
统计、机器学习与编程知识的原创博客
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
最新博客
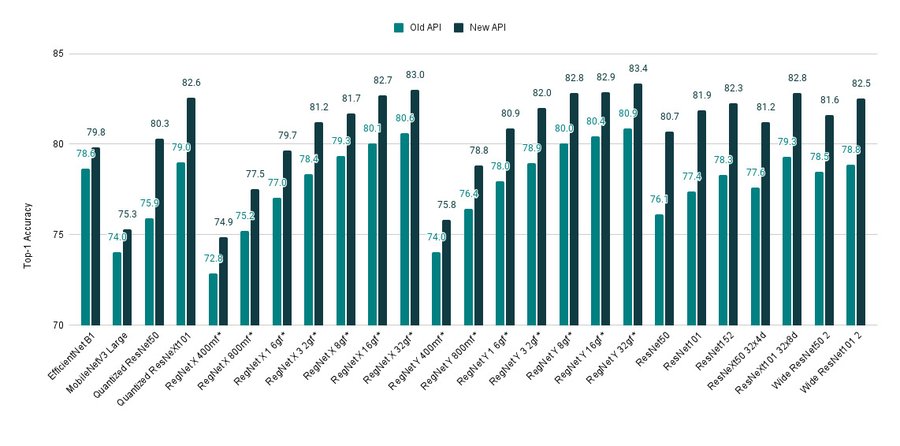
TorchVision最新0.13版本发布!
PyTorch最新的1.12版本已经在前天发布。而其中TorchVision是基于PyTorch框架开发的面向CV解决方案的一个PyThon库,其最主要的特点是包含了很多流行的数据集、模型架构以及预训练模型等。本次也随着PyTorch1.12的发布更新到了v0.13。此次发布包含几个非常好的提升,值得大家关注。
突破英特尔CPU+英伟达GPU的大模型训练硬件组合:苹果与AMD都有新进展!
大语言模型的训练和微调的硬件资源要求很高。现行主流的大模型训练硬件一般采用英特尔的CPU+英伟达的GPU进行。主要原因在于二者提供了符合大模型训练所需的计算架构和底层的加速库。但是,最近苹果M2 Ultra和AMD的显卡进展让我们看到了一些新的希望。

让大模型支持更长的上下文的方法哪个更好?训练支持更长上下文的模型还是基于检索增强?
在大语言模型中,上下文长度是指模型可以考虑的输入数据的数量。更长的上下文在大语言模型的实际应用中有非常重要的价值。当前,让大语言模型支持更长的上下文有两种常用的方法,一种是训练支持更长上下文长度的模型,扩展模型的输入,另外一种是检索增强生成的方法(Retrieval Augmentation Generation,RAG)。但二者应该如何选择,这是一个很少能直接比较的问题。为此,英伟达(Nvidia)的研究人员做了一个详细的比较。
博客转移
新浪博客转入
Google发布面试辅助工具Interview Warmup帮助我们理解谷歌面试内容
最近,谷歌发布了一项新的工具:Google Interview Warmup,让你练习回答由行业专家选定的问题,并使用机器学习来转录你的答案,帮助你发现改进面试的回答。

2022年9月份最火的10个AI研究——基于GitHub的Star数量排序
九月份刚过去,GitHub上最火的AI研究排序出炉。这是根据9月份GitHub上创建的新的AI研究相关的项目排序,根据Star的数量来的。都是AI各大领域比较受欢迎和重要的项目。

重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口
此前,OpenAI的CEO说今年等算力不那么紧张的时候就可以让大家微调OpenAI的GPT模型,现在这个功能已经发布了!OpenAI发布了GPT-3.5 Turbo的微调接口,允许大家用自己的数据微调GPT-3.5模型!

