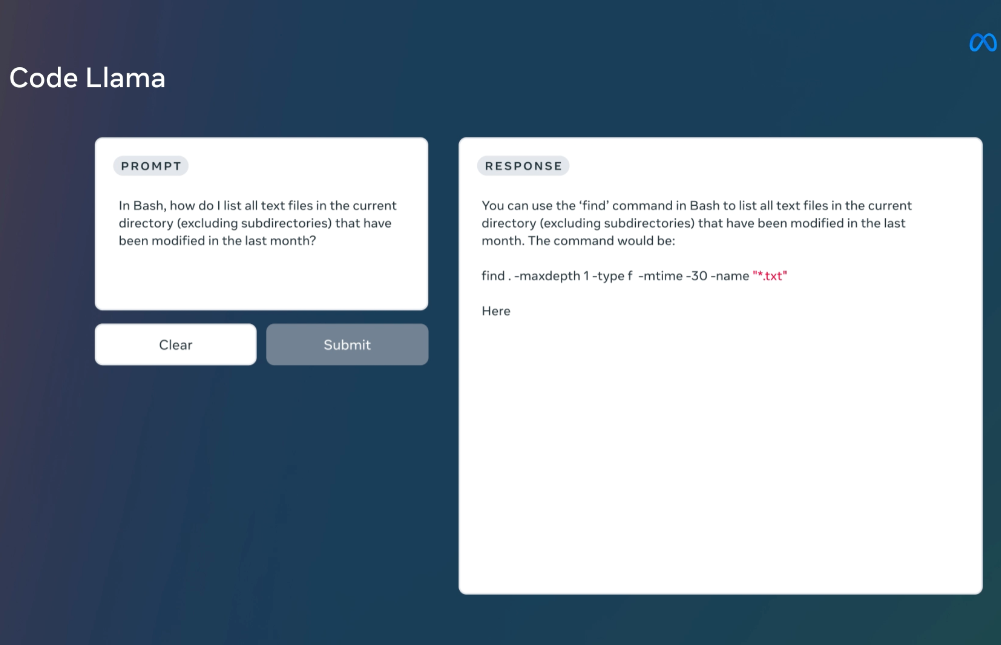
MetaAI发布的LLaMA系列开源大语言模型已经是开源大模型领域最重要的力量了。相当多的所谓开源大模型都是基于这个模型微调得到。在上个月,LLaMA2发布,吸引了全球非常多的关注,也有相当多的后续模型基于LLaMA2进行优化。而今天MetaAI再次开源全新的编程大模型——CodeLLaMA系列,这是MetaAI第一次发布编程大模型,本次发布的CodeLLaMA共有9个版本,分别是CodeLLaMA系列、针对Python优化的CodeLLaMA-Python系列和针对指令优化的CodeLLaMA-Inst
今日推荐
如何提高大语言模型作为Agent的能力?清华大学与智谱AI推出AgentTuning方案
MySQL8授权用户远程连接失败,提示ERROR 1410 (42000): You are not allowed to create a user with GRANT
使用kaggle房价预测的实例说明预测算法中OneHotEncoder、LabelEncoder与OrdinalEncoder的使用及其差异
ChatGPT官方代码解释器插件Code-Interpreter大揭秘:Code-Interpreter背后都有什么(执行环境、硬件资源、包含的Python库等)?
好消息!吴恩达再发大模型精品课程:Generative AI with Large Language Models,一个面向中级人员的生成式AI课程
Scrapy网络爬虫实战[保存为Json文件及存储到mysql数据库]
HuggingFace过去七天最流行的AI模型一览——预训练大模型绝对王者