
Scale AI 发布 SWE-Bench Pro 评测:AI 软件工程代理的新基准
Scale AI 于 2025 年 9 月 21 日发布了 SWE-Bench Pro,这是一个针对 AI 代理在软件工程任务上的评估基准。该基准包含 1,865 个问题,来源于 41 个活跃维护的代码仓库,聚焦企业级复杂任务。现有模型在该基准上的表现显示出显著差距,顶级模型的通过率低于 25%,而最近的榜单更新显示部分模型已超过 40%。这一发布旨在推动 AI 在长时程软件开发中的应用研究。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Scale AI 于 2025 年 9 月 21 日发布了 SWE-Bench Pro,这是一个针对 AI 代理在软件工程任务上的评估基准。该基准包含 1,865 个问题,来源于 41 个活跃维护的代码仓库,聚焦企业级复杂任务。现有模型在该基准上的表现显示出显著差距,顶级模型的通过率低于 25%,而最近的榜单更新显示部分模型已超过 40%。这一发布旨在推动 AI 在长时程软件开发中的应用研究。

DocVQA是一个针对文档图像的视觉问答基准数据集。该数据集包含50,000个问题,这些问题基于12,767张文档图像构建而成。数据集旨在评估模型在提取和理解文档内容方面的能力,特别是当问题涉及布局、表格和文本时。基准通过提供标注的问答对,支持模型在真实文档场景下的测试。
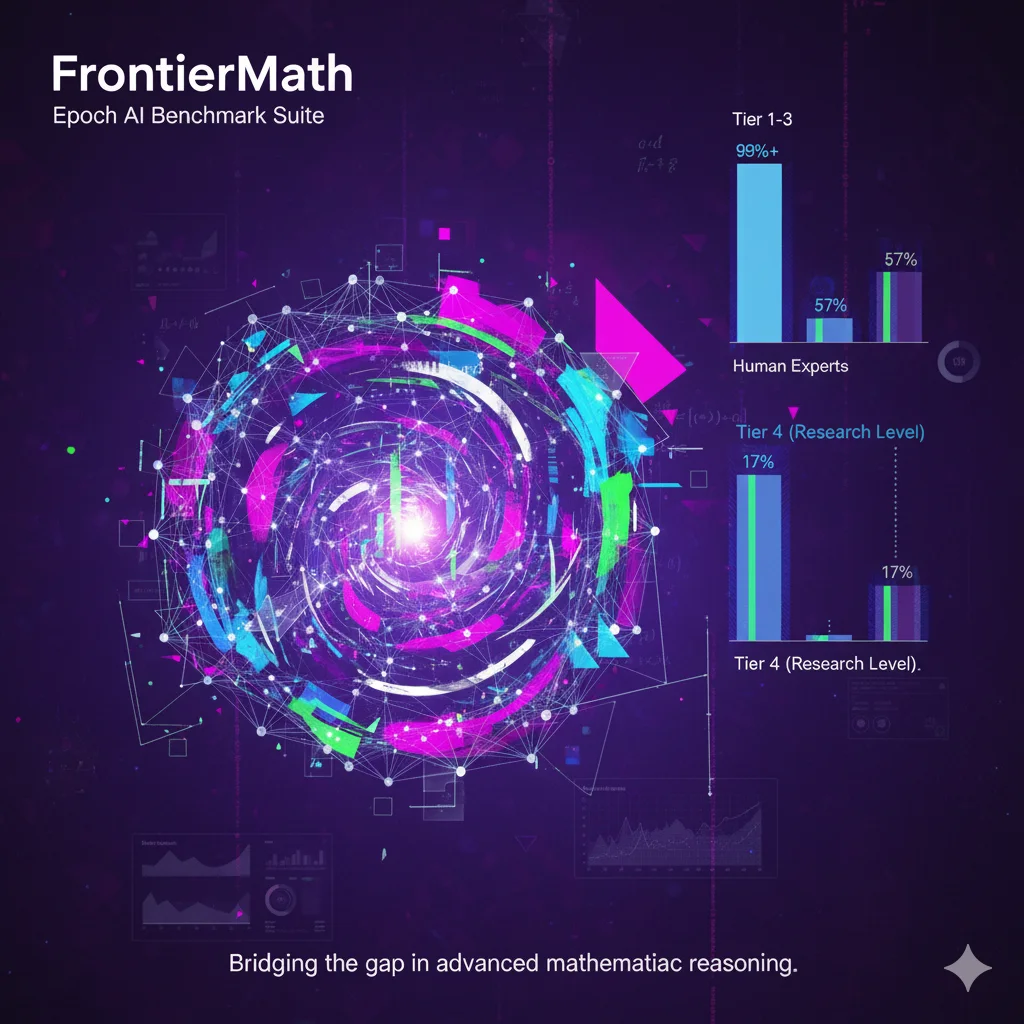
FrontierMath是一个由Epoch AI开发的基准测试套件,包含数百个原创的数学问题。这些问题由专家数学家设计和审核,覆盖现代数学的主要分支,如数论、实分析、代数几何和范畴论。每个问题通常需要相关领域研究人员投入数小时至数天的努力来解决。基准采用未发表的问题和自动化验证机制,以减少数据污染风险并确保评估可靠性。当前最先进的AI模型在该基准上的解决率低于2%,这反映出AI在处理专家级数学推理时的局限性。该基准旨在为AI系统向研究级数学能力进步提供量化指标。
BrowseComp是一个用于评估AI代理网页浏览能力的基准测试。它包含1266个问题,这些问题要求代理在互联网上导航以查找难以发现的信息。该基准关注代理在处理多跳事实和纠缠信息时的持久性和创造性。OpenAI于2025年4月10日发布此基准,并将其开源在GitHub仓库中。
IMO-Bench 是 Google DeepMind 开发的一套基准测试套件,针对国际数学奥林匹克(IMO)水平的数学问题设计,用于评估大型语言模型在数学推理方面的能力。该基准包括三个子基准:AnswerBench、ProofBench 和 GradingBench,涵盖从短答案验证到完整证明生成和评分的全过程。发布于 2025 年 11 月,该基准通过专家审核的问题集,帮助模型实现 IMO 金牌级别的性能,并提供自动评分机制以支持大规模评估。

LiveBench是一个针对大型语言模型(LLM)的基准测试框架。该框架通过每月更新基于近期来源的问题集来评估模型性能。问题集涵盖数学、编码、推理、语言理解、指令遵循和数据分析等类别。LiveBench采用自动评分机制,确保评估基于客观事实而非主观判断。基准测试的总问题数量约为1000个,每月替换约1/6的问题,以维持测试的有效性。
本文介绍 Terminal-Bench 的设计理念,深入讲解 core、Terminal-Bench Hard 与最新 Terminal-Bench 2.0 的区别,帮助开发者选择合适的 AI 终端评测基准。