PandasTutor——一个用于可视化pandas操作的神器
pandas是Python中一个非常重要的分析工具,在数据处理方面应用非常广泛。但是,也是因为pandas包含的操作很多,所以初学者很多时候也不能特别能理解这些操作。 为了让初学者能够充分理解pandas中的操作,Pandas Tutor将pandas的操作变成可视化的过程,让我们充分理解这个过程。
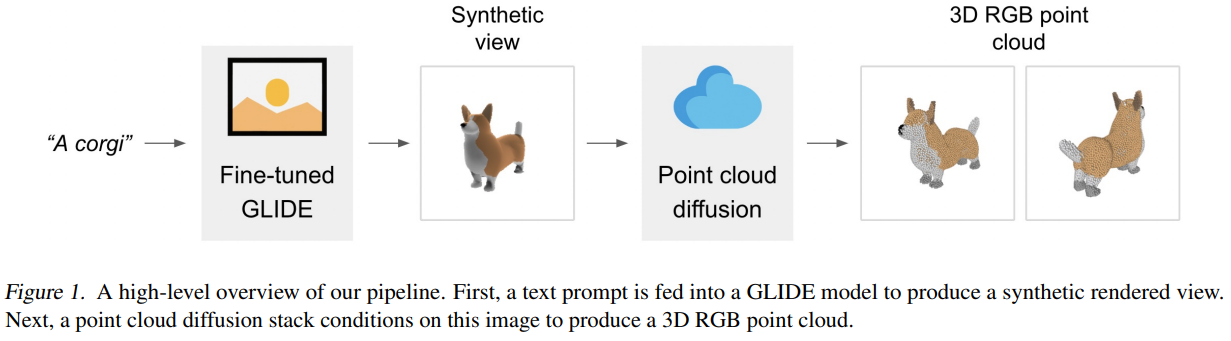
OpenAI开源最新的3D物体生成预训练模型——Point-E
三维物体的生成(3D)其实是AR/VR领域一个非常重要的技术。但是,受限于算力和现有模型的限制,三维物体的生成相比较图像生成来说效率太低。目前,最好的图像生成模型在几秒钟就可以根据文字生成图像结果,但是3D物体的生成通常需要多个GPU小时才可以生成一个对象。为此,OpenAI在今天开源了一个速度极快的3D物体生成模型——Point-E,需要注意的是,这是今年来OpenAI罕见的源代码和预训练结果都开源的一个模型。

你成功啦!!!
模拟登陆

OpenAI发布新一代向量大模型,接口已经更新到text-embedding-3-large,embedding长度升级,价格最高下降5倍!
决定向量检索准确性的核心是向量大模型的能力,即文本转成embedding向量是否准确。今天,OpenAI宣布了他们第三代向量大模型text-embedding,模型能力增强的同时价格下降!
可能是史上最强大的AI Agent!OpenAI重磅更新:整合了多模态、外部访问、数据分析后的GPT-4更像是AI Agent了!
此前OpenAI的ChatGPT Plus版本为GPT-4模型提供了多个强大的插件供大家使用,包括基于Bing的带网络浏览的Browse、文本生成图片的DALL·E3、高级数据分析功能等。就在几个小时前,OpenAI的部分用户收到了官方的一个非常重磅的更新,即上传任意文档的分析以及整合了所有工具后的GPT-4!这个功能被称为GPT-4(All Tools)!这个工具可以在一次对话中自主选择调用多个不同工具完成用户的输入指令,非常接近AI Agent形态!
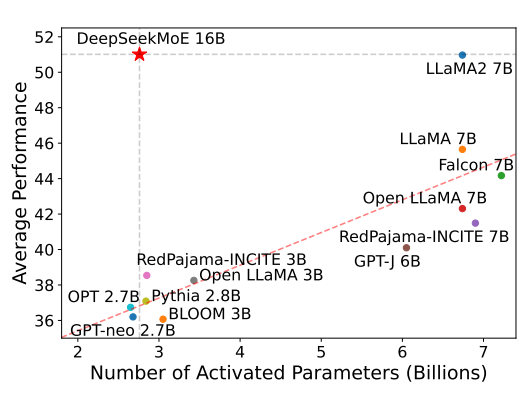
DeepSeekAI开源国产第一个基于混合专家技术的大模型:DeepSeekMoE-16B,未来还有1450亿参数的MoE大模型
混合专家(Mixture of Experts)是大模型一种技术,这个技术将大模型划分为不同的子专家模型,每次推理只选择部分专家网络进行推理,在降低成本的同时保证模型的效果。此前Mistral开源的Mixtral-8×7B-MoE大模型被证明效果很好,推理速度很棒。而幻方量化旗下的DeepSeek刚刚开源了可能是国产第一个MoE技术的大模型,DeepSeek-MoE 16B。
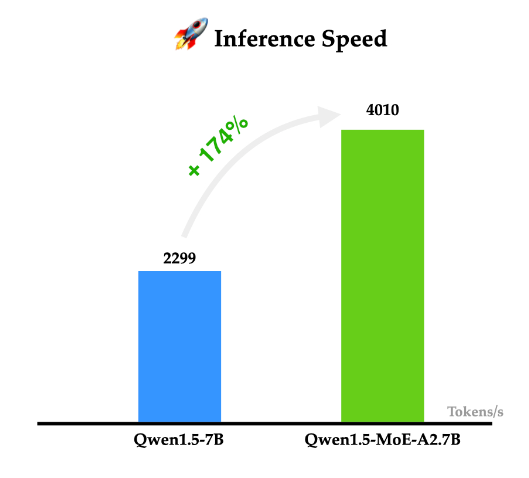
重磅!阿里巴巴开源自家首个MoE技术大模型:Qwen1.5-MoE-A2.7B,性能约等于70亿参数规模的大模型Mistral-7B
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
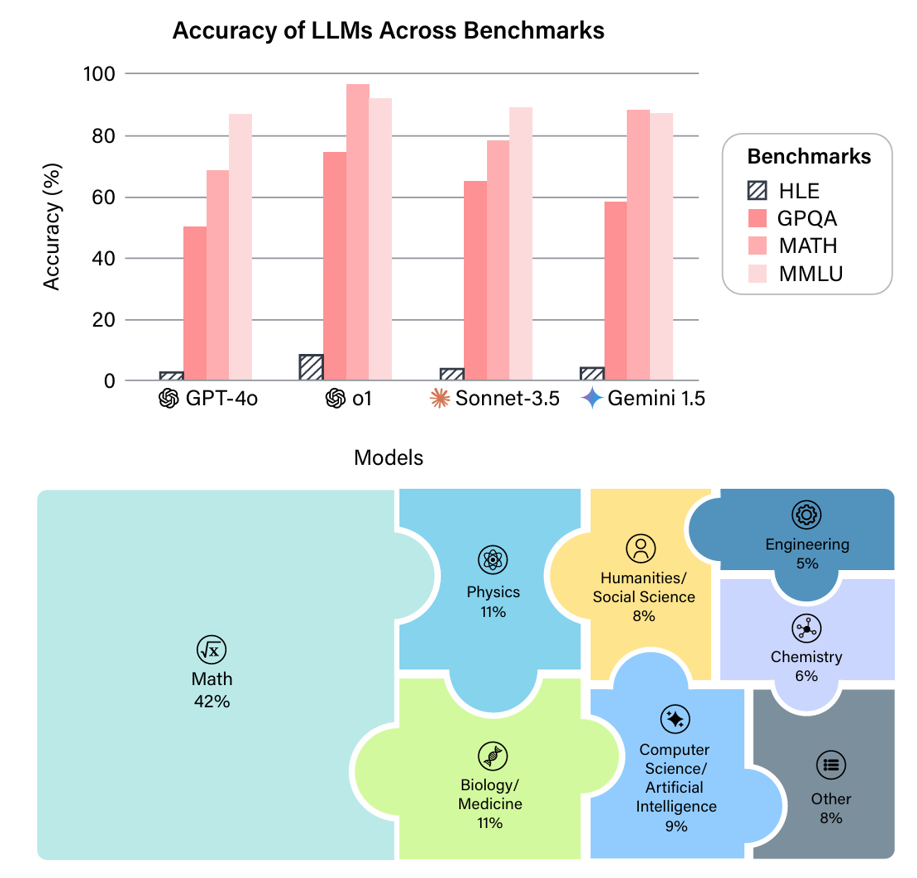
大模型评测的新标杆:超高难度的“Humanity’s Last Exam”(HLE)介绍
近年来,大语言模型(LLM)的能力飞速提升,但评测基准的发展却显得滞后。以广泛使用的MMLU(大规模多任务语言理解)为例,GPT-4、Claude等前沿模型已能在其90%以上的问题上取得高分。这种“评测饱和”现象导致研究者难以精准衡量模型在尖端知识领域的真实能力。为此,Safety for AI和Scale AI的研究人员推出了Humanity’s Last Exam大模型评测基准。这是一个全新的评测基准,旨在成为大模型“闭卷学术评测的终极考验”。

Python生态系统中5个NLP工具库
Python是目前最流行的编程语言,也是开放生态做得最好的编程语言之一。大多数深度学习框架、机器学习的框架都有很优秀的Python版本。这篇博客主要为大家介绍5个python生态系中解决NLP任务的框架